
可解释性机器学习_Feature Importance、Permutation Importance、SHAP
本文讲的都是建模后的可解释性方法。建模之前可解释性方法或者使用本身具备可解释性的模型都不在本文范围内~哪些特征在模型看到是最重要的?关于某一条记录的预测,每一个特征是如何影响到最终的预测结果的?从大量的记录整体来考虑,每一个特征如何影响模型的预测的?为什么这些解释信息是有价值的调试模型用指导工程师做特征工程指导数据采集的方向指导人们做决策建立模型和人之间的信任本文主要讲三种方法:特征重要性(Fea
本文讲的都是建模后的可解释性方法。建模之前可解释性方法或者使用本身具备可解释性的模型都不在本文范围内~
模型通常会考虑以下问题:
- 哪些特征在模型看到是最重要的?
- 从大量的记录整体来考虑,每一个特征如何影响模型的预测的?
- 关于某一条记录的预测,每一个特征是如何影响到最终的预测结果的?
这就是可解释性机器学习需要解决的问题,也是他的价值所在:
- 可靠性
- 易于调试
- 启发特征工程思路
- 指导后续数据采集的方向
- 指导人为决策
- 建立模型和人之间的信任
主要类型
1、第一个分类是内置/内在可解释性以及事后可解释性。内置可解释性是将可解释模块嵌入到模型中,如说线性模型的权重、决策树的树结构。另外一种是事后可解释性,这是在模型训练结束后使用解释技术去解释模型。
2、第二种分类是特定于模型的解释和模型无关的解释,简单的说,特定于模型的解释这意味着必须将其应用到特定的模型体系结构中。而模型无关的解释意味着解释方法与所用模型无关联,这种解释方法应用范围广。
3、第三种分类是全局解释和局部解释。全局解释是解释模型的全局行为。局部解释是在单条数据或者说单个实例上的解释。
本文主要讲三种方法:
- 特征重要性(模型自带Feature Importance)
- Permutation Importance
- SHAP
当然,还有很多其他方法,部分依赖图(PDP)和个体条件期望图(ICE)、局部可解释不可知模型(LIME)、累积局部效应图(ALE)、RETAIN、逐层相关性传播(LRP)。本文只写了我接触到的一小部分哈,实际工作用到可在拓展学习。
1、特征重要性(Feature Importance)
- 特征重要性的作用 -> 快速的让你知道哪些因素是比较重要的,但是不能得到这个因素对模型结果的正负向影响,同时传统方法对交互效应的考量会有些欠缺。
- 如果想要知道哪些变量比较重要的话。可以通过模型的feature_importances_方法来获取特征重要性。例如xgboost的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。
- 计算方法是:Mean Decrease Impurity。思想:一个特征的意义在于降低预测目标的不确定性,能够更多的降低这种不确定性的特征就更重要。即特征重要性计算依据某个特征进行决策树分裂时,分裂前后的信息增益(基尼系数).
import pandas as pd
from sklearn.datasets import load_iris
import xgboost as xgb
iris = load_iris()
df = pd.DataFrame(iris.data,columns=iris.feature_names) #转化成DataFrame格式
target = iris.target
xgb_model = xgb.XGBClassifier()
clf = xgb_model.fit(df.values, target)
a=clf.feature_importances_
features = pd.DataFrame(sorted(zip(a,df.columns),reverse=True))

2、Permutation Importance
常规思路,很容易想到,在训练模型的时候可以直接输出特征重要性,但这个特征对整体的预测效果有多大影响?可以用Permutation Importance(排列重要性)进行计算。
PI思想:基于“置换检验”的思想对特征重要性进行检测,,一定是在model训练完成后,才可以计算的。简单来说,就是改变数据表格中某一列的数据的排列,保持其余特征不动,看其对预测精度的影响有多大。
计算步骤:
1、用上全部特征,训练一个模型。
2、验证集预测得到得分。
3、验证集的一个特征列的值进行随机打乱,预测得到得分。
4、将上述得分做差即可得到特征x1对预测的影响。
5、依次将每一列特征按上述方法做,得到每二个特征对预测的影响。
我们使用ELI5库可以进行Permutation Importance的计算。
ELI5是一个可以对各类机器学习模型进行可视化和调试Python库,并且针对各类模型都有统一的调用接口。
ELI5中原生支持了多种机器学习框架,并且也提供了解释黑盒模型的方式。
import eli5
from eli5.sklearn import permutationImportance
perm = PermutationImportance(xgb_model, random_state = 1).fit(df, target) # 实例化
eli5.show_weights(perm)
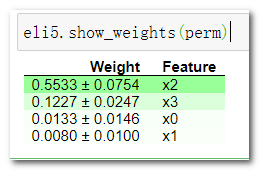
结果分析:
- 靠近上方的绿色特征,表示对模型预测较为重要的特征;
- 为了排除随机性,每一次 shuffle 都会进行多次,然后取结果的均值和标准差;
- ±后面的数字表示多次随机重排之间的差异值。
这个例子里,最重要的特征是第三个 ‘petal length (cm)’, 和feature_importances_输出结果一致。
3、SHAP(SHapley Additive exPlanation)
以上都是全局可解释性方法,那局部可解释性,即单个样本来看,模型给出的预测值和某些特征可能的关系,这就可以用到SHAP。当然shap也有全局可解释性哈,本文不介绍~
SHAP 属于模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAPbaseline value,包括Kernel Shap,Deep Shap和Tree Shap。这也是目前可解释机器学习在风控、金融中最实用的一个方法。
SHAP(SHapley Additive exPlanation)是Python开发的一个"模型解释"包,可以解释任何机器学习模型的输出。
import shap #Python的可解释机器学习库 pip install shap
shap.initjs() # notebook环境下,加载用于可视化的JS代码
#模型还是用之前训练的
#xgb_model = xgb.XGBClassifier()
#clf = xgb_model.fit(df.values, target)
#在SHAP中进行模型解释需要先创建一个explainer,
#SHAP支持很多类型的explainer(例如deep, gradient, kernel, linear, tree, sampling)
#我们先以tree为例,因为它支持常用的XGB、LGB、CatBoost等树集成算法。
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(df) # 传入特征矩阵,计算SHAP值
j = 60
y_base = explainer.expected_value
player_explainer = pd.DataFrame()
player_explainer['feature'] = df.columns
player_explainer['feature_value'] = df.iloc[j].values
player_explainer['shap_value'] = shap_values[j]
player_explainer

# 可视化一个prediction的解释 如果不想用JS,传入matplotlib=True
shap.force_plot(explainer_clf.expected_value[1], shap_values_clf[1][j], df.iloc[j,:])

结果分析:
base value:全体样本Shap平均值,模型在数据集上的输出均值0.5671;
f(x):当前样本的Shap输出值,模型在单个样本的输出值1.76;
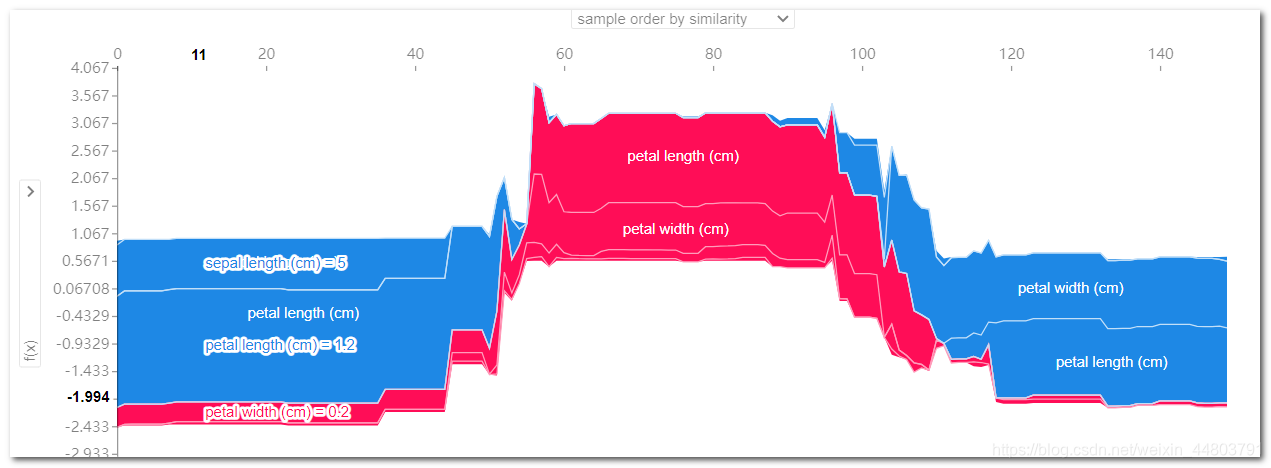
正向作用特征:petal length (cm)取值为3.5,petal length(cm)取值为1,具有正向影响;长度表示特征影响的程度。
反向作用的特征:sepal length (cm)取值为5,sepal width (cm) 取值为2,具有有负向影响。
引起预测降低的特征值是蓝色的,最大的影响源自 sepal length (cm)=5 的时候,但 petal length (cm)= 3.5 的值则对提高预测的值具有比较有意义的影响;所有特征共同作用下预测结果为1.76,计算公式为:0.5670767+3.51.423280+0.790364-50.906990-2.0*0.116189。
下面是全局解释,涉及不多,可自行查找资料学习哈~
#多个预测的解释
shap.force_plot(explainer.expected_value[1], shap_values[1], df) #鼠标可以放图上面显示具体数值
解释Output value(单个样本)和Base value(全体样本Shap平均值)的差异,以及差异是由哪些特征造成的。红色是起正向作用的特征,蓝色是起负向作用的特征。
#summary plot 为每个样本绘制其每个特征的SHAP值,这可以更好地理解整体模式,并允许发现预测异常值。
shap.summary_plot(shap_values, df)
整体特征重要性。

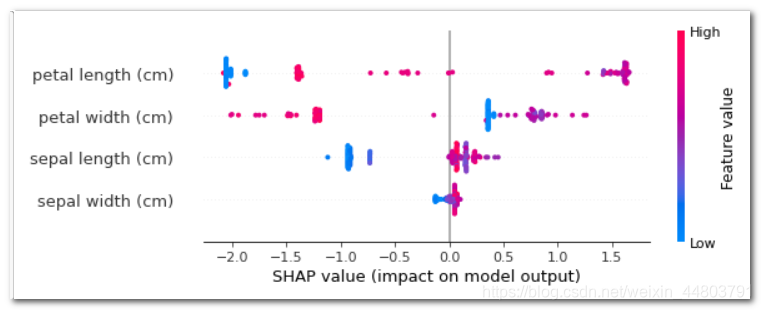
shap.summary_plot(shap_values_clf[1], df)
取值为1的情况。每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色表示特征值(红色高,蓝色低)。
- 每个点是一个样本(人),图片中包含所有样本
- X轴:样本按Shap值排序-
- Y轴:特征按Shap值排序
- 颜色:特征的数值越大,越红
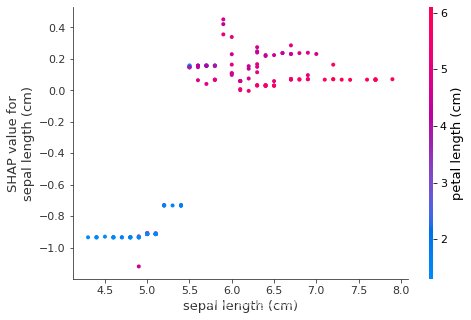
shap.dependence_plot('sepal length (cm)', shap_values_clf[1], df, interaction_index="petal length (cm)")
#排除所有特征的影响,描述age和capital_gain的关系
4、LIME(Local Interpretable Model-agnostic Explanations)
LIME方法把模型视作黑盒,并不需要重新训练模型。那什么是代理思想呢,首先对于原来的黑盒模型,放入输入数据,得到输出。而后我们用另一个模型,针对相同的输入数据,得到的输出为。现在我们让近似于,那就是说让新的模型去学习黑盒模型的行为。这里的黑盒模型可以是深度神经网络,而用来近似的模型是前文介绍的容易理解的简单模型,比如线性模型和决策树。因为黑盒模型和可解释的模型在数据集上表现很相似,我们想知道黑盒模型为什么要作出这样的决策,就可以去理解那些可解释的模型是怎么作出决策的,这就是代理思想。
但因为黑盒模型复杂性很高,比如深度神经网络,想用一个简单模型去完全拷贝深度网络的行为会很难。如图所示,对于一条弯曲的函数,想用一个线性函数去拟合这条拟合线是很困难的。但在局部,也就是某个数据点周围,函数行为可能是线性的,我们用一条线性函数去拟合局部行为完全是可以的,这就是LIME方法的思想。这里用到的性质叫做局部保真性,就是指原来的黑盒模型和现在用来近似的局部模型在某个样本点附近的行为要一致。
# 导入包
import lime
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib notebook
# 用lime方法进行解释
feature_names = df.columns
class_names = ['target']
explainer_lime = lime.lime_tabular.LimeTabularExplainer(X_train.values,feature_names = feature_names,class_names =class_names ,discretize_continuous=True)
# 解释第7条数据
exp = explainer_lime.explain_instance(X_test.iloc[6],clf.predict_proba,num_features=10,top_labels=1)
exp.show_in_notebook(show_table = True,show_all = False)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 48
48 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)