【论文笔记】The graph neural network model
文章目录2009-IEEE-The graph neural network model概要状态更新与输出不动点理论具体实现压缩映射损失函数实验总结2009-IEEE-The graph neural network model概要 在科学与工程的许多领域中的数据的潜在关系都可以用图来表示,比如计算机视觉,分子化学,分子生物学,模式识别,数据挖掘以及自然语言处理。本论文提出了一种新的神经网络模型称
2009-IEEE-The graph neural network model
概要
在科学与工程的许多领域中的数据的潜在关系都可以用图来表示,比如计算机视觉,分子化学,分子生物学,模式识别,数据挖掘以及自然语言处理。本论文提出了一种新的神经网络模型称为图神经网络模型,用来处理以图来表示的数据。
本文中所提到的图均指图论中的图(Graph)。它是一种由若干个结点(Node)及连接两个结点的边(Edge)所构成的图形,用于刻画不同结点之间的关系:
状态更新与输出
它的理论基础是不动点理论。给定一张图
G
G
G,每个结点都有其自己的特征(feature), 本文中用
l
v
l_v
lv表示结点v的特征;连接两个结点的边也有自己的特征,本文中用
l
(
v
,
u
)
,
l
(
v
,
u
)
l_{(v,u)},l_{(v,u)}
l(v,u),l(v,u)表示结点
v
v
v与结点
u
u
u之间边的特征;GNN的学习目标是获得每个结点的图感知的隐藏状态
x
v
x_v
xv(state embedding),这就意味着:对于每个节点,它的隐藏状态包含了来自邻居节点的信息。那么,如何让每个结点都感知到图上其他的结点呢?GNN通过迭代式更新所有结点的隐藏状态来实现,在
t
+
1
t+1
t+1时刻,结点
v
v
v的隐藏状态按照如下方式更新:
x
v
t
+
1
=
f
W
(
l
v
,
l
c
o
[
v
]
,
x
n
e
[
v
]
t
,
l
n
e
[
v
]
)
x_v^{t+1} = f_{_W}(l_v,l_{co[v]},x^t_{ne[v]},l_{ne[v]})
xvt+1=fW(lv,lco[v],xne[v]t,lne[v])
f f f: 隐藏状态的状态更新函数
l c o [ v ] l_co[v] lco[v]: 与节点v相邻的边的特征
x n e [ v ] t x^t_{ne[v]} xne[v]t: 邻居节点在t时刻的隐藏状态
l n e [ v ] l_{ne[v]} lne[v]: 节点v的邻居节点的特征
下图为论文中给出的一个计算节点 l 1 l_1 l1隐藏状态的例子:
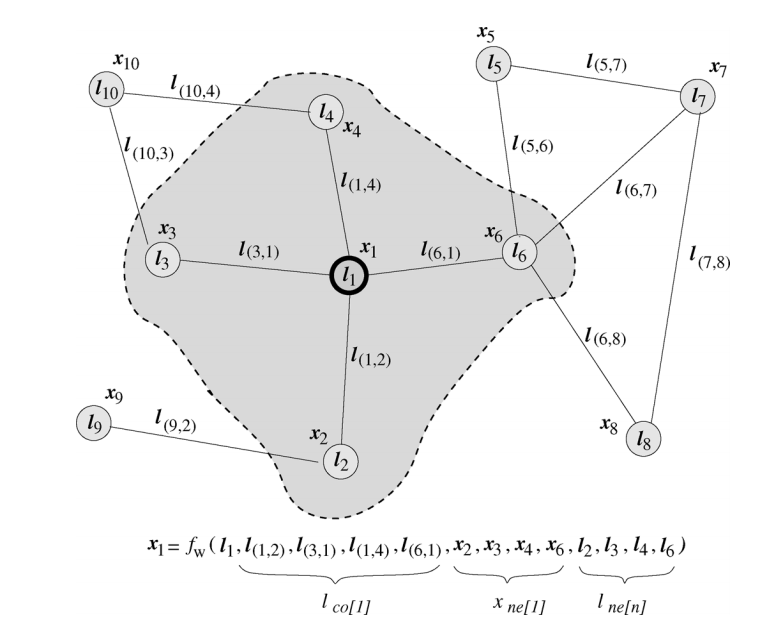
假设结点 l 1 l_1 l1为中心结点,其隐藏状态的更新函数如上图所示。这个更新公式表达的思想自然又贴切:不断地利用当前时刻邻居结点的隐藏状态作为部分输入来生成下一时刻中心结点的隐藏状态,直到每个结点的隐藏状态变化幅度很小,整个图的信息流动趋于平稳。至此,每个结点都“知晓”了其邻居的信息。状态更新公式仅描述了如何获取每个结点的隐藏状态,除它以外,我们还需要另外一个函数 g g g 来描述如何适应下游任务。举个例子,给定一个社交网络,一个可能的下游任务是判断各个结点是否为水军账号。
o
v
=
g
W
(
x
v
,
l
v
)
o_v = g_{_W}(x_v,lv)
ov=gW(xv,lv)
在原论文中,
g
g
g 又被称为局部输出函数(local output function),与
f
f
f 类似,
g
g
g 也可以由一个神经网络来表达,它也是一个全局共享的函数。
那么,对于图:

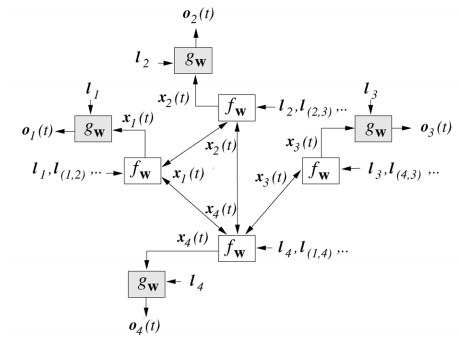
整个流程可以用下面这张图表达:
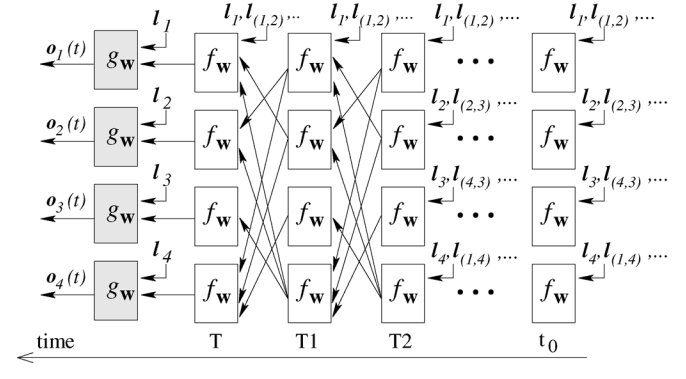
仔细观察两个时刻之间的连线,它与图的连线密切相关。在 T 1 T1 T1 时刻,结点 1 的状态接受来自结点 2 与结点 4 的上一时刻的隐藏状态,因为结点 1 与结点 2,4相邻。直到 T T T 时刻,各个结点隐藏状态收敛,每个结点后面接一个 g g g 即可得到该结点的输出 o o o。
对于不同的图来说,其收敛的时刻可能不同,因为收敛是通过两个时刻的隐藏状态的
p
−
范
数
p-范数
p−范数的差值是否小于某个阈值
ϵ
\epsilon
ϵ来判断的,比如通过二范数:
∣
∣
x
t
+
1
∣
∣
2
−
∣
∣
x
t
∣
∣
2
<
ϵ
||x^{t+1}||_2 - ||x^t||_2 < \epsilon
∣∣xt+1∣∣2−∣∣xt∣∣2<ϵ
不动点理论
GNN的理论基础是不动点(the fixed point)理论,这里的不动点理论专指巴拿赫不动点定理(Banach’s Fixed Point Theorem)。首先我们用
F
F
F 表示若干个
f
f
f 堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
x
t
+
1
=
F
(
x
t
,
l
)
x^{t+1} = F(x^t,l)
xt+1=F(xt,l)
不动点理论值得是,不论
x
0
x^0
x0是什么,只要
F
F
F是一个压缩映射(contraction map),
x
0
x^0
x0经过不断迭代终会收敛到一个固定的不动点。如下是对压缩映射的一个直观解释:
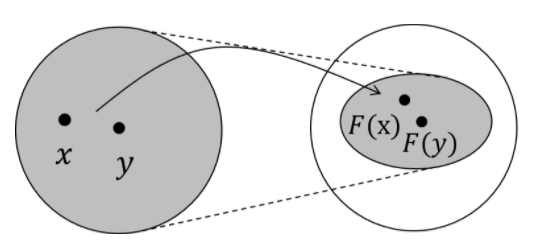
上图的箭头就是映射 F F F,任意两个点 x , y x,y x,y在经过 F F F这个映射后,分别变成了 F ( x ) , F ( y ) F(x),F(y) F(x),F(y)。压缩映射就是指, d ( F ( x ) , F ( y ) ) ≤ c d ( x , y ) , 0 ≤ c < 1 d(F(x),F(y))≤cd(x,y),0≤c<1 d(F(x),F(y))≤cd(x,y),0≤c<1。也就是说,经过 F F F 变换后的新空间一定比原先的空间要小,原先的空间被压缩了。想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。
具体实现
压缩映射
上面提到,
f
f
f 可以用一个简单的前馈神经网络来实现。一种简单的实现方法是将其参数简单地拼接在一起,再经过前馈网络后做一次简单的加和:
x
v
t
+
1
=
f
W
(
l
v
,
l
c
o
[
v
]
,
x
n
e
[
v
]
t
,
l
n
e
[
v
]
)
=
∑
u
∈
n
e
[
v
]
F
N
N
(
[
l
v
;
l
(
u
,
v
)
;
x
u
t
;
l
u
]
)
x_v^{t+1} = f_W(l_v,l_{co[v]},x^t_{ne[v]},l_{ne[v]}) \\ = \sum_{u\in ne[v]} FNN([l_v;l_{(u,v)};x_u^t;l_u])
xvt+1=fW(lv,lco[v],xne[v]t,lne[v])=u∈ne[v]∑FNN([lv;l(u,v);xut;lu])
雅可比矩阵:
设 f : R n → R m f:R_n \rightarrow R_m f:Rn→Rm 是一个函数,他的输入向量 x ∈ R n x\in R_n x∈Rn, 输出向量是 y = f ( x ) ∈ R m y=f(x)\in R_m y=f(x)∈Rm:
KaTeX parse error: Undefined control sequence: \ at position 84: …_n) \\ \dots \\\̲ ̲y_m = f_m(x_1,x…
那么雅可比矩阵是一个 m × n m\times n m×n矩阵:
J = [ ∂ f ∂ x 1 … ∂ f ∂ x n ] = [ ∂ f 1 ∂ x 1 … ∂ f 1 ∂ x n ⋮ … ⋮ ∂ f m ∂ x 1 … ∂ f m ∂ x n ] J = \begin{bmatrix} \frac{\partial f}{\partial x_1} \dots \frac{\partial f}{\partial x_n} \end{bmatrix} = \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \dots & \frac{\partial f_1}{\partial x_n} \\ \vdots & \dots & \vdots \\ \frac{\partial f_m}{\partial x_1} & \dots & \frac{\partial f_m}{\partial x_n} \end{bmatrix} J=[∂x1∂f…∂xn∂f]=⎣⎢⎡∂x1∂f1⋮∂x1∂fm………∂xn∂f1⋮∂xn∂fm⎦⎥⎤
由于矩阵描述了向量空间中的运动------变换,而雅可比矩阵看作是将点 ( x 1 , . . . , x n ) (x_1,...,x_n) (x1,...,xn)转化到点 ( y 1 , . . . , y 2 ) (y_1,...,y_2) (y1,...,y2), 或者说是从一个n维的欧式扣你就按转换到m维的欧式空间。
接下来,为了保证
f
f
f是一个压缩映射,可以通过一个对雅可比矩阵的惩罚项来显示
f
f
f对
x
x
x的偏导数矩阵的大小。这是根据在代数中
f
f
f为压缩映射的等价条件是
f
f
f的梯度要小于一为基础,可以根据不动点定理证明如下:
∣
∣
F
(
x
)
−
F
(
u
)
∣
∣
≤
c
∣
∣
x
−
y
∣
∣
,
0
≤
c
<
1
∣
∣
F
(
x
)
−
F
(
y
)
∣
∣
∣
∣
x
−
y
∣
∣
≤
c
∣
∣
F
(
x
)
−
F
(
x
−
Δ
x
)
∣
∣
∣
∣
Δ
x
∣
∣
≤
c
∣
∣
F
′
(
x
)
∣
∣
=
∣
∣
∂
F
(
x
)
∂
x
∣
∣
≤
c
||F(x) - F(u)||\le c||x-y||,0\le c < 1 \\ \frac{||F(x)-F(y)||}{||x-y||} \le c \\ \frac{||F(x)-F(x-\Delta x)||}{||\Delta x||} \le c \\ ||F'(x)|| = ||\frac{\partial F(x)}{\partial x}|| \le c
∣∣F(x)−F(u)∣∣≤c∣∣x−y∣∣,0≤c<1∣∣x−y∣∣∣∣F(x)−F(y)∣∣≤c∣∣Δx∣∣∣∣F(x)−F(x−Δx)∣∣≤c∣∣F′(x)∣∣=∣∣∂x∂F(x)∣∣≤c
根据拉格朗日乘子法,将有约束问题变成带罚项的无约束优化问题,训练的目标可以表示成如下形式:
J
=
L
o
s
s
+
λ
⋅
m
a
x
(
∣
∣
∂
F
N
N
∣
∣
∣
∣
∂
x
∣
∣
−
c
)
,
c
∈
(
0
,
1
)
J = Loss + \lambda \cdot max(\frac{||\partial FNN||}{||\partial x||}-c),c\in (0,1)
J=Loss+λ⋅max(∣∣∂x∣∣∣∣∂FNN∣∣−c),c∈(0,1)
λ \lambda λ: 超参数
m a x ( ) max() max(): 雅可比矩阵的罚项
损失函数
对于不同的问题,有不同的损失函数。以社交网络举例,虽然每个结点都会有隐藏状态以及输出,但并不是每个结点都会有监督信号(Supervision)。比如说,社交网络中只有部分用户被明确标记了是否为水军账号,这就构成了一个典型的结点二分类问题。
那么很自然地,模型的损失即通过这些有监督信号的结点得到。假设监督结点一共有 p p p 个,模型损失可以形式化为:
L
o
s
s
=
∑
i
=
1
p
(
t
i
−
o
i
)
Loss = \sum_{i=1}^{p} (t_i-o_i)
Loss=i=1∑p(ti−oi)
那么,模型如何学习呢?根据前向传播计算损失的过程,不难推出反向传播计算梯度的过程。在前向传播中,模型:
- 调用 f f f若干次,比如 T n T_n Tn次,直到 x v T n x^{T_n}_v xvTn 收敛。
- 此时每个结点的隐藏状态接近不动点的解。
- 对于有监督信号的结点,将其隐藏状态通过 g W g_{_W} gW 得到输出,进而算出模型的损失。
根据上面的过程,在反向传播时,我们可以直接求出 f f f 和 g g g 对最终的隐藏状态 x v T n x^{T_n}_v xvTn 的梯度。然而,因为模型递归调用了 f f f 若干次,为计算 f f f 和 g g g 对最初的隐藏状态 x v 0 x_v^0 xv0 的梯度,我们需要同样递归式/迭代式地计算 T n T_n Tn 次梯度。最终得到的梯度即为 f f f 和 g g g 对 x v 0 x_v^0 xv0 的梯度,然后该梯度用于更新模型的参数。这个算法就是 Almeida-Pineda 算法。
实验
论文中举了A、B、C三个具体应用的实验,我们取第二个来分析。实验中,数据集的每个分子都被转换成一个图形,其中节点代表原子和边代表AB。平均每个分子中节点数为大约26。节点标签包含原子类型,其能量状态和全局属性AB,C和PS。在每个图中,只有一个受监管的节点,AB描述中的第一个原子(图6)。如果分子是致突变的则期望的输出为1,否则为 -1。就是一个二分类问题。
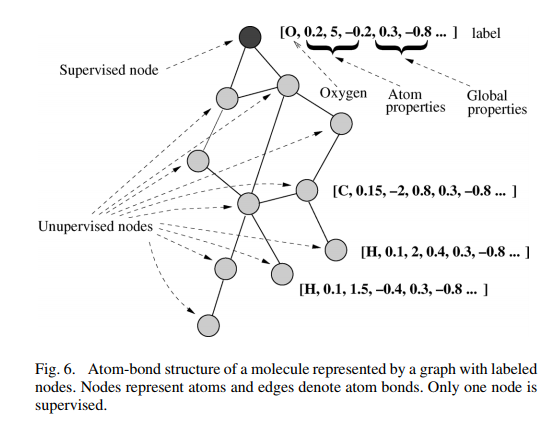
在不断迭代得到根结点氧原子收敛的隐藏状态后,在上面接一个前馈神经网络作为输出层(即 g g g 函数),就可以对整个化合物进行二分类了。
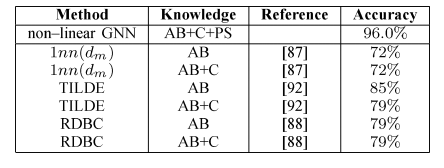
实验结果如下:


总结
随着机器学习、深度学习的发展,语音、图像、自然语言处理逐渐取得了很大的突破,然而语音、图像、文本都是很简单的序列或者网格数据,是很结构化的数据,深度学习很善于处理该种类型的数据。然而现实生活中有许多事务并不能被简单地表示成序列或网格数据。如社交网络,交通网络,生物/化学分子结构等。因为要对这种可被表示为图结构的信息进行学习建模,本论文提出的图神经网络模型很好地解决了这一问题,并且在子图匹配、化合物分子分类、网页排名等领域得到了更好的实验结果。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)