

卡夫卡 it
Imagine working on your Kafka Streams application. You deploy it to Kubernetes, wait a few hours, and suddenly… Huh… Kafka’s not processing any data anymore… but the apps didn’t crash, did they?
想象一下在您的Kafka Streams应用程序上工作。 您将其部署到Kubernetes ,等待了几个小时,然后突然……嗯……Kafka不再处理任何数据……但是应用程序没有崩溃,不是吗?
When we take a look at the brokers, they are working at full capacity. And all other Kafka applications seem to be processing a little less than before. Kafka is rebalancing!
当我们看经纪人时,他们正在全力工作。 而且所有其他Kafka应用程序的处理似乎都比以前少了一些。 卡夫卡正在重新平衡!
什么是卡夫卡再平衡? (What is Kafka Rebalancing?)
To understand what rebalancing is, we need to understand how Kafka works. First, a few words on Kafka vocabulary.
要了解什么是平衡,我们需要了解Kafka的工作方式。 首先,谈谈卡夫卡的词汇。
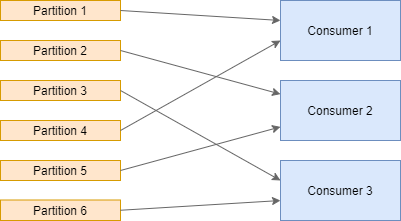
A Kafka cluster consists of one or more brokers. A producer publishes data to Kafka brokers, and a consumer is an application that reads messages from a broker. A Kafka Streams application is both a consumer and a producer simultaneously, but we call it consumer for simplicity in this blog post. All transferred data is stored in a topic. Each topic is divided into one or multiple partitions. Only one consumer can read from a single partition at a time, and thus, the number of partitions of a topic is the maximum possible degree of parallelization.
Kafka集群由一个或多个brokers 。 producer将数据发布给Kafka经纪人,而consumer则是从经纪人读取消息的应用程序。 Kafka Streams应用程序同时既是消费者又是生产者,但是在此博文中为简单起见,我们将其称为消费者。 所有传输的数据都存储在一个topic 。 每个主题分为一个或多个partitions 。 一次只有一个使用者可以从单个分区读取,因此,主题的分区数是最大可能的并行度。
A consumer group is a set of consumers that jointly consume messages from one or multiple Kafka topics. The leader of a group is a consumer that is additionally responsible for the partition assignment in a consumer group.
consumer group是一组消费者,它们共同消费来自一个或多个Kafka主题的消息。 组的leader是使用者,它另外负责使用者组中的分区分配。
Rebalancing is just that — the process to map each partition to precisely one consumer. While Kafka is rebalancing, all involved consumers' processing is blocked (Incremental rebalancing aims to revoke only partitions that need to be transferred to other consumers, and thus, does not block every consumer — more on that below).
Rebalancing就是这样-将每个分区精确映射到一个使用者的过程。 当Kafka重新平衡时,所有涉及的消费者的处理都被阻止(增量重新平衡旨在仅撤消需要转移给其他消费者的分区,因此不会阻止每个消费者-下文将对此进行更多介绍)。
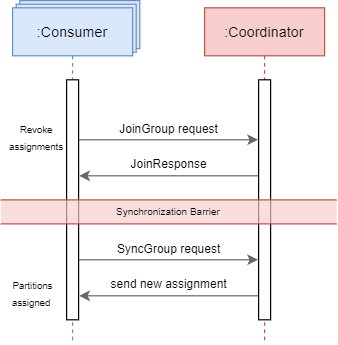
In more detail, all consumers revoke their partitions and sends a JoinGroup request to the group coordinator, which waits for a message from the consumers before transferring consumer information to the group leader(JoinGroupResponse). Then, every consumer sends a SyncGroup request to the leader, which is a request for a new partition assignment. The leader waits until it receives this message to calculate the next partition assignment, and sends the result to the broker, which broadcasts it to all members (SyncGroupResponse). There is a synchronization barrier between these two handshakes to allow the coordinator to distribute the partitions freely. This protocol is called eager rebalancing protocol.
更详细地,所有使用者都撤消其分区,并向组协调器发送JoinGroup请求,该组协调器在将使用者信息传输到组长(JoinGroupResponse)之前等待来自使用者的消息。 然后,每个使用者都将SyncGroup请求发送给领导者,这是对新分区分配的请求。 领导者等待,直到收到此消息以计算下一个分区分配,然后将结果发送给代理,代理将其广播给所有成员(SyncGroupResponse) 。 这两个握手之间存在同步障碍,以允许协调器自由分配分区。 此协议称为eager rebalancing protocol 。
There are multiple partition assignment strategies (e.g., round-robin), and you can even create your own. The default Kafka Streams strategy uses a sticky partition strategy that aims to create an even distribution and tries to minimize partition movements between two rebalancings. Note that there is currently no official lag-aware strategy.
有多种分区分配策略(例如round-robin ),您甚至可以创建自己的策略。 默认的Kafka Streams策略使用粘性分区策略,该策略旨在创建均匀分布,并尝试最小化两次重新平衡之间的分区移动。 请注意,当前没有官方的滞后感知策略。
消费者如何“消费”? (How Does a Consumer “Consume”?)
A consumer reads a message from a topic, processes it, and usually writes one or many messages to an output topic. The following consumer configurations, among others, are taken into account.
使用者从一个主题中读取一条消息,对其进行处理,然后通常将一个或多个消息写入一个输出主题。 特别考虑以下使用者配置。
max.poll.records (default=500) defines the maximum number of messages that a consumer can poll at once.
max.poll.records (default=500)定义使用者可以一次轮询的最大邮件数。
max.partition.fetch.bytes (default=1048576) defines the maximum number of bytes that the server returns in a poll for a single partition.
max.partition.fetch.bytes (default=1048576)定义服务器在轮询中为单个分区返回的最大字节数。
max.poll.interval.ms (default=300000) defines the time a consumer has to process all messages from a poll and fetch a new poll afterward. If this interval is exceeded, the consumer leaves the consumer group.
max.poll.interval.ms (default=300000)定义使用者必须处理轮询中的所有消息并随后获取新轮询的时间。 如果超过此间隔,则消费者将离开消费者组。
heartbeat.interval.ms (default=3000) defines the frequency with which a consumer sends heartbeats.
heartbeat.interval.ms (default=3000)定义使用者发送心跳的频率。
session.timeout.ms (default=10000) defines the time a consumer has to send a heartbeat. If no heartbeat was received in that timeout, the member is considered dead and leaves the group.
session.timeout.ms (default=10000)定义使用者必须发送心跳的时间。 如果在该超时时间内未收到任何心跳信号,则该成员被视为已死亡并离开了该组。
The heartbeats are using a separate thread (since Kafka 0.10.1). The duration of consumer operations does not influence them.
心跳使用单独的线程(从Kafka 0.10.1开始)。 消费者操作的持续时间不影响它们。
什么触发了再平衡? (What Triggers a Rebalancing?)
Kafka starts a rebalancing if a consumer joins or leaves a group. Below are various reasons why that can or will happen. Please keep in mind that we run our Kafka on Kubernetes, so some reasons might not apply to your setup.
如果消费者加入或离开某个群组,Kafka将开始重新平衡。 以下是各种可能或将会发生的原因。 请记住,我们在Kubernetes上运行Kafka,因此某些原因可能不适用于您的设置。
A consumer joins a group:
消费者加入一个小组:
- Application Start/Restart — If we deploy an application (or restart it), a new consumer joins the group 应用程序启动/重新启动-如果我们部署(或重新启动)应用程序,则新使用者加入该组
- Application scale-up — We are creating new pods/application应用程序扩展—我们正在创建新的Pod /应用程序
A consumer leaves a group:
消费者离开一组:
max.poll.interval.msexceeded — polled records not processed in time超过了
max.poll.interval.ms未及时处理轮询记录session.timeout.msexceeded — no heartbeats sent, likely because of an application crash or a network errorsession.timeout.ms超过了-没有发送心跳信号,可能是由于应用程序崩溃或网络错误- Consumer shuts down消费者关闭
Pod relocation — Kubernetes relocates pods sometimes, e.g. if nodes are removed via
kubectl drainor the cluster is scaled down. This feature is awesome, but the consumer shuts down (leaves the group) and is restarted again on another node (joins the group).吊舱重定位— Kubernetes有时会重定位吊舱,例如,通过
kubectl drain移除节点或按比例缩小群集时。 此功能很棒,但是使用者关闭(退出组),然后在另一个节点(加入组)上再次重新启动。- Application scale-down 应用按比例缩小
Rebalancing is necessary for Kafka to work. It should not affect the application, but there are cases where rebalances have a huge impact. Thus, we want to reduce the number of unnecessary rebalancing.
为了使Kafka正常工作,必须进行重新平衡。 它不应该影响应用程序,但是在某些情况下,重新平衡会产生巨大的影响。 因此,我们希望减少不必要的重新平衡次数。
消费者因为时间太长而失败 (Consumers Fail Because They Take Too Long)
A common problem is that some applications have widely differing (sometimes by orders of magnitude) processing times. Especially when there are unexpectedly large records, i.e., almost all records are processed in a very short amount of time, but these very few take longer. These records exceed the max.poll.interval.ms, and would trigger a rebalancing.
一个常见的问题是某些应用程序的处理时间差异很大(有时相差几个数量级)。 尤其是当存在意想不到的大记录时,即几乎所有记录都在很短的时间内处理,但是很少的记录需要更长的时间。 这些记录超过max.poll.interval.ms ,并且将触发重新平衡。
One relatively easy improvement is to increase max.poll.interval.ms(and/or decrease max.poll.records/max.partition.fetch.bytes). We did not experience any backlash from changing these values, and multiple hours can be a suitable interval.
一种相对容易的改进是增加max.poll.interval.ms (和/或减少max.poll.records / max.partition.fetch.bytes )。 更改这些值不会引起任何反弹,并且多个小时可能是一个合适的间隔。
Allowing large processing times introduces another problem, though. As explained before, the leader creates a partition assignment and revokes partitions accordingly. A partition only gets revoked when the consumer finishes processing the current poll. Thus, the leader will wait until every consumer processes their current record.You can imagine what will happen if one consumer processes a record that will take hours. — Right, the rebalancing will take hours as well.
但是,允许大量的处理时间会带来另一个问题。 如前所述,领导者创建分区分配并相应地撤销分区。 仅当使用者完成当前轮询的处理后,分区才会被撤销。 因此,领导者将等到每个消费者处理他们的当前记录。您可以想象如果一个消费者处理需要几个小时的记录会发生什么。 —是的,重新平衡也会花费几个小时。
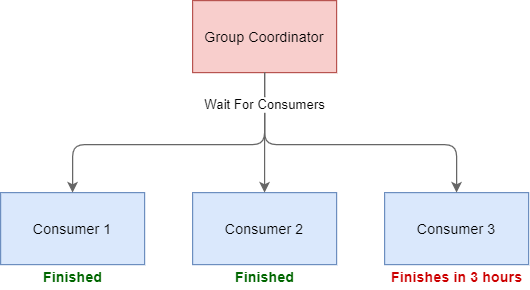
This is a serious problem, and we did not find a good solution for this. What we can do, however, is to reduce the number of rebalancings to reduce the probability that rebalancings occur while we process a time-consuming record.
这是一个严重的问题,我们没有找到一个好的解决方案。 但是,我们可以做的是减少重新平衡的次数,以减少在处理耗时的记录时发生重新平衡的可能性。
卡夫卡静态会员 (Kafka Static Membership)
Kafka static membership is a new feature introduced with Kafka 2.3. It allows the coordinator to persist member identities and to recognize restarted members. This is possible via the consumer configuration group.instance.id. If a consumer restarts for any reason, the group coordinator can assign the same partitions to the consumer without rebalancing everything. This process must happen within the session.timeout.ms limit's bounds because the member does not leave the consumer group until the timeout is exceeded. Otherwise, the consumer is considered dead, and consequently, rebalancing occurs.
Kafka静态成员资格是Kafka 2.3引入的新功能。 它允许协调器保留成员身份并识别重新启动的成员。 这可以通过使用者配置group.instance.id 。 如果使用者由于某种原因而重新启动,则组协调器可以将相同的分区分配给使用者,而无需重新平衡所有内容。 此过程必须在session.timeout.ms限制的范围内进行,因为该成员直到超过超时时间才离开使用者组。 否则,消费者被认为已经死了,因此,发生了重新平衡。
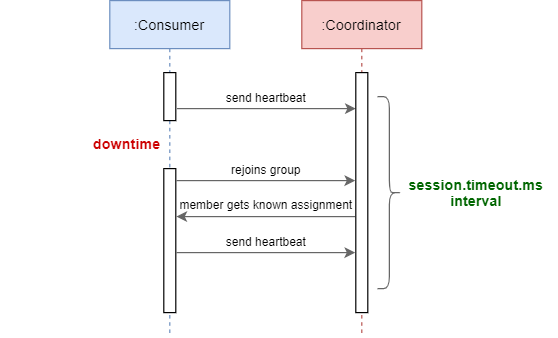
It is recommended to increase the session timeout when using static membership (and only when). The value should fit your use case, and you should configure it as low as possible and as high as needed for pods to restart successfully. In our example, the consumer has a downtime but can rejoin the group inside the configured time limit's bounds. Thus, no rebalancing is needed.
建议在使用静态成员资格时(且仅在使用时)增加会话超时。 该值应适合您的用例,并且应将其配置得尽可能低和高,以使Pod成功重新启动。 在我们的示例中,使用者有一个停机时间,但是可以在配置的时间限制内重新加入该组。 因此,不需要重新平衡。
We use our helm charts to deploy Kafka applications on Kubernetes, which allows us to activate static membership. Inside, we map the group.instance.id to the metadata name of our Kubernetes pod (If the pod restarts, the name does not change).
我们使用舵图在Kubernetes上部署Kafka应用程序,这使我们可以激活静态成员身份。 在内部,我们映射group.instance.id我们Kubernetes荚的元数据名称(如果吊舱重新启动,该名称不会更改)。
...
containers:
- name: {{ template "streams-app.name" . }}-container
...
env:
- name: STREAMS_GROUP_INSTANCE_ID
valueFrom:
fieldRef:
fieldPath: metadata.name
...We are parsing the environment variable directly in our consumer and set the group.instance.id to the pod name in the Kafka Streams configuration to have a constant and unique group member id across container restarts. Additionally, it is possible to use Kubernetes Statefulsets instead of Kubernetes deployments to enable consistent pod identities and persistent state across pod (re)schedulings.
我们直接在使用者中解析环境变量,并在Kafka Streams配置中将group.instance.id设置为pod名称,以便在容器重启时具有恒定的唯一组成员ID。 此外,可以使用Kubernetes Statefulsets代替Kubernetes部署来实现一致的Pod身份和跨Pod(重新)调度的持久状态。
...
{{- if .Values.statefulSet }}
kind: StatefulSet
{{- else }}
kind: Deployment
{{- end }}
...增量合作再平衡(Incremental Cooperative Rebalancing)
Since Kafka 2.4, all stream applications use the incremental cooperative rebalancing protocol to speed up every rebalancing. The idea is that a consumer does not need to revoke a partition if the group coordinator reassigns the same partition to the consumer again. Oversimplified, the old long-running rebalancing is split up into two rebalances:
从Kafka 2.4开始,所有流应用程序都使用增量协作式重新平衡协议来加速每次重新平衡。 这样的想法是,如果组协调者再次将相同的分区重新分配给使用者,则使用者不需要撤销分区。 过于简单化的是,长期运行的旧平衡被分为两个平衡:
First, every consumer sends a
JoinGrouprequest to the coordinator while not revoking their partitions. The group leader reassigns all partitions and removes every partition from the assignment that is to be transferred to another consumer. Afterward, a consumer only needs to revoke the partitions that are not part of its assignment anymore. These consumers then rejoin the group and trigger the second rebalancing.首先,每个使用者都向协调器发送一个
JoinGroup请求,而不撤消其分区。 组长重新分配所有分区,并从分配中删除要转移到另一个使用者的每个分区。 之后,使用者只需要撤销不再属于其分配的分区。 然后,这些消费者重新加入该组并触发第二次重新平衡。- All revoked partitions (currently unassigned) are assigned to a consumer. 所有已撤销的分区(当前未分配)均分配给使用者。
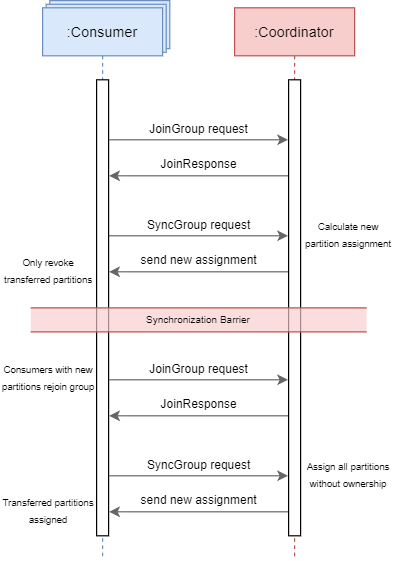
Remember the rebalancing chart describing the eager rebalancing protocol. The synchronization barrier was moved in between these two rebalancings. First, partitions are revoked and not assigned. Then, and after the synchronization, the revoked partitions are re-assigned.
记住描述eager rebalancing protocol的重新平衡图。 同步障碍在这两个重新平衡之间移动。 首先,分区被吊销而不分配。 然后,在同步之后,将重新分配已撤销的分区。
Kafka 2.5 improved on this by allowing consumers to process data while in a rebalancing, which further improves the performance. Confluent showed in an article that the new protocol is a lot faster than the old one.
Kafka 2.5在允许用户重新平衡的同时处理数据方面对此进行了改进,从而进一步提高了性能。 Confluent在一篇文章中表明,新协议比旧协议要快得多。
Nevertheless, this amazing feature does not completely provide a solution for our rebalancing problem with records with long processing times. It helps a lot if only a few partitions get transferred, but cannot work when many members join, and almost every old member has to revoke partitions.
但是,此惊人功能无法完全解决具有较长处理时间的记录的再平衡问题。 如果仅转移了几个分区,这很有用,但是当许多成员加入时,它就无法工作,并且几乎每个旧成员都必须撤销分区。
当我们同时部署N个应用程序时会发生什么? (What Happens When We Deploy N Applications at the Same Time?)
When deploying applications, Kubernetes does not start every application exactly at the same time. There are a few milliseconds or seconds in between. As we explained previously, Kafka starts to rebalance as soon as a consumer joins the group. After the rebalancing, the coordinator notices that more consumer joined and starts another rebalancing. This cycle repeats until all consumers joined the group successfully. Normally, this process is really fast, and multiple rebalancings are not that much of a problem. In some cases (e.g., stateful streams), rebalancing is more expensive. If one of the already joined consumers processes a record with long processing time, this behavior disrupts the complete consumer group for that amount of time. One way to bypass this problem is to configure the group.initial.rebalance.delay.ms (default 3000 = 3 seconds) in the broker configurations. This delays the first rebalancing for x milliseconds, and thus, delays the processing of messages. If a consumer joins an empty group, the coordinator waits until the delay is over before rebalancing. From our experience, 120000 ms (2 minutes) is a value that ensures a smooth start-up of the applications while keeping the waiting times relatively low.
部署应用程序时,Kubernetes不会完全同时启动每个应用程序。 之间有几毫秒或几秒钟的时间。 正如我们之前解释的那样,一旦有消费者加入,Kafka就开始重新平衡。 重新平衡后,协调员会注意到有更多的消费者加入并开始另一个重新平衡。 重复此循环,直到所有消费者成功加入该组。 通常,此过程确实非常快,并且进行多个重新平衡不是什么大问题。 在某些情况下(例如,有状态流),重新平衡更为昂贵。 如果一个已经加入的使用者中的一个处理时间较长的记录,则此行为会在这段时间内中断整个使用者组。 绕过此问题的一种方法是在代理配置中配置group.initial.rebalance.delay.ms (默认为3000 = 3秒)。 这将第一次重新平衡延迟了x毫秒,因此,延迟了消息的处理。 如果消费者加入一个空组,则协调器将等待直到延迟结束后再重新平衡。 根据我们的经验,该值是120000 ms(2分钟),可确保顺利启动应用程序,同时使等待时间保持在较低水平。
While this configuration fixes our problem, changing this setting should be avoided if not needed since this is a broker setting that affects the entire Kafka cluster.
尽管此配置解决了我们的问题,但是如果不需要,则应避免更改此设置,因为这是影响整个Kafka群集的代理设置。
演示申请 (Demo Application)
We want to showcase the impact of unnecessary rebalancings in a small demo application. The idea is to try to force Kafka rebalancings by application crashes and restarts. Afterward, we want to show that these crashes do not necessarily invoke a rebalancing, given suitable configurations. We wrote an article about our deployments of NLP-pipelines in Kafka. While the demo is not NLP specific, this demo uses similar configurations.
我们想在一个小型演示应用程序中展示不必要的重新平衡的影响。 这个想法是试图通过应用程序崩溃和重启来强制Kafka重新平衡。 此后,我们要证明的是,如果配置适当,这些崩溃不一定会导致重新平衡。 我们写了一篇关于我们在Kafka中部署NLP管道的文章。 尽管该演示不是特定于NLP的,但该演示使用了类似的配置。
Our Kafka demo setup is the following:
我们的Kafka演示设置如下:
A Kafka cluster deployed with the confluent helm charts
一个Kafka集群,部署了融合的掌舵图
- A kafka-console-producer and a kafka-console-consumerkafka控制台生产者和kafka控制台消费者
- Three consumers that are processing text messages正在处理短信的三个消费者
Every consumer has the same behavior when processing messages:
每个使用者在处理消息时都有相同的行为:
When reading the message
wait, the consumer waits for 15 minutes before writing the input message into the output topic读取消息
wait,使用者等待15分钟,然后将输入消息写入输出主题When reading the message
crash, the consumer throws aRuntimeExceptionand the Kubernetes pod restarts当读取消息
crash,使用者抛出RuntimeException,并且Kubernetes pod重启- Otherwise, the consumer forwards the input message into the output topic without doing anything else否则,使用者将输入消息转发到输出主题,而无需执行其他任何操作
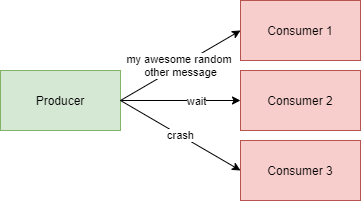
We are using our bakdata helm charts to deploy the three consumers.
我们正在使用bakdata掌舵图来部署这三个使用者。
第一次实验 (First Experiment)
Setup:
建立:
Create topics:
input-topicandoutput-topic创建主题:
input-topic和output-topic- Start non-static deployment 开始非静态部署
Start
kafka-console-producerandkafka-console-consumer启动
kafka-console-producer和kafka-console-consumerWrite random strings into the
kafka-console-producerand see if the messages arrive at thekafka-console-consumer. (You will also see them in the logs of the Kubernetes pods)将随机字符串写入
kafka-console-producer然后查看消息是否到达kafka-console-consumer。 (您还将在Kubernetes窗格的日志中看到它们)
Test:
测试:
Write
waitinto thekafka-console-producer. The message blocks one consumer for 15 minutes.将
wait写到kafka-console-producer。 该消息将阻止一位消费者15分钟。Spam some random messages to the
kafka-console-producer. You should see that some of them do not arrive in the output topic because they are stuck in the blocked consumer.向
kafka-console-producer发送一些随机消息。 您应该看到其中一些没有到达输出主题,因为它们卡在了被阻止的使用者中。Write
crashinto thekafka-console-producer. If no pod restarts, please wait a few seconds. It could be that thecrashmessage was sent to the blocked consumer.将
crash写入kafka-console-producer。 如果没有Pod重新启动,请等待几秒钟。crash消息可能已发送给被阻止的使用者。Spam some random messages to the
kafka-console-producer.向
kafka-console-producer发送一些随机消息。
At this point, no messages should arrive at the output because the consumer group is stuck in a rebalance until the blocked consumer finishes processing the wait message.
在这一点上,没有消息应该到达输出,因为使用者组陷入了重新平衡状态,直到被阻塞的使用者完成了对wait消息的处理。
第二次实验-静态成员资格 (Second Experiment — Static Membership)
Setup:
建立:
- Delete old helm deployment 删除旧的头盔部署
Delete topics:
input-topicandoutput-topic删除主题:
input-topic和output-topicCreate topics:
input-topicandoutput-topic创建主题:
input-topic和output-topic- Start non-static deployment 开始非静态部署
Start
kafka-console-producerandkafka-console-consumer启动
kafka-console-producer和kafka-console-consumerWrite random strings into the
kafka-console-producerand see if the messages arrive at thekafka-console-consumer. (This may take a minute now - After this minute all messages will arrive immediately)将随机字符串写入
kafka-console-producer然后查看消息是否到达kafka-console-consumer。 (现在可能要花一分钟-此分钟后,所有消息将立即到达)
Test:
测试:
Write
waitinto thekafka-console-producer. One consumer is now blocked for 15 minutes.将
wait写到kafka-console-producer。 一位消费者现在被封锁15分钟。Spam some random messages to the
kafka-console-producer. You should see that some of them do not arrive in the output topic because they are stuck in the blocked consumer.向
kafka-console-producer发送一些随机消息。 您应该看到其中一些没有到达输出主题,因为它们卡在了被阻止的使用者中。Write
crashinto thekafka-console-producer. If no pod restarts, please wait a few seconds. It could be that thecrashmessage was sent to the blocked consumer.将
crash写入kafka-console-producer。 如果没有Pod重新启动,请等待几秒钟。crash消息可能已发送给被阻止的使用者。Spam some random messages to the
kafka-console-producer.向
kafka-console-producer发送一些随机消息。
Since the consumer group is not rebalancing, the crashing consumer reads the crash message repeatedly and restarts multiple times. At this point, roughly a third of all messages should arrive in the output topic. One third arrives at the blocked consumer, and the other third arrives at the crash-looping consumer.
由于使用者组没有重新平衡,因此崩溃的使用者会重复读取crash消息,然后重新启动多次。 此时,大约所有消息中的三分之一应到达输出主题。 三分之一到达被阻止的使用者,另一三分之一到达崩溃循环的使用者。
我们学到了什么 (What We’ve Learned)
Rebalancing is necessary for Kafka to work correctly. Still, we should avoid unnecessary rebalancing.
为了使Kafka正常工作,必须进行重新平衡。 尽管如此,我们仍应避免不必要的再平衡。
In our experience, it is best not to play too much with session.timeout.ms and heartbeat.interval.ms if not necessary. However, it is perfectly fine to increase max.poll.interval.ms or decrease the number of records via max.poll.records (or bytes via max.partition.fetch.bytes) in a poll.
根据我们的经验,最好不要在session.timeout.ms和heartbeat.interval.ms上玩太多。 但是,在轮询中增加max.poll.interval.ms或通过max.poll.records (或通过max.partition.fetch.bytes减少字节)来减少记录数是完全可以的。
Updating Kafka regularly is good practice. New updates may introduce improvement on the rebalancing protocol (we mentioned versions 2.3, 2.4, and 2.5 already in this article).
定期更新Kafka是一个好习惯。 新的更新可能会引入对重新平衡协议的改进(我们已经在本文中提到了2.3、2.4和2.5版本)。
Use the Static Membership Protocol if you suffer from frequent rebalancing. In fact, we think this should be the default..
如果经常进行重新平衡,请使用“ Static Membership Protocol 。 实际上,我们认为这应该是默认设置。
If you get stuck in rebalances while deploying multiple applications into an empty group (e.g., first time deploying, destroy everything and deploy again), you may consider configuring group.initial.rebalance.delay.ms.
如果在将多个应用程序部署到一个空组中时遇到了重新平衡问题(例如,第一次部署,销毁所有内容并再次部署),则可以考虑配置group.initial.rebalance.delay.ms 。
We hope you enjoyed reading and now have a better understanding of Kafka rebalancing and how to solve problems with it.
我们希望您喜欢阅读,现在对Kafka重新平衡以及如何解决该问题有了更好的了解。
有用的文章 (Helpful Articles)
In the end, I want to give my thanks to talks that elevated my research on this topic.
最后,我要感谢提高我对该主题研究水平的演讲。
https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/
https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/
https://www.confluent.io/blog/incremental-cooperative-rebalancing-in-kafka/
https://www.confluent.io/blog/incremental-cooperative-rebalancing-in-kafka/
https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/
https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/
翻译自: https://medium.com/bakdata/solving-my-weird-kafka-rebalancing-problems-c05e99535435
卡夫卡 it




 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)