
半监督语义分割方法汇总(附代码分析)
源码地址:https://github.com/HiLab-git/SSL4MIS目的本文主要通过对github上源码的分析,学习半监督语义分割的思想,并通过代码提供的数据对比各个半监督方法的效果。介绍在语义分割领域,标注往往是比较困难的。因为掩膜标注要求和目标边缘紧密贴合,否则会带来边界上的额外损失。如下图:相反的,未标注的数据量一般要远远多于标注的数据量。基于此,半监督方法的研究就至关重要了。
源码地址:https://github.com/HiLab-git/SSL4MIS
目的
本文主要通过对github上源码的分析,学习半监督语义分割的思想,并通过代码提供的数据对比各个半监督方法的效果。
介绍
在语义分割领域,标注往往是比较困难的。因为掩膜标注要求和目标边缘紧密贴合,否则会带来边界上的额外损失。如下图:

相反的,未标注的数据量一般要远远多于标注的数据量。基于此,半监督方法的研究就至关重要了。
机器学习按数据标注情况可分为三种:监督学习,无监督学习和半监督学习。
- 监督学习:在有标记的情况下,对数据进行分类或回归。比如随机森林、SVM和目前流行的全卷积网络、循环神经网络都归为这一类;
- 无监督学习:没有给定事先标记过的范例,自动对输入的资料进行分类或分群。此类有很多机器学习算法,比如k-means、meanshift和PCA,一般通过核函数划分超空间;
- 半监督学习:在有部分标记的情况下,使用所有提供的数据,对输入进行分类和回归的方法。
实验
数据来源
本文实验采用19%标注数据,81%未标注数据进行训练与测试。数据来源为ACDC-Segmentation,该数据集为第戎大学采集的心脏核磁共振影像,标注类型为:背景区域,右心室腔,心肌层和左心室腔。我们使用后三类作为分割结果,使用dice和hd95作为评价指标进行实验。两个指标中,Dice对mask的内部填充比较敏感,而hausdorff distance 对分割出的边界比较敏感。
测量指标
Dice
dice是评价两个目标相关性的指标,又叫F1-score。平衡了召回率和精度的影响,是一个综合性指标。
D
i
c
e
=
1
r
e
c
a
l
l
−
1
+
p
r
e
c
i
s
i
o
n
−
1
=
2
T
P
2
T
P
+
F
P
+
F
N
Dice=\frac {1} {recall^{-1}+precision^{-1}}=\frac {2TP} {2TP+FP+FN}
Dice=recall−1+precision−11=2TP+FP+FN2TP
hausdorff distance
hausdorff distance是测量点集X的到另外一个集和Y最近点的最大距离。
结合下图直观的说,就是比较两点的距离,取更大值。
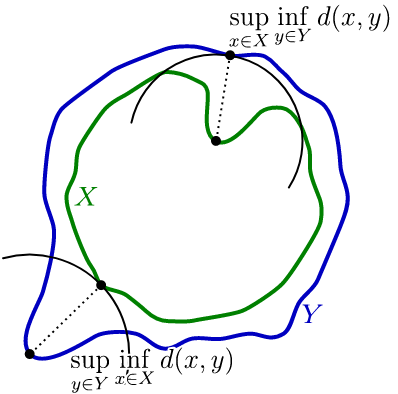
hd95(95% hausdorff distance)类似HD,但只取距离排序后的中间的95%距离,其目的是减轻特殊野点的影响。
监督学习(Baseline)
监督学习实验中使用Unet作为分割网络。下文对比方法中,除非指明,否则默认也使用Unet网络进行对照。监督学习流程如下:

监督损失包括Dice loss 和 Cross Entropy loss。
l
o
s
s
s
u
p
e
r
v
i
s
e
d
=
l
o
s
s
C
E
(
X
,
Y
)
+
l
o
s
s
D
i
c
e
(
X
,
Y
)
,
l
o
s
s
C
E
(
X
,
Y
)
=
∑
(
−
Y
log
(
X
)
+
(
1
−
Y
)
log
(
1
−
X
)
)
,
l
o
s
s
D
i
c
e
(
X
,
Y
)
=
1
−
2
∣
X
⋂
Y
∣
X
+
Y
loss_{supervised}=loss_{CE}(X,Y)+loss_{Dice}(X,Y), \\ loss_{CE}(X, Y) = \sum (-Y \log (X)+(1-Y) \log (1-X)), \\ loss_{Dice}(X, Y)=1-2 \frac {\left | X \bigcap Y\right | } {X+Y}
losssupervised=lossCE(X,Y)+lossDice(X,Y),lossCE(X,Y)=∑(−Ylog(X)+(1−Y)log(1−X)),lossDice(X,Y)=1−2X+Y∣X⋂Y∣
其中,X表示网络预测输出,Y表示标注。
监督学习只使用19%的标注数据作为输入源,训练10000次,得到的结果如下:


其中,编号1、2、3分别代表三个分类。监督学习训练过程中Dice最好为81%,这个结果将作为基准。
下面介绍半监督方法。
半监督学习
相对于监督学习,半监督学习增加了一致性损失,用于测量未标注数据的分割结果并使其靠近某一种约束。

下面是具体的方案,除非特殊指明,否则参数条件和监督学习一致。
mean teacher (论文链接)
mean teacher 的一致性损失为:
l
o
s
s
C
o
n
s
i
s
t
e
n
c
y
=
1
n
∑
(
f
(
X
)
−
f
e
m
a
(
X
e
m
a
)
)
2
loss_{Consistency}= \frac {1} {n} \sum (f(X)-f_{ema}(X_{ema}))^{2}
lossConsistency=n1∑(f(X)−fema(Xema))2
其中
f
e
m
a
f_{ema}
fema是无梯度分割网络,
X
e
m
a
X_{ema}
Xema是加噪原始数据。该约束可描述为:使用源图像得到的分割结果,和加噪图像得到的分割结果应该是一致的。
流程如下:

下面是代码分析:
volume_batch, label_batch = sampled_batch['image'], sampled_batch['label']
...
#加噪
noise = torch.clamp(torch.randn_like(unlabeled_volume_batch) * 0.1, -0.2, 0.2)
ema_inputs = unlabeled_volume_batch + noise
...
#正常结果
outputs = model(volume_batch)
outputs_soft = torch.softmax(outputs, dim=1)
#加噪结果
with torch.no_grad():
ema_output = ema_model(ema_inputs)
ema_output_soft = torch.softmax(ema_output, dim=1)
...
#一致性损失
consistency_loss = torch.mean((outputs_soft[args.labeled_bs:]-ema_output_soft)**2)
该方法训练效果如下:

mean teacher 得到的最优Dice为82.7%。
uncertainty aware mean teacher(论文链接)
该方法相对于mean teacher,增加了一个不确定性掩膜mask。公式如下:
l
o
s
s
C
o
n
s
i
s
t
e
n
c
y
=
l
o
s
s
m
e
a
n
t
e
a
c
h
e
r
∗
m
a
s
k
u
n
c
e
r
t
a
i
n
t
y
=
−
∑
(
Y
log
Y
)
m
a
s
k
=
{
1
u
n
c
e
r
t
a
i
n
t
y
<
t
h
0
e
l
s
e
loss_{Consistency}=loss_{mean teacher}*mask \\ uncertainty=- \sum {(Y\log{Y})} \\ mask=\left\{\begin{matrix} 1 \qquad uncertainty<th \\ 0 \qquad else \end{matrix}\right.
lossConsistency=lossmeanteacher∗maskuncertainty=−∑(YlogY)mask={1uncertainty<th0else
其中, u n c e r t a i n t y uncertainty uncertainty由 X l o g ( X ) Xlog(X) Xlog(X)函数构成,在X=0.36附近最大,两端最小。也就是说,预测图越接近0.36,不确定性越大,不确定性超过一定阈值就置零。
preds = torch.zeros([stride * T, num_classes, w, h]).cuda()
for i in range(T//2):
#带噪声输入
ema_inputs = volume_batch_r + \
torch.clamp(torch.randn_like(volume_batch_r) * 0.1, -0.2, 0.2)
with torch.no_grad():
preds[2 * stride * i:2 * stride *
(i + 1)] = ema_model(ema_inputs)
preds = F.softmax(preds, dim=1)
preds = preds.reshape(T, stride, num_classes, w, h)
preds = torch.mean(preds, dim=0)
#不确定性掩膜计算
uncertainty = -1.0 * torch.sum(preds*torch.log(preds + 1e-6),\
dim=1, keepdim=True)
结果如下:

最优Dice=84%。
interpolation consistency(论文链接)
该方法使用两张图像内插作为输入,如下:
l
o
s
s
u
n
s
u
p
e
r
v
i
s
e
d
=
M
e
a
n
(
o
u
t
p
u
t
m
i
x
e
d
,
f
(
i
n
p
u
t
m
i
x
e
d
)
)
loss_{unsupervised}=Mean(output_{mixed},f(input_{mixed}))
lossunsupervised=Mean(outputmixed,f(inputmixed))
其中,f是不带梯度的分割网络。
#混合输入 input_{mixed}
batch_ux_mixed = unlabeled_volume_batch_0 * \
(1.0 - ict_mix_factors) + \
unlabeled_volume_batch_1 * ict_mix_factors
#混合输入2
input_volume_batch = torch.cat(
[labeled_volume_batch, batch_ux_mixed], dim=0)
outputs = model(input_volume_batch)
outputs_soft = torch.softmax(outputs, dim=1)
with torch.no_grad():
ema_output_ux0 = torch.softmax(
ema_model(unlabeled_volume_batch_0), dim=1)
ema_output_ux1 = torch.softmax(
ema_model(unlabeled_volume_batch_1), dim=1)
#混合输出
batch_pred_mixed = ema_output_ux0 * \
(1.0 - ict_mix_factors) + ema_output_ux1 * ict_mix_factors
#混合输入和输出计算一致性损失
consistency_weight = get_current_consistency_weight(iter_num//150)
consistency_loss = torch.mean(
(outputs_soft[args.labeled_bs:] - batch_pred_mixed) ** 2)
效果如下:

最优Dice=82%。
最小熵约束(论文链接)
entropy minimization,损失如下:
y
=
−
∑
(
p
log
p
)
log
(
C
)
y=- \frac { \sum (p \log p)}{\log (C)}
y=−log(C)∑(plogp)
该公式对输出概率进行最小熵约束,使得p接近0或1时损失较小。其中,C为常数。公式和上一个方法里mask的公式差不多,效果应该也比不上。
outputs = model(volume_batch)
outputs_soft = torch.softmax(outputs, dim=1)
...
# 对所有数据进行熵计算
consistency_loss = losses.entropy_loss(outputs_soft, C=4)
结果如下:

最优Dice=80%。
dv (论文没找到)
这个方法还不能用unet跑,作者说正在完善代码。所以本实验使用的是unet_dv网络。直接看结果:

最优Dice=81%。
对抗网络(论文链接)
该方法应用了对抗网络的思想,设计了一个鉴别器网络DAN。它的核心思想是对鉴别器训练。损失部分由一致性损失
L
c
L_{c}
Lc和鉴别器损失
L
d
L_{d}
Ld组成。假设现有数据集
X
=
(
X
1
,
X
2
)
X=(X_{1},X_{2})
X=(X1,X2),其中已标注子集为
X
1
X_{1}
X1,未标注子集为
X
2
X_{2}
X2,它们由分割模型预测的结果分别为
X
1
X_{1}
X1,
Y
2
Y_{2}
Y2,那么一致性损失和鉴别器损失分别为:
L
d
=
f
(
D
(
X
1
,
Y
1
)
,
1
)
+
f
(
D
(
X
2
,
Y
2
)
,
0
)
L
c
=
f
(
D
(
X
2
,
Y
2
)
,
1
)
L_{d}=f(D(X_{1},Y_{1}),1)+f(D(X_{2},Y_{2}),0) \\ L_{c}=f(D(X_{2},Y_{2}),1)
Ld=f(D(X1,Y1),1)+f(D(X2,Y2),0)Lc=f(D(X2,Y2),1)
- 一致性损失为未标注数据和其预测结果,假定计算机预测结果都为真。
- 鉴别器损失假定人工标注是真,计算机预测是假。两者是相互对抗的。
对抗网络流程图如下:

代码分析如下,这里只分析最关键的鉴别器损失计算:
#假设标注的数据都为真,未标注数据为假
DAN_target = torch.tensor([0] * args.batch_size).cuda()
DAN_target[:args.labeled_bs] = 1
...
# 未标注数据为真,形成对抗,注意这里使用的是DAN_target[:args.labeled_bs]
# 而不是DAN_target[args.labeled_bs:]
DAN_outputs = DAN(
outputs_soft[args.labeled_bs:], volume_batch[args.labeled_bs:])
consistency_loss = F.cross_entropy(
DAN_outputs, (DAN_target[:args.labeled_bs]).long())
...
#鉴别器损失计算,假设标注的数据都为真,未标注数据为假
DAN_outputs = DAN(outputs_soft, volume_batch)
DAN_loss = F.cross_entropy(DAN_outputs, DAN_target.long())
效果如下:

最优Dice=83%。
总结
总的来说,半监督学习方法最终结果都要比基准好。效果最好的是uncertainty aware mean teacher,Dice=84%,原因可能是它用了比较多的约束条件;最少迭代的是对抗网络,它在大概4000次迭代的时候就已经达到最好效果,但具体是不是训练最快的,还要等进一步验证。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)