
python数据分析入门【二】 --- 数据处理
python数据分析入门【二】 — 数据处理上一章内容python数据分析入门【一】 — DataFrame & Series下一章内容python数据分析入门【三】 — 数据分析文章目录python数据分析入门【二】 --- 数据处理1、数据导入和导出1.1 数据的导入1)一般方式导入文件2)导入csv文件3)导入文本文件4)导入excel文件(后缀xlsx)1.2 数据的导出1)导出c
python数据分析入门【二】 — 数据处理
上一章内容python数据分析入门【一】 — DataFrame & Series
1、数据导入和导出
1.1 数据的导入
1)一般方式导入文件
用python内置的open()和read(),缺点是不能对数据按格式划分,并封装成可计算的对象
data = open('E://python//数据集//数据分析入门//1.csv').read()


2)导入csv文件
-
使用
pd.read_csv(),如果存在中文路径会报错,此时使用open()打开文件即可(参考https://blog.csdn.net/qq_35318838/article/details/80564938)。得到的数据会被封装成DataFrame对象 -
pd.read_csv()默认分隔符是’,’from pandas import read_csv # 这样读文件会报错:OSError: Initializing from file failed # df = read_csv( # 'E://python//数据集//数据分析入门//1.csv' # ) df = read_csv(open('E://python//数据集//数据分析入门//1.csv'))

-
pd.read_csv()修改分隔符seq,并修改列名namesdf4 = read_csv( open('E://python//数据集//数据分析入门//4.11 字段合并/data.csv'), names=['brand','area','num'], sep=' ' )
3)导入文本文件
注意文本文件一上来就是数据,没有表头,所以要设置列名,并设置分隔符。
"""用read_table导入文本文件(文本文件一上来就是数据,没有表头)"""
from pandas import read_table
df1 = read_table(open('E://python//数据集//数据分析入门//1.txt'))
df2 = read_table(
open('E://python//数据集//数据分析入门//1.txt'),
#设置列名
names=['name', 'age', 'gender'],
#分隔符
sep=','
)


4)导入excel文件(后缀xlsx)
对于导入文件编码错误问题,可以用encoding指定编码格式
from pandas import read_excel
df3 = read_excel(
'E://python//数据集//数据分析入门//1.xlsx',
#不设置编码格式,会报错:UnicodeDecodeError: 'gbk' codec can't
#decode byte 0x90 in position 22: illegal multibyte sequence
encoding='UTF-8'
)

1.2 数据的导出
1)导出csv/txt文件
用df.to_csv()导出csv,文本等文件,可以设置index=False,表示不打印索引列(没有to_table())
"""D:用to_csv导出csv,文本,xlsx等文件"""
from pandas import DataFrame
DataFrame.to_csv()
df.to_csv(
'E://python//数据集//数据分析入门//2.csv',
#不打印索引列
index=False
)
df2.to_csv('E://python//数据集//数据分析入门//2.txt')


2)导出xlsx文件
用df.to_xlsx()导出csv,文本等文件,可以设置index=False,表示不打印索引列
df3.to_excel('E://python//数据集//数据分析入门//2.xlsx',encoding='UTF-8')

2、值处理
值处理包括:重复值,缺失值,空格值的处理
A、重复值处理
import pandas as pd
df = pd.read_csv(
open(r"E://python/数据集/数据分析入门/data.csv")
)
df4 = pd.DataFrame(df)

2.1 用duplicated()找出重复位置
1)找出行的重复位置
duplicated()不指定列,则对行(所有列)进行重复值位置查找
"""找出行的重复位置"""
# 得到重复行的索引系列
dIndex = df4.duplicated()

2)根据列,找出重复位置
"""根据某些列,找到重复的位置"""
dIndex = df4.duplicated("id")


dIndex = df4.duplicated(["id","name"])
根据返回值,把重复数据提取出来
df[dIndex]
2.2 用drop_duplicates()删除重复值
1)根据行重复值进行删除
"""用drop_duplicate(),直接删除重复值(会保留唯一一条数据)"""
# 默认根据所有的列,进行删除(数据结构中,行相同的数据只保留一行)
newDF = df4.drop_duplicates()

2)通过指定列,删除重复值
newDF1 = df4.drop_duplicates(["id","name"])

2.3 向量化计算提取重复值
对于boolean类型的一维数组A,可以根据A,利用向量化计算,提取重复值数据。
dIndex = df4.duplicated(["id","name"])
"""根据返回值,把重复数据提取出来"""
df[dIndex]
---
Out[38]:
id name age gender
3 1251147 wang2 22 male
5 1251147 wang2 22 female
B、缺失值处理
2.1、缺失值的产生和处理方法
缺失值的产生:
- 有些信息暂时无法获取
- 有些信息被遗漏或者错误处理了(年龄那一列要求是数字,但是填入了‘a’,‘b’)
缺失值的处理方法:
- 数据补齐(填充平均值)
- 删除对应缺失行(数据量少慎用)
- 删除对应缺失行
- 不处理
2.2、用 isnull() 找到空值位置
from pandas import read_csv
df = read_csv(
open(r"E:\python\数据集\数据分析入门\4.4 缺失值处理\data.csv")
)
"""A:找出空值的位置,空值位置显示true"""
isNA = df.isnull()


2.3、获取空值所在的行
1)默认所有列
from pandas import DataFrame
isNa = DataFrame(isNA)
"""B:获取空值所在的行(对于所有列来说)"""
#Return whether any element is True over
#requested axis.
#说白了,判断所有列,如果某一列存在一个true值,则该行返回true
#如果全为false,则返回false
df[isNa.any(axis = 1)]
---
Out[9]:
id key value
2 1251147 商品毛重 NaN
3 1251147 NaN 中国
2)指定判断空值的列
"""C:获取某一列含有NA值的行"""
#注意Dataframe如何访问单列/多列,如果是[[]],即里面是series的话,输出会保留列名;
#如果是[],输出不会保留列名;
#如果使用单列1访问,则会报:ValueError: No axis named 1 for
#object type <class 'pandas.core.series.Series'>
df[isNa[['key']].any(axis = 1)]
---
Out[10]:
id key value
3 1251147 NaN 中国
df[isNa[['key','value']].any(axis = 1)]
---
Out[11]:
id key value
2 1251147 商品毛重 NaN
3 1251147 NaN 中国
2.4、用 fillna() 填充空值
'''D:填充空值'''
df.fillna('未知')
---
Out[12]:
id key value
0 1251147 品牌 Apple
1 1251147 商品名称 苹果iPad mini 3
2 1251147 商品毛重 未知
3 1251147 未知 中国
4 1251147 硬盘 128G
5 1251147 尺寸 7.8英寸-9英寸
2.5、用 dropna() 删除空值所在的行
'''E:删除空值所在的行(不是在原数据上删除)'''
newDF = df.dropna()
newDF
---
Out[14]:
id key value
0 1251147 品牌 Apple
1 1251147 商品名称 苹果iPad mini 3
4 1251147 硬盘 128G
5 1251147 尺寸 7.8英寸-9英寸
C、空格值处理
2.1、用str.strip()处理某一列的空格值
from pandas import read_csv
from pandas import Series
from pandas import Index
df = read_csv(
open(r"E:\python\数据集\数据分析入门\4.5 空格值处理\data.csv")
)
---
'''一列可作为Series,会自动添加缺失的索引'''
# Vectorized string functions for Series and Index
# 该语法会报错:Series s = df['name']
# 也不能作为索引:Index index = df['name'],语法会报错
'''注意Python对象类型转换和java的区别'''
s = Series(df['name'])
type(df['name'])
# pandas.core.series.Series

'''A:处理某一列的空格值'''
#'DataFrame' object has no attribute 'str'
# 注意DataFrame.str不存在,而Series.str存在
'''处理左空格'''
newName = df['name'].str.lstrip()
---
Out[18]:
0 KEN
1 JIMI
2 John
'''处理右空格'''
newName1 = df['name'].str.rstrip()
---
Out[23]:
0 KEN
1 JIMI
2 John
'''处理左右空格'''
newName2 = df['name'].str.strip()
---
Out[25]:
0 KEN
1 JIMI
2 John
2.2、将处理好的数据放回原列
'''B:将处理好的数据放回原来的列'''
df['name'] = newName2

3、字段处理
A、字段抽取
字段抽取:
- 根据已知列数据的开始和结束位置,抽取出新的列。
- 例如对于电话号:138 0013 8000,其中138是运营商,0013是地区,8000是号码
from pandas import read_csv
from pandas import Series
df = read_csv(
open(r"E:\python\数据集\数据分析入门\4.6 字段抽取\data.csv")
)
type(df.at[0,'tel'])
---
Out[35]: numpy.int64

3.1、用Series.astype()转换数据类型
# Cast a pandas object to a specified dtype dtype.
Series.astype()
'''A:用Series.astype(),将电话号转成字符串'''
df['tel'] = df['tel'].astype(str)
type(df.at[0,'tel'])
---
Out[37]: str
3.2、用str.slice()字段抽取
# 运营商
brand = df['tel'].str.slice(0,3)
# 地区
area = df['tel'].str.slice(3,7)
# 号码段
nums = df['tel'].str.slice(7,11)
#赋值回去
df['brand'] = brand
df['area'] = area
df['nums'] = nums

B、字段拆分
字段拆分:按照固定的字符,拆分已有字符串
from pandas import read_csv
df = read_csv(
open(r"E:\python\数据集\数据分析入门\4.7 字段拆分\data.csv"),
)

3.1、用split()拆分得到DataFrame
# =============================================================================
# split(sep,n,expand=False)
# 参数说明:
# sep用于分割的字符串,
# n分割为多少列,
# expand为true,则返回DataFrame
# expand为false,则返回Series
# =============================================================================
# 1表示将数据分割成2列,返回值为DataFrame
newDF = df['name'].str.split(' ', 1, True)
#依次修改DataFrame的列名
newDF.columns = ['band','name']

3.2、用split()拆分得到Series
newDF1 = df['name'].str.split(' ', 2, False)

C、字段合并
字段合并:指将同一个数据框中的不同的列,进行合并,形成新的列(字段拆分的逆操作)
# 字段合并方法:x1 + x2 + x3,合并后返回一个Series
df4 = read_csv(
open('E://python//数据集//数据分析入门//4.11 字段合并/data.csv'),
names=['brand','area','num'],
sep=' '
)

注意先将Int64转化成str,才能进行字段合并(字符串加法)
# 注意先将Int64转化成str,才能进行字段合并
# data1 = df4['brand'] + df4['area'] + df4['num']
# Cast a pandas object to a specified dtype ``dtype``
df4 = df4.astype(str)
data1 = df4['brand'] + df4['area'] + df4['num']
df4['tel'] = data1

D、字段匹配
字段匹配:根据各表共有的关键字段(eg:id字段,且数据类型一致),把各表所需的记录一一对应起来,组成一条新的记录
from pandas import read_csv
import pandas as pd
df1 = read_csv(
open('E://python//数据集//数据分析入门//4.12 字段匹配/data1.csv'),
names=['id','comments','title'],
sep='|'
)
df2 = read_csv(
open('E://python//数据集//数据分析入门//4.12 字段匹配/data2.csv'),
names=['id','oldPrice','nowPrice'],
sep='|'
)


3.1、用pd.merge()左连接
# ============================================================================
# merge(x,y,left_on,right_on)
# x:第一个数据框
# y:第二个数据框
# left_on:第一个数据框用于匹配的列(共同字段名,不是Series)
# right_on:第二个数据框用于匹配的列(共同字段名,不是Series)
# 返回DataFrame
# ============================================================================
data1 = pd.merge(
left = df1,
right= df2,
left_on = 'id',
right_on= 'id',
how = "left"
)

3.2、用pd.merge()右连接
'''B:右连接,即使连接不上,也保留右边没连上的部分'''
data2 = pd.merge(
left = df1,
right= df2,
# left_on = df1['id'],
# right_on= df2['id'],
left_on='id',
right_on='id',
how = "right"
)

3.3、用pd.merge()外连接
'''C:外连接,即使连接不上,也保留没连上的部分'''
data3 = pd.merge(
left = df1,
right= df2,
# left_on = df1['id'],
# right_on= df2['id'],
left_on='id',
right_on='id',
how = "outer"
)

4、记录处理
A、记录抽取
记录抽取:指根据一定的条件,对数据进行抽取
from pandas import read_csv
import pandas as pd
df = read_csv(
open(r"E:\python\数据集\数据分析入门\4.8 记录抽取\data.csv"),sep='|'
)

4.1、比较运算
'''A:比较运算'''
df1 = df[df['comments'] > 10000]
df2 = df[df.comments > 10000]
结果都是

4.2、范围运算
'''B:范围运算'''
df3 = df[df.comments.between(1000,10000)]

'''也可以是组合的逻辑运算(结果同上)'''
df7 = df[(df.comments > 1000) & (df.comments < 10000)]
4.3、空值匹配
'''C:空值匹配'''
df4 = df[pd.isnull(df.title)]
pd.isnull(df.title)
---
Out[60]:
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 False
8 False

4.4、根据关键字过滤
'''D:根据关键字过滤'''
# na = False表示空值不用匹配
df5 = df[df.title.str.contains('华为',na=False)]
# ~取反
df6 = df[~df.title.str.contains('华为',na=False)]


B、随机抽样
随机抽样:随机从数据中,按照一定的行数或者比例抽取数据
import numpy as np
import pandas as pd
df = pd.read_csv(
open(r"E:\python\数据集\数据分析入门\4.9 随机抽样\data.csv")
)
#共有100条数据

4.1、按个数抽样
#设置随机种子
np.random.seed(seed = 2)
'''A:按个数抽样'''
df.sample(n = 10)
---
Out[67]:
id class score
64 65 3 57
43 44 1 50
85 86 2 77
51 52 2 88
42 43 3 86
97 98 2 82
75 76 2 59
71 72 2 107
77 78 3 77
15 16 2 91
4.2、按百分比抽样
'''B:按百分比抽样'''
df.sample(frac = 0.02)
---
Out[68]:
id class score
99 100 2 80
13 14 2 69
4.3、可放回的抽样
'''C:可放回抽样'''
df.sample(n = 102, replace=True)
#报错 ValueError: Cannot take a larger sample than population when 'replace=False'
#df.sample(n = 102, replace=False)
---
Out[69]:
id class score
23 24 1 84
30 31 1 46
53 54 1 95
55 56 3 126
98 99 1 71
.. ... ... ...
84 85 2 85
54 55 2 121
99 100 2 80
77 78 3 77
3 4 2 122
57 58 2 82
61 62 3 103
4.4、分层抽样
用df.sample(n = n)按个数抽样
'''D:典型抽样,分层抽样'''
#按照class先对数据进行分组
data = df.groupby("class")
#查看分组情况(字典类型 :{类别:数组})
data.groups
'''1:分层抽样定义(字典类型):1类中抽取2个,2类中抽取4个,3类中抽取6个'''
typicalNDict = {
1: 2,
2: 4,
3: 6
}
type(typicalNDict)
#group难道是df.groupby的返回值传进去的?
#是的,请看df.groupby( 'class',group_keys = False).apply帮助文档
def typicalSampling(group,typicalNDict):
name = group.name
n = typicalNDict[name]
return group.sample(n = n)
# =============================================================================
# df.groupby.apply()
#
# Parameters
# ----------
# func : function
# A callable that takes a dataframe as its first argument, and
# returns a dataframe, a series or a scalar. In addition the
# callable may take positional and keyword arguments
# args, kwargs : tuple and dict
# Optional positional and keyword arguments to pass to ``func``
#
# Returns
# -------
# applied : Series or DataFrame
# =============================================================================
result = df.groupby(
'class'
).apply(typicalSampling,typicalNDict)
result1 = df.groupby(
'class',
#不将组键(键值对)添加到索引,而是将值添加到索引
group_keys = False
).apply(typicalSampling,typicalNDict)
help(df.groupby( 'class',group_keys = False).apply)
help(df.groupby)

用df.sample(frac = frac)按比例抽样
typicalFracDict = {
1: 0.2,
2: 0.4,
3: 0.6
}
def typicalSampling1(group,typicalFracDict):
name = group.name
frac = typicalFracDict[name]
return group.sample(frac = frac)
result2 = df.groupby(
'class',
#不将组键(键值对)添加到索引,而是将值添加到索引
group_keys = True
).apply(typicalSampling1,typicalFracDict)

C、记录合并
记录合并:指将两个结构相同的数据框,合并成一个数据框
from pandas import concat
from pandas import read_csv
#seq默认为,
df = read_csv(
open('E://python//数据集//数据分析入门//4.10 记录合并/data1.csv'),
sep='|'
)
df1 = read_csv(
open('E://python//数据集//数据分析入门//4.10 记录合并/data2.csv'),
sep='|'
)
df2 = read_csv(
open('E://python//数据集//数据分析入门//4.10 记录合并/data3.csv'),
sep='|'
)

4.1、数据框结构相同时的合并
'''A:数据框结构相同时合并'''
# =============================================================================
# concat参数是一个DataFrame或Series的列表
# objs : a sequence or mapping of Series, DataFrame, or Panel objects
# =============================================================================
data = concat([df,df1,df2])

4.2、数据框结构不同时的合并
'''B:数据框结构不同时,先进行列的筛选再合并(为筛选的列填空值)'''
data = concat([
df[['id','comments']],
df1[['comments','title']],
df2[['id','title']]
])

5、其余操作
A、简单计算
简单计算:指通过对已有字段进行加减乘除等运算,得到新的字段
'''A:简单计算'''
df1 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.13 简单计算/data.csv'),
sep='|'
)
df1['totalPrice'] = df1['price'] * df1['num']

B、数据标准化
数据标准化:指将数据按比例缩放,使之落入到特定区间,方便不同变量的比较关系:聚类分析,主成分分析等。
0-1标准化(方便十分制,百分制的换算): $ x^* = \frac{x - min}{max -min}$
'''B:数据标准化'''
df2 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.14 数据标准化/data.csv'),
sep=','
)

'''0-1标准化(保留2位小数)'''
df2.score = round(
(df2.score - df2.score.min()) / (df2.score.max() - df2.score.min()),
2
)

C、数据分组
数据分组:根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间进行研究,以揭示其内在的联系和规律性。

5.1、用df.groupby()按字段值分组(定性分组)
import pandas as pd
import numpy as np
df1 = pd.read_csv(
open('E://python//数据集//数据分析入门//5.2 分组分析/data.csv'),
sep=','
)

df2 = df1.groupby("class")
---
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000023F023BA390>
df2.groups
---
Out[26]:
{'一班': Int64Index([0, 1, 2, 3, 4], dtype='int64'),
'三班': Int64Index([9, 10, 11, 12], dtype='int64'),
'二班': Int64Index([5, 6, 7, 8], dtype='int64')}
df3 = df1.groupby(by = ['class','name'])
df3.groups
---
Out[27]:
{('一班', '朱凤'): Int64Index([1], dtype='int64'),
('一班', '朱志斌'): Int64Index([0], dtype='int64'),
('一班', '许杰'): Int64Index([4], dtype='int64'),
('一班', '郑丽萍'): Int64Index([2], dtype='int64'),
('一班', '郭杰明'): Int64Index([3], dtype='int64'),
('三班', '庄艺家'): Int64Index([12], dtype='int64'),
('三班', '方伟君'): Int64Index([11], dtype='int64'),
('三班', '方小明'): Int64Index([9], dtype='int64'),
('三班', '陈丽灵'): Int64Index([10], dtype='int64'),
('二班', '林良坤'): Int64Index([7], dtype='int64'),
('二班', '林龙'): Int64Index([6], dtype='int64'),
('二班', '郑芬'): Int64Index([5], dtype='int64'),
('二班', '黄志红'): Int64Index([8], dtype='int64')}
df3['score']
---
Out[28]: <pandas.core.groupby.groupby.SeriesGroupBy object at 0x0000023F02423240>
注意
- 用
DataFrameGroupBy.groups来获取分组记录 - 用
DataFrameGroupBy['name']来获取分组的某一列,方便对分组后的该列进行统计分析
5.2、用pd.cut按区间分组(定量分组)
# =============================================================================
# cut(series,bins,right=True,labels=NULL)
# series 需要分组的数据
# bins 分组的划分数组
# right 分组的时候,右边是否闭合
# labels 分组的自定义标签,可以不自定义
# =============================================================================
df3 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.15 数组分组/data.csv'),
sep='|'
)
bins = [
min(df3.cost) - 1,20,30,40,50,60,max(df3.cost) + 1
]
# 区间右边不闭合
df3['cut'] = pd.cut(
df3.cost,
bins,
right=False
)

5.3、用pd.cut按区间自定义标签分组(定量分组)
labels = [
'20以下','20到30','30到40','40到50','50到60','60以上'
]
df3['cut1'] = pd.cut(
df3.cost,
bins,
right = False,
labels = labels
)

D、时间处理
- 时间转换:指将字符型的时间格式数据,转换成为时间型数据的过程
- 时间格式化:将时间型数据,按照指定格式,转为字符型数据
- 时间属性抽取:指从日期格式里面,抽取出需要的部分属性
5.1、用to_datetime()时间转换
'''1、时间转换'''
df4 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.16 时间处理/data.csv'),
sep=','
)
dateTime = pd.to_datetime(
df4['注册时间'],
#format为数据中的时间格式
format='%Y/%m/%d'
)
df4['时间'] = dateTime
type(dateTime)

5.2、用dt.strftime()格式化时间
'''2、时间格式化'''
# 使用时间的dt属性来格式化时间
df4['格式化时间'] = df4['时间'].dt.strftime('%Y-%m-%d')

5.3、用dt.xx抽取时间属性
'''3、时间属性抽取'''
# 使用时间的dt属性来抽取年,月,日...
df4['年'] = df4['时间'].dt.year
df4['月'] = df4['时间'].dt.month
df4['周'] = df4['时间'].dt.week
df4['日'] = df4['时间'].dt.day
df4['时'] = df4['时间'].dt.hour
df4['分'] = df4['时间'].dt.minute
df4['秒'] = df4['时间'].dt.second
E、时间抽取
时间抽取:指根据一定的条件,对时间格式的数据进行抽取
- 根据索引进行抽取
- 根据时间列进行抽取
import pandas as pd
'''时间抽取'''
df1 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.17 时间抽取/data.csv'),
sep=','
)

5.1、时间处理
# =============================================================================
# @classmethod
# def strptime(cls, date_string, format):
# 'string, format -> new datetime parsed from a string (like time.strptime()).'
# import _strptime
# return _strptime._strptime_datetime(cls, date_string, format)
# =============================================================================
dateParser = lambda date : pd.datetime.strptime(
# date是每一次遍历的对象,不能用df1.date,
# date_string = date, format = "%Y%m%d" 会出现TypeError: strptime() takes no keyword arguments
date,"%Y%m%d"
)
#是一个function对象
type(dateParser)
---
function
# =============================================================================
# pd.read_csv
# date_parser : function, default None
# Function to use for converting a sequence of string columns to an array
# of datetime instances. The default uses dateutil.parser.parser to do the
# conversion. Pandas will try to call date_parser in three different ways,
# advancing to the next if an exception occurs: 1) Pass one or more arrays
# (as defined by parse_dates) as arguments; 2) concatenate (row-wise) the
# string values from the columns defined by parse_dates into a single array
# and pass that; and 3) call date_parser once for each row using one or more
# strings (corresponding to the columns defined by parse_dates) as arguments.
#
# parse_dates : boolean or list of ints or names or list of lists or dict, default False
# boolean. If True -> try parsing the index.
# list of ints or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column.
# list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as a single date column.
# dict, e.g. {'foo' : [1, 3]} -> parse columns 1, 3 as date and call result 'foo'
# =============================================================================
'''A:在读取文件时,将str类型的date列转化成dateTime类型'''
'''B:并将时间列作为索引列'''
df2 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.17 时间抽取/data.csv'),
sep=',',
# 日期转换的方法
date_parser = dateParser,
# 要转换的日期所在的列
parse_dates = ['date','date1'],
#将'date'列作为索引列(时间从小到大排序)
index_col= 'date'
)

5.2、按索引抽取
'''C:根据索引进行抽取'''
import datetime
dt1 = datetime.date(year=2016,month=2,day=1)
dt2 = datetime.date(year=2016,month=2,day=5)
#获取索引列中,dt1~dt2时间段内的数据
# =============================================================================
# Warning: Starting in 0.20.0, the .ix indexer is deprecated,
# in favor of the more strict .iloc and .loc indexers.
# =============================================================================
df2.ix[dt1:dt2]
df2.loc[dt1:dt2]
#获取dt1,dt2这两时间点的数据
df2.ix[[dt1,dt2]]
5.3、按时间列(dateTime)抽取
df3 = pd.read_csv(
open('E://python//数据集//数据分析入门//4.17 时间抽取/data.csv'),
sep=','
)
dt1 = datetime.date(year=2016,month=2,day=1)
dt2 = datetime.date(year=2016,month=2,day=5)
df3['date'] = pd.to_datetime(df1['date'],format='%Y%m%d')
type(df3.at[0,'date'])
---
pandas._libs.tslibs.timestamps.Timestamp
type(dt1)
---
datetime.date

# 按时间列进行记录抽取
# 如果时间格式不匹配(eg:date和dateTime比较大小),好像不能用运算符比较大小;
# 但是用索引列(df.ix),即使时间格式不同,也可以比较时间
# df4 = df3[(df3.date >= dt1) & (df3.date <= dt2)]
dt3 = datetime.datetime(2016,2,1,0,0,0)
dt4 = datetime.datetime(2016,2,5,0,0,0)
df4 = df3[(df3.date >= dt3) & (df3.date <= dt4)]

注意区别两种时间抽取的方法:一种是按索引列抽取,另一种是按非索引列抽取。
6、虚拟变量
虚拟变量:也叫离散特征编码,可用于表示分类变量,非数量因素可能产生的影响。
-
离散特征的取值之间有大小的意义(eg:尺寸(L,XL,XXL)
用
pandas.Series.map(dict)来处理 -
离散特征的取值之间没有大小的意义(eg:颜色(Red,Blue,Green)
用
pandas.get_dummies(...)来处理(dummy仿制品)
import pandas as pd
df = pd.read_csv(
open('E://python//数据集//数据分析入门//4.18 虚拟变量/data.csv'),
sep=','
)
# 得到学历(唯一)
educationLevel = df['Education Level'].drop_duplicates()
---
Out[158]:
0 Doctorate
3 Bachelor's Degree
6 Master's Degree
20 Associate's Degree
35 Some College
102 Post-Doc
111 Trade School
157 High School
187 Grade School

6.1、Series.map()处理有大小关系的离散变量
'''A:离散变量(学历)之间具有大小关系'''
"""
博士后 Post-Doc
博士 Doctorate
硕士 Master's Degree
学士 Bachelor's Degree
副学士 Associate's Degree
专业院校 Some College
职业学校 Trade School
高中 High School
小学 Grade School
"""
dict = {
'Post-Doc': 9,
'Doctorate': 8,
'Master\'s Degree': 7,
'Bachelor\'s Degree': 6,
'Associate\'s Degree': 5,
'Some College': 4,
'Trade School': 3,
'High School': 2,
'Grade School': 1
}
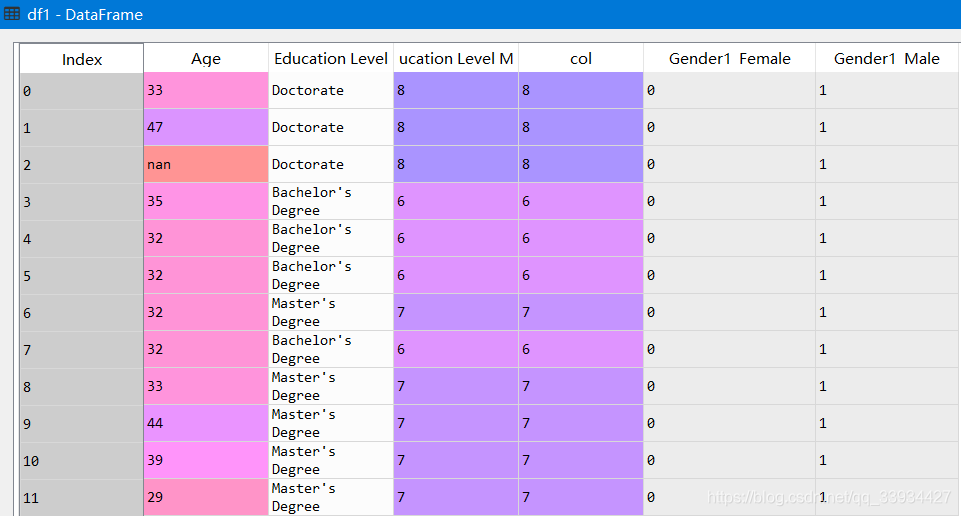
df['Education Level Map'] = pd.Series.map(df['Education Level'],dict)
#或者
df['col'] = df['Education Level'].map(dict)

6.2、pd.get_dummies()处理无大小关系的离散变量
'''B:离散变量(性别)之间没有大小关系'''
# =============================================================================
# pd.get_dummies(data=None,prefix=None,prefix_sep=None,dummy_na=False,columns==None,drop_first=False)
# data 要处理的DataFrame
# prefix 列名的前缀,在多个列有相同的离散项时候使用
# prefix_sep 前缀和离散值得分隔符,默认为下划线,默认即可
# dummy_na 是否把NA值,作为一个离散之进行处理
# columns 要处理的列名,如果不指定该列,那么默认处理所有列
# drop_first 是否从备选项中删第一个,建模的时候为避免共线性使用
# =============================================================================
df1 = pd.get_dummies(
df,
# columns是list
columns=['Gender'],
# prefix可以使字符串,或者是字符串列表
prefix='Gender1',
prefix_sep='_',
dummy_na= False,
# 默认用False,原因我也不知道啊。。
drop_first= False
)
#在使用get_dummies()时,是在原列的基础上进行修改,需要将原来的Gender列重新赋值回去
df1['Gender'] = df['Gender']

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)