
简单粗暴PyTorch之transforms详解(一)
transforms详解一、transforms 介绍二、 transforms 运行机制一、transforms 介绍transforms在计算机视觉工具包torchvision下:torchvision.transforms : 常用的图像预处理方法torchvision.datasets : 常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等torchvisio
transforms详解
一、transforms 介绍
transforms在计算机视觉工具包torchvision下:
torchvision.transforms : 常用的图像预处理方法
torchvision.datasets : 常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等
torchvision.model : 常用的模型预训练,AlexNet,VGG, ResNet,GoogLeNet等
torchvision.transforms : 常用的图像预处理方法,提高泛化能力
• 数据中心化
• 数据标准化
• 缩放
• 裁剪
• 旋转
• 翻转
• 填充
• 噪声添加
• 灰度变换
• 线性变换
• 仿射变换
• 亮度、饱和度及对比度变换
相当于真正高考前做的三年高考五年模拟,五年高考是原始数据,三年模拟是在原题基础上改的模拟题,真正高考碰见了分就高了
二、 transforms 运行机制
采用transforms.Compose(),将一系列的transforms有序组合,实现时按照这些方法依次对图像操作。
train_transform = transforms.Compose([
transforms.Resize((32, 32)), # 缩放
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(), # 图片转张量,同时归一化0-255 ---》 0-1
transforms.Normalize(norm_mean, norm_std), # 标准化均值为0标准差为1
])
构建Dataset实例,DataLoder实例。
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
在训练时每次调用batch_size个数据进行训练,在for循环前设置断点,在Dataset,DataLoder中查看transforms什么时候被调用、被执行。
for i, data in enumerate(train_loader):
debug进入上面for语句可以看到,进入到dataloader.py中,
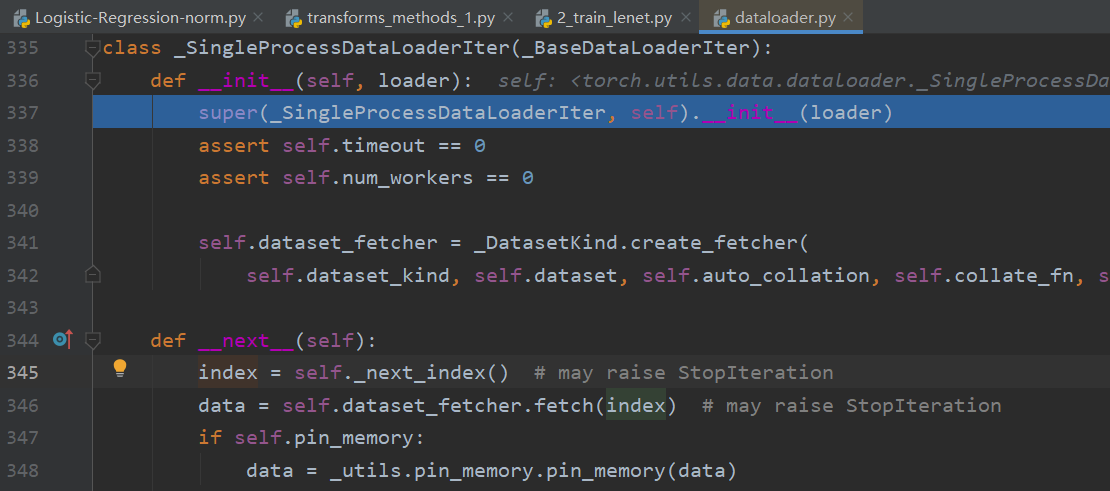
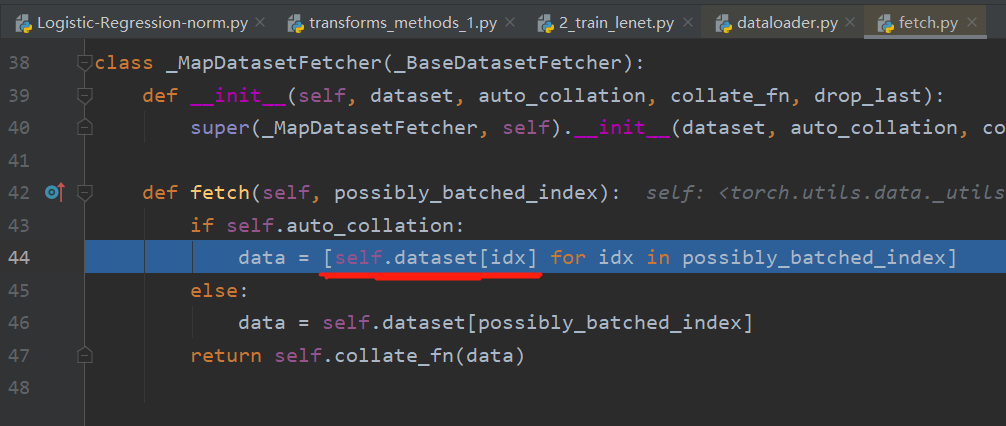
运行到345行获取index告诉读哪些数据,346行根据索引获取数据,进入346行,到fetch.py文件中,可以看到此处调用dataset
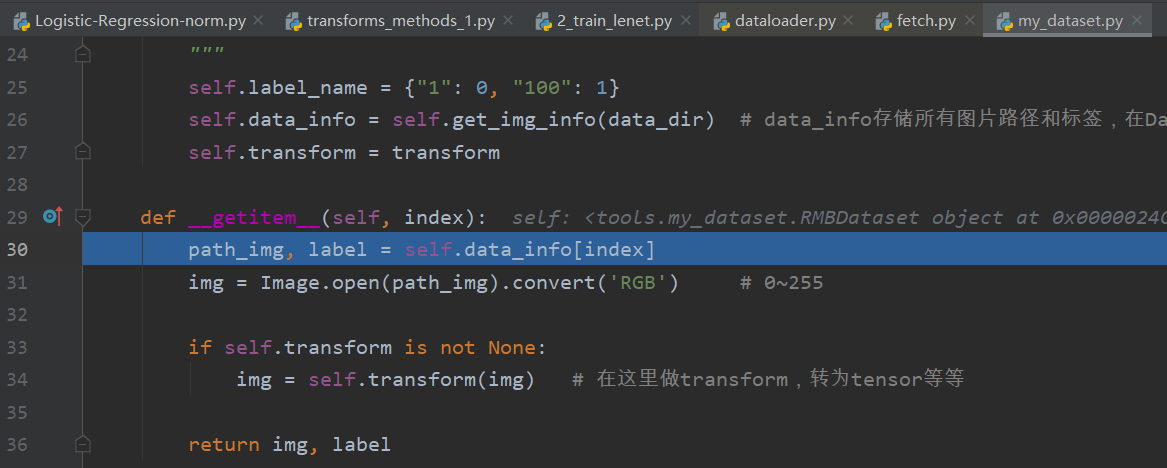
进入dataset,到了my_dataset.py文件下的 __getitem__函数,根据索引获取图片的路径与标签,通过Image.open打开图片,在33,34行调用transform进行图片预处理
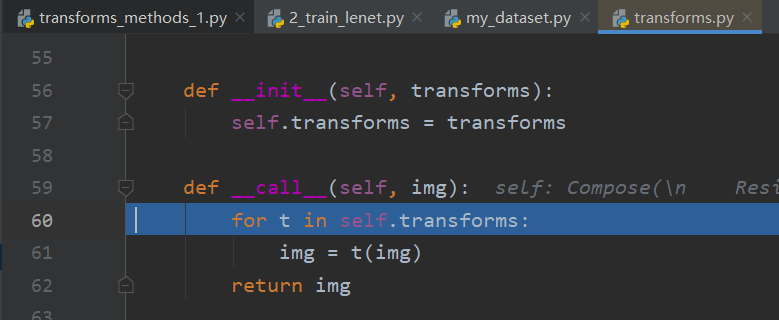
步入到34行,进入到transforms.py的__call__函数,通过for循环一次从compose中调用transforms方法,处理完后返回照片
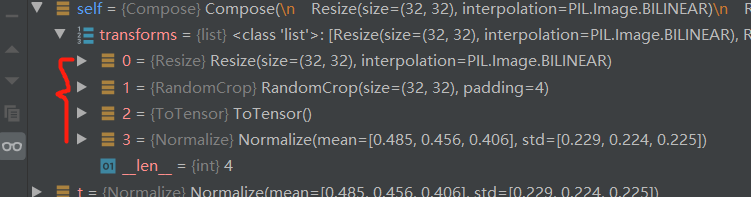
此处就处理完了一个样本,然后循环获取一个batch_size大小的数据,collate_fn函数整理为batch_data返回
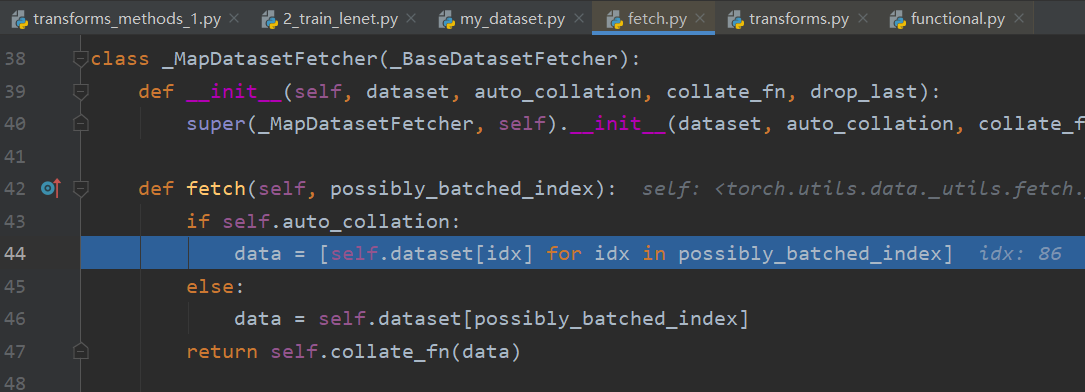
这就读取了一个batch_size的数据

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 60
60 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)