[深度学习 - 实战项目] 行为识别——基于骨架提取/人体关键点估计的行为识别
行为识别——骨架提取/人体关键点估计我们可以通过深度学习,检测到一个人,但是那个人在做什么我们不知道。所以我们就想让神经网络既检测到人,又知道他在做什么。也就是对这个人的行为进行识别。一个人的行为可以有很多种,可以跑、跳、走、跌倒、打架……有一些我们可以看第一眼就知道他在干嘛,有些我们必须看一段才知道他在干嘛。所以我们要用神经网络来识别行为,就可以分成单帧图片的识别和连续帧图片的识别。如果是单帧图
行为识别——骨架提取/人体关键点估计
我们可以通过深度学习,检测到一个人,但是那个人在做什么我们不知道。所以我们就想让神经网络既检测到人,又知道他在做什么。也就是对这个人的行为进行识别。
一个人的行为可以有很多种,可以跑、跳、走、跌倒、打架……有一些我们可以看第一眼就知道他在干嘛,有些我们必须看一段才知道他在干嘛。所以我们要用神经网络来识别行为,就可以分成单帧图片的识别和连续帧图片的识别。
如果是单帧图片的识别,例如举手、摆个姿势……等简单的动作,我们可以直接用卷积网络、或者直接用yolo进行训练。在数据集足够的情况下就能够达到很好的效果。但是生活中动作往往是连续的,因此yolo就无法对多帧图片进行训练。例如,躺下和跌倒、打架和拥抱……
其次,我们要训练一个人的行为,实际在图片上,人的体型、人的衣着、背景的复杂性……都会使训练加大困难。但是实际上能够表示一个人的动作只需要他的骨架信息就够了。那我们要怎么得到人体的骨架呢。
人体姿态估计的算法已经出了好几年了,现在都已经在研究3D姿态了。
我这里就找了几个2D人体关键点估计的算法,然后讲讲他们在做行为识别会出现的一些问题。
1. openpose
openpose官方源码
openpose是自下而上的人体姿态估计算法,也就是先得到关键点位置,再获得骨架。因此计算量不会因为图片上人物的增加而显著增加,能保证时间基本不变。
代码能够实现二维多人关键点检测:15或18或25个关键点的身体/脚关键点估计。运行时间不依赖于检测到的人数。
官方源码是用C++编写的,但是我喜欢用python并且方便我对代码的拼装。因此我也没去跑通。
openpose是自下而上的人体姿态估计算法,因此就会出现当人群密集,或者两个人靠的太近,就容易检测错误。
原始的openpose需要很好的显卡参与计算,也就是说需要很好的硬件支持才能够跑起来,因此就有了个轻量级版本的openpose(基于mobileNetV2)
轻量级版本 lightweight openpose。它可以在CPU上运行,而且速度非常的快,但是准确性就比较差。但是能够在移动设备上运行,算是一个比较好的选择。下面是源码跑出来的效果图。

2. Alphapose
Alphapose是自上而下的算法,也就是先检测倒人体,再得到关键点和骨架。因此他的准确率、Ap值要比openpose高。但是缺点就是随着图片上的人数增加,他的计算量增大,速度变慢。
但是有个好处就是它被遮挡部分的关键点不会任意获取。即可以只显示看得到的部分。准确度方面也比openpose好。
官方源码:AlphaPose-Pytorch:https://github.com/MVIG-SJTU/AlphaPose/tree/pytorch
网络模型基于resnet50、resnet101,因此计算量比较大,运算速度也比较慢。

3. Mobilepose
mobilePose就是用轻量级网络来识别人体关键点,而且大部分都是单人姿态估计。因此可以先加上人体的侦测,如用yolo侦测到人的位置,然后在接上mobilepose,这样速度可以非常的快,而且准确性也比较好。
但是缺点就是,不管人体部分是不是被遮挡,都会生成所有关键点。
Mobile Pose单人姿态估计:https://github.com/YuliangXiu/MobilePose-pytorch
这个源码里面包括ResNet18、MobileNetV2、ShuffleNetV2、SqueezeNet1.1…几个轻量级的网络。
然后官方是直接对摄像头进行裁剪,只有中间一部分,(放得下一个人的位置)。而且即使没有框住人,也会生成骨架信息。例如下图,直到窗口有人出现才把骨架和人对上。

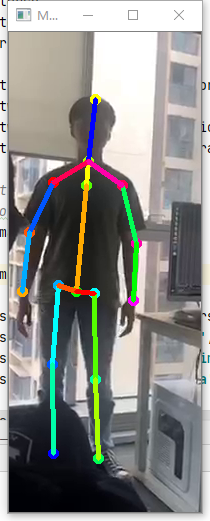
然后我自己加上yoloV5侦测到人的位置,然后在识别骨架。就可以实现多人姿态识别。但是多个人叠在一起还是会影响准确率。

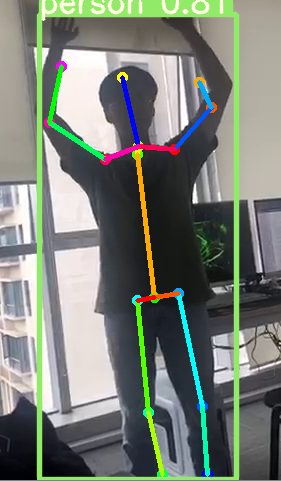
4. 总结
骨架提取如果要在移动端部署,那么就得用轻量级版本。受限于复杂背景,人物可能被遮挡,或者多人重叠的情况就无法很准确的识别骨架。因此在移动端可以实现的只有单人的时候,做单人的行为识别、动作匹配等作用。
对于大场景的行为识别,就要用到比较大的模型,才能有较高的精确度。例如监控下的场景,如果是人稀少的地方,那么轻量级的也可以使用。
关键的问题还是,所需要的场景应用下,我们需要多大的精确度,去做什么类似的动作识别。所以这就得根据所应用得场景来选择模型了。具体我也说不清。
之前在做项目的时候,行为识别大概的思路也是先检测到人,并且要对人进行跟踪(可以用简单的IOU例如上面的lightweight openpose这个代码写的;还有部分的行为识别用的deepsort),然后再提取骨架,最后对连续帧或者单帧的骨架进行行为识别。
以下面这个代码为例,他就是用yoloV3进行人的侦测,再用SPPE(Alphapose)进行骨架提取,再用连续30帧的ST-GCN进行行为识别。站立、走路、跌倒行为识别https://github.com/GajuuzZ/Human-Falling-Detect-Tracks (这里直接右键打开,或者把链接复制到网站上打开,CSDN会跳转到自家的下载资源链接上。。。)
代码的效果还不错,但是准确度还不够。而且在我电脑上1050Ti上跑,单人要10FPS,多人就3FPS以下。(受限于Alphapose自上而下的模式。)然后在2070Ti的电脑上跑,单人能够达到20FPS。(基本上能够达到实时,但是流畅性差了点)
所以后面要根据场景修改模型,重新训练模型。然后根据不同场景部署的方式和应用的方式进行优化选型。
然后说下提取骨架后,行为识别的方法。以前做的时候想了很多方法,当然也研究了很多论文和博客,能够做个总结。
基于单帧图像的骨架:
- 人体骨架的数据,(坐标点或者向量)进行训练。如果是简单的二分类模型,也可以用机器学习的方式如SVM,也可以写个小网络如全连接。难点在于,如果收集数据的问题,而且要对检测到的骨架信息做归一化(量纲)。
- 人体骨架提取出来,单独做一张掩码图。做个简单的卷积网络训练。(就跟手写数字识别一样)
基于连续帧图像的骨架:
- ST-GCN:解读:基于动态骨骼的动作识别方法ST-GCN(时空图卷积网络模型),也可以直接去看官方论文啊,因为我之前没用这个,暂时也没去了解。等以后有用到,在做了解。😂
- LSTM :参考这篇,人体骨架检测+LSTM。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 58
58 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)