
spark源码编译之集成cdh的hadoop版本
0.编译目标spark-2.4.5.tgz 集成hadoop-2.6.0-cdh5.16.2.tar1.下载指定版本源码https://archive.apache.org/dist/spark/后边四个就是四种格式的源码,余下的是安装包wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5.tgz2.准备maven j
·
文章目录
0.编译目标
spark-2.4.5.tgz 集成hadoop-2.6.0-cdh5.16.2.tar
1.下载指定版本源码
https://archive.apache.org/dist/spark/
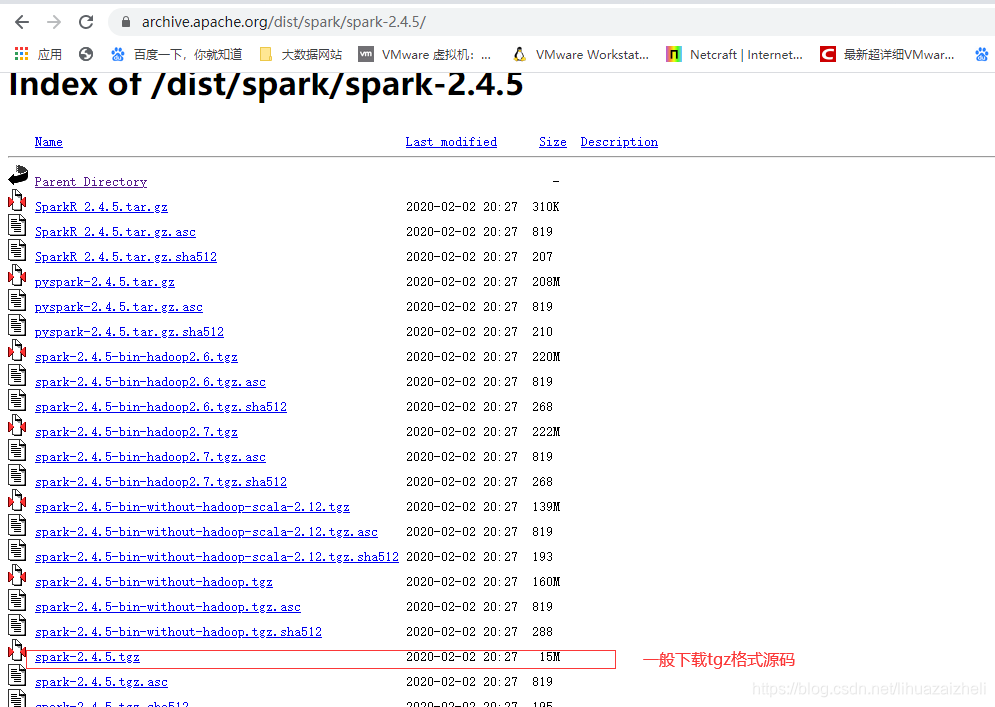
后边四个就是四种格式的源码,余下的是安装包
wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5.tgz
2.准备maven jdk git编译环境
Maven 3.5.4 or +
Java 8
scala 2.11.12
yum install -y git
如果是国内环境,可将maven中的仓库换成aliyun
/usr/local/maven/conf/settings.xml
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>CN</id>
<name>OSChina Central</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
<mirror>
<id>jboss-public-repository-group</id>
<mirrorOf>central</mirrorOf>
<name>JBoss Public Repository Group</name>
<url>https://repository.jboss.org/nexus/content/groups/public</url>
</mirror>
3.编译
官网参考
https://spark.apache.org/docs/2.4.5/building-spark.html
编译注意scala的版本的变动
(1)在spark的3.0.0里面是需要scala2.12的,可以-Dscala.version=2.12.10来进行改动
The Maven-based build is the build of reference for Apache Spark. Building Spark using Maven requires Maven 3.6.3 and Java 8. Spark requires Scala 2.12; support for Scala 2.11 was removed in Spark 3.0.0.
此时linux本地必须安装 scala 2.12.10的版本,才能编译spark3.0.0
[root@hadoop003 ~]# scala -version
Scala code runner version 2.12.10 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
(2)To build Spark using another supported Scala version, please change the major Scala version using (e.g. 2.12):
./dev/change-scala-version.sh 2.12
(3)并在./dev/make-distribution.sh中指定SCALA_VERSION=2.12
(4)编译命令变为
./dev/make-distribution.sh \
--name 2.6.0-cdh5.16.2 \
--tgz \
-Phadoop-2.6 \
-Dhadoop.version=2.6.0-cdh5.16.2 \
-Phive -Phive-thriftserver -Pyarn \
-DskipTests \
-Pscala-2.12 \
-Dscala.version=2.12.10 \
-X
3.1 修改make-distribution.sh(文件在./dev 里面)
在使用这个方式编译的时候,根据查看里面的代码,它会去确认scala,hadoop等的版本信息,这个动作会花费较长的时间。为了不长时间卡在这里,我们直接指定版本信息。先将上面的代码注释掉,然后在后面添加指定信息。其中VERSION为spark的版本。SPARK_HIVE=1为支持hive的意思。
120 #VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null | grep -v "INFO" | tail -n 1)
121 #SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
122 # | grep -v "INFO"\
123 # | tail -n 1)
124 #SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
125 # | grep -v "INFO"\
126 # | tail -n 1)
127 #SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
128 # | grep -v "INFO"\
129 # | fgrep --count "<id>hive</id>";\
130 # # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
131 # # because we use "set -o pipefail"
132 # echo -n)
133
VERSION=2.4.5
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=2.6.0-cdh5.16.2
SPARK_HIVE=1
3.2 在spark source包的根目录pom.xml中添加cdh的 repos
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
3.3 编译命令
./dev/make-distribution.sh \
--name 2.6.0-cdh5.16.2 \
--tgz \
-Phadoop-2.6 \
-Dhadoop.version=2.6.0-cdh5.16.2 \
-Phive -Phive-thriftserver -Pyarn \
-DskipTests \
-X
./dev/make-distribution.sh --name 2.6.0-cdh5.16.2 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.16.2 -Phive -Phive-thriftserver -Pyarn -DskipTests
这些参数的具体使用可以查看make-distribution.sh脚本。name的设置最好是你使用的hadoop版本号,这样可以一眼看出spark是基于什么hadoop版本编译的。
a、 --name 使用要集成的hadoop的版本,可以方便查看
b、 - -tgz 编译好的包后缀名。
c、 -Dhadoop.version hadoop的具体版本号
d、-Phadoop-2.6 hadoop的大版本号
e、-Phive -Phive-thriftserver支持hive
f、-Pyarn支持yarn
g、如果一些编译测试报错,需要开启跳过测试
4.编译成功并查看
(1)编译成功
[INFO] Reactor Summary for Spark Project Parent POM 2.4.5:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 2.964 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 8.686 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 9.732 s]
[INFO] Spark Project Local DB ............................. SUCCESS [ 6.172 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 13.268 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 9.987 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 14.402 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 11.740 s]
[INFO] Spark Project Core ................................. SUCCESS [02:40 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 26.442 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 22.666 s]
[INFO] Spark Project Streaming ............................ SUCCESS [ 56.907 s]
[INFO] Spark Project Catalyst ............................. SUCCESS [02:18 min]
[INFO] Spark Project SQL .................................. SUCCESS [03:01 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:27 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 8.742 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:06 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 7.208 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 17.390 s]
[INFO] Spark Project YARN ................................. SUCCESS [ 22.008 s]
[INFO] Spark Project Hive Thrift Server ................... SUCCESS [ 37.512 s]
[INFO] Spark Project Assembly ............................. SUCCESS [ 3.743 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 17.082 s]
[INFO] Kafka 0.10+ Source for Structured Streaming ........ SUCCESS [ 17.158 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 23.347 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 7.639 s]
[INFO] Spark Avro ......................................... SUCCESS [ 10.695 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12:06 min (Wall Clock)
[INFO] Finished at: 2020-07-04T19:50:53+08:00
[INFO] ------------------------------------------------------------------------
(2)编译完成之后在spark源码跟目录即产生相应的tar包 spark-2.4.5-bin-hadoop-2.6.0-cdh5.16.2.tgz
[root@hadoop003 spark-2.4.5]# pwd
/spark/source/spark-2.4.5
[root@hadoop003 spark-2.4.5]# ls
appveyor.yml build CONTRIBUTING.md dev examples hadoop-cloud licenses NOTICE python repl scalastyle-config.xml streaming
assembly common core dist external launcher mllib pom.xml R resource-managers spark-2.4.5-bin-hadoop-2.6.0-cdh5.16.2.tgz target
bin conf data docs graphx LICENSE mllib-local project README.md sbin sql
(3)解压
tar -zxvf spark-2.4.5-bin-hadoop-2.6.0-cdh5.16.2.tgz
[root@hadoop003 spark-2.4.5]# cd spark-2.4.5-bin-2.6.0-cdh5.16.2
[root@hadoop003 spark-2.4.5-bin-2.6.0-cdh5.16.2]# ls
bin conf data examples jars python README.md RELEASE sbin yarn
[root@hadoop003 spark-2.4.5-bin-2.6.0-cdh5.16.2]# ls -alh
total 60K
drwxr-xr-x 10 root root 4.0K Jul 4 19:50 .
drwxr-xr-x 32 1000 1000 4.0K Jul 4 19:59 ..
drwxr-xr-x 2 root root 4.0K Jul 4 19:50 bin
drwxr-xr-x 2 root root 4.0K Jul 4 19:50 conf
drwxr-xr-x 5 root root 4.0K Jul 4 19:50 data
drwxr-xr-x 4 root root 4.0K Jul 4 19:50 examples
drwxr-xr-x 2 root root 16K Jul 4 19:50 jars
drwxr-xr-x 7 root root 4.0K Jul 4 19:50 python
-rw-r--r-- 1 root root 3.7K Jul 4 19:50 README.md
-rw-r--r-- 1 root root 150 Jul 4 19:50 RELEASE
drwxr-xr-x 2 root root 4.0K Jul 4 19:50 sbin
drwxr-xr-x 2 root root 4.0K Jul 4 19:50 yarn
# 可以看到jars中的hadoop版本
[root@hadoop003 jars]# pwd
/spark/source/spark-2.4.5/spark-2.4.5-bin-2.6.0-cdh5.16.2/jars
[root@hadoop003 jars]# ls
activation-1.1.1.jar hadoop-mapreduce-client-shuffle-2.6.0-cdh5.16.2.jar metrics-json-3.1.5.jar
aircompressor-0.10.jar hadoop-yarn-api-2.6.0-cdh5.16.2.jar metrics-jvm-3.1.5.jar
antlr-2.7.7.jar hadoop-yarn-client-2.6.0-cdh5.16.2.jar minlog-1.3.0.jar
antlr4-runtime-4.7.jar hadoop-yarn-common-2.6.0-cdh5.16.2.jar netty-3.9.9.Final.jar
antlr-runtime-3.4.jar hadoop-yarn-server-common-2.6.0-cdh5.16.2.jar netty-all-4.1.42.Final.jar
aopalliance-1.0.jar hadoop-yarn-server-web-proxy-2.6.0-cdh5.16.2.jar objenesis-2.5.1.jar
aopalliance-repackaged-2.4.0-b34.jar hive-beeline-1.2.1.spark2.jar opencsv-2.3.jar
apacheds-i18n-2.0.0-M15.jar hive-cli-1.2.1.spark2.jar orc-core-1.5.5-nohive.jar
apacheds-kerberos-codec-2.0.0-M15.jar hive-exec-1.2.1.spark2.jar orc-mapreduce-1.5.5-nohive.jar
apache-log4j-extras-1.2.17.jar hive-jdbc-1.2.1.spark2.jar orc-shims-1.5.5.jar
api-asn1-api-1.0.0-M20.jar hive-metastore-1.2.1.spark2.jar oro-2.0.8.jar
api-util-1.0.0-M20.jar hk2-api-2.4.0-b34.jar osgi-resource-locator-1.0.1.jar
arpack_combined_all-0.1.jar hk2-locator-2.4.0-b34.jar paranamer-2.8.jar
arrow-format-0.10.0.jar hk2-utils-2.4.0-b34.jar parquet-column-1.10.1.jar
arrow-memory-0.10.0.jar hppc-0.7.2.jar parquet-common-1.10.1.jar
arrow-vector-0.10.0.jar htrace-core4-4.0.1-incubating.jar parquet-encoding-1.10.1.jar
avro-1.8.2.jar httpclient-4.5.6.jar parquet-format-2.4.0.jar
avro-ipc-1.8.2.jar httpcore-4.4.10.jar parquet-hadoop-1.10.1.jar
avro-mapred-1.8.2-hadoop2.jar ivy-2.4.0.jar parquet-hadoop-bundle-1.6.0.jar
aws-java-sdk-bundle-1.11.134.jar jackson-annotations-2.6.7.jar parquet-jackson-1.10.1.jar
bonecp-0.8.0.RELEASE.jar jackson-core-2.6.7.jar protobuf-java-2.5.0.jar
breeze_2.11-0.13.2.jar jackson-core-asl-1.9.13.jar py4j-0.10.7.jar
breeze-macros_2.11-0.13.2.jar jackson-databind-2.6.7.3.jar pyrolite-4.13.jar
calcite-avatica-1.2.0-incubating.jar jackson-jaxrs-1.9.13.jar RoaringBitmap-0.7.45.jar
calcite-core-1.2.0-incubating.jar jackson-mapper-asl-1.9.13.jar scala-compiler-2.11.12.jar
calcite-linq4j-1.2.0-incubating.jar jackson-module-paranamer-2.7.9.jar scala-library-2.11.12.jar
chill_2.11-0.9.3.jar jackson-module-scala_2.11-2.6.7.1.jar scala-parser-combinators_2.11-1.1.0.jar
chill-java-0.9.3.jar jackson-xc-1.9.13.jar scala-reflect-2.11.12.jar
commons-beanutils-1.9.4.jar janino-3.0.9.jar scala-xml_2.11-1.0.5.jar
commons-cli-1.2.jar JavaEWAH-0.3.2.jar shapeless_2.11-2.3.2.jar
commons-codec-1.10.jar javassist-3.18.1-GA.jar shims-0.7.45.jar
commons-collections-3.2.2.jar javax.annotation-api-1.2.jar slf4j-api-1.7.16.jar
commons-compiler-3.0.9.jar javax.inject-1.jar slf4j-log4j12-1.7.16.jar
commons-compress-1.8.1.jar javax.inject-2.4.0-b34.jar snappy-0.2.jar
commons-configuration-1.6.jar javax.servlet-api-3.1.0.jar snappy-java-1.1.7.3.jar
commons-crypto-1.0.0.jar javax.ws.rs-api-2.0.1.jar spark-catalyst_2.11-2.4.5.jar
commons-dbcp-1.4.jar javolution-5.5.1.jar spark-core_2.11-2.4.5.jar
commons-digester-1.8.jar jaxb-api-2.2.2.jar spark-graphx_2.11-2.4.5.jar
commons-httpclient-3.1.jar jcl-over-slf4j-1.7.16.jar spark-hive_2.11-2.4.5.jar
commons-io-2.4.jar jdo-api-3.0.1.jar spark-hive-thriftserver_2.11-2.4.5.jar
commons-lang-2.6.jar jersey-client-2.22.2.jar spark-kvstore_2.11-2.4.5.jar
commons-lang3-3.5.jar jersey-common-2.22.2.jar spark-launcher_2.11-2.4.5.jar
commons-logging-1.1.3.jar jersey-container-servlet-2.22.2.jar spark-mllib_2.11-2.4.5.jar
commons-math3-3.4.1.jar jersey-container-servlet-core-2.22.2.jar spark-mllib-local_2.11-2.4.5.jar
commons-net-3.1.jar jersey-guava-2.22.2.jar spark-network-common_2.11-2.4.5.jar
commons-pool-1.5.4.jar jersey-media-jaxb-2.22.2.jar spark-network-shuffle_2.11-2.4.5.jar
compress-lzf-1.0.3.jar jersey-server-2.22.2.jar spark-repl_2.11-2.4.5.jar
core-1.1.2.jar jetty-6.1.26.cloudera.4.jar spark-sketch_2.11-2.4.5.jar
curator-client-2.6.0.jar jetty-util-6.1.26.cloudera.4.jar spark-sql_2.11-2.4.5.jar
curator-framework-2.6.0.jar jline-2.14.6.jar spark-streaming_2.11-2.4.5.jar
curator-recipes-2.6.0.jar joda-time-2.9.3.jar spark-tags_2.11-2.4.5.jar
datanucleus-api-jdo-3.2.6.jar jodd-core-3.5.2.jar spark-unsafe_2.11-2.4.5.jar
datanucleus-core-3.2.10.jar jpam-1.1.jar spark-yarn_2.11-2.4.5.jar
datanucleus-rdbms-3.2.9.jar json4s-ast_2.11-3.5.3.jar spire_2.11-0.13.0.jar
derby-10.12.1.1.jar json4s-core_2.11-3.5.3.jar spire-macros_2.11-0.13.0.jar
eigenbase-properties-1.1.5.jar json4s-jackson_2.11-3.5.3.jar ST4-4.0.4.jar
flatbuffers-1.2.0-3f79e055.jar json4s-scalap_2.11-3.5.3.jar stax-api-1.0.1.jar
gson-2.2.4.jar jsr305-1.3.9.jar stax-api-1.0-2.jar
guava-14.0.1.jar jta-1.1.jar stream-2.7.0.jar
guice-3.0.jar jtransforms-2.4.0.jar stringtemplate-3.2.1.jar
guice-servlet-3.0.jar jul-to-slf4j-1.7.16.jar super-csv-2.2.0.jar
hadoop-annotations-2.6.0-cdh5.16.2.jar kryo-shaded-4.0.2.jar univocity-parsers-2.7.3.jar
hadoop-auth-2.6.0-cdh5.16.2.jar leveldbjni-all-1.8.jar validation-api-1.1.0.Final.jar
hadoop-aws-2.6.0-cdh5.16.2.jar libfb303-0.9.3.jar xbean-asm6-shaded-4.8.jar
hadoop-client-2.6.0-cdh5.16.2.jar libthrift-0.9.3.jar xercesImpl-2.9.1.jar
hadoop-common-2.6.0-cdh5.16.2.jar log4j-1.2.17.jar xmlenc-0.52.jar
hadoop-hdfs-2.6.0-cdh5.16.2.jar lz4-java-1.4.0.jar xz-1.5.jar
hadoop-mapreduce-client-app-2.6.0-cdh5.16.2.jar machinist_2.11-0.6.1.jar zookeeper-3.4.6.jar
hadoop-mapreduce-client-common-2.6.0-cdh5.16.2.jar macro-compat_2.11-1.1.1.jar zstd-jni-1.3.2-2.jar
hadoop-mapreduce-client-core-2.6.0-cdh5.16.2.jar metrics-core-3.1.5.jar
hadoop-mapreduce-client-jobclient-2.6.0-cdh5.16.2.jar metrics-graphite-3.1.5.jar
5.spark 3.0.0集成编译
5.1 步骤和上面基本一样
# 根目录下的pom.xml中 scala.version就是2.12,所以不需要change
#(修改make-distribution.sh(文件在./dev 里面)
VERSION=3.0.0
SCALA_VERSION=2.12
SPARK_HADOOP_VERSION=2.6.0-cdh5.16.2
SPARK_HIVE=1
# 编译的时候加一个debug -X
./dev/make-distribution.sh \
--name 2.6.0-cdh5.16.2 \
--tgz \
-Phadoop-2.6 \
-Dhadoop.version=2.6.0-cdh5.16.2 \
-Phive -Phive-thriftserver -Pyarn \
-DskipTests \
-Pscala-2.12 \
-Dscala.version=2.12.10 \
-X
5.2 报错及解决
5.2.1 报错
报此错的原因是hadoop2.6版本中没有spark3.0.0相应的API
Caused by: org.apache.maven.plugin.PluginExecutionException: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:4.3.0:compile failed.
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:148)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:210)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:156)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:148)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:193)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:498)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347)
Caused by: sbt.internal.inc.CompileFailed
at sbt.internal.inc.AnalyzingCompiler.call (AnalyzingCompiler.scala:253)
at sbt.internal.inc.AnalyzingCompiler.compile (AnalyzingCompiler.scala:122)
at sbt.internal.inc.AnalyzingCompiler.compile (AnalyzingCompiler.scala:95)
5.2.2 spark3.0.0中源码类修改
(1)代码所在目录

(2) 修改过程
/**
* Set up the context for submitting our ApplicationMaster.
* This uses the YarnClientApplication not available in the Yarn alpha API.
*/
def createApplicationSubmissionContext(
newApp: YarnClientApplication,
containerContext: ContainerLaunchContext): ApplicationSubmissionContext = {
val componentName = if (isClusterMode) {
config.YARN_DRIVER_RESOURCE_TYPES_PREFIX
} else {
config.YARN_AM_RESOURCE_TYPES_PREFIX
}
val yarnAMResources = getYarnResourcesAndAmounts(sparkConf, componentName)
val amResources = yarnAMResources ++
getYarnResourcesFromSparkResources(SPARK_DRIVER_PREFIX, sparkConf)
logDebug(s"AM resources: $amResources")
val appContext = newApp.getApplicationSubmissionContext
appContext.setApplicationName(sparkConf.get("spark.app.name", "Spark"))
appContext.setQueue(sparkConf.get(QUEUE_NAME))
appContext.setAMContainerSpec(containerContext)
appContext.setApplicationType("SPARK")
sparkConf.get(APPLICATION_TAGS).foreach { tags =>
appContext.setApplicationTags(new java.util.HashSet[String](tags.asJava))
}
sparkConf.get(MAX_APP_ATTEMPTS) match {
case Some(v) => appContext.setMaxAppAttempts(v)
case None => logDebug(s"${MAX_APP_ATTEMPTS.key} is not set. " +
"Cluster's default value will be used.")
}
sparkConf.get(AM_ATTEMPT_FAILURE_VALIDITY_INTERVAL_MS).foreach { interval =>
appContext.setAttemptFailuresValidityInterval(interval)
}
val capability = Records.newRecord(classOf[Resource])
capability.setMemory(amMemory + amMemoryOverhead)
capability.setVirtualCores(amCores)
if (amResources.nonEmpty) {
ResourceRequestHelper.setResourceRequests(amResources, capability)
}
logDebug(s"Created resource capability for AM request: $capability")
sparkConf.get(AM_NODE_LABEL_EXPRESSION) match {
case Some(expr) =>
val amRequest = Records.newRecord(classOf[ResourceRequest])
amRequest.setResourceName(ResourceRequest.ANY)
amRequest.setPriority(Priority.newInstance(0))
amRequest.setCapability(capability)
amRequest.setNumContainers(1)
amRequest.setNodeLabelExpression(expr)
appContext.setAMContainerResourceRequest(amRequest)
case None =>
appContext.setResource(capability)
}
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
logAggregationContext.setRolledLogsIncludePattern(includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
logAggregationContext.setRolledLogsExcludePattern(excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext.setUnmanagedAM(isClientUnmanagedAMEnabled)
sparkConf.get(APPLICATION_PRIORITY).foreach { appPriority =>
appContext.setPriority(Priority.newInstance(appPriority))
}
appContext
}
# 解决和hadoop2.6编译不通过问题
## 注释spark3.0.0
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
logAggregationContext.setRolledLogsIncludePattern(includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
logAggregationContext.setRolledLogsExcludePattern(excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext.setUnmanagedAM(isClientUnmanagedAMEnabled)
sparkConf.get(APPLICATION_PRIORITY).foreach { appPriority =>
appContext.setPriority(Priority.newInstance(appPriority))
}
## 将代码变为 spark2.4.5的代码
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
// These two methods were added in Hadoop 2.6.4, so we still need to use reflection to
// avoid compile error when building against Hadoop 2.6.0 ~ 2.6.3.
val setRolledLogsIncludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsIncludePattern", classOf[String])
setRolledLogsIncludePatternMethod.invoke(logAggregationContext, includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
val setRolledLogsExcludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsExcludePattern", classOf[String])
setRolledLogsExcludePatternMethod.invoke(logAggregationContext, excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
(3)代码修改对比图

(4)参考资料
spark3.0相对于spark2.4.5的源码变动
https://github.com/apache/spark/pull/16884/files
修改spark3.0.0 源码位置
https://github.com/apache/spark/blob/e93b8f02cd706bedc47c9b55a73f632fe9e61ec3/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
5.3 重新编译,成功

[root@hadoop003 source]# cd spark-3.0.0/
[root@hadoop003 spark-3.0.0]# ls
appveyor.yml common data examples launcher mllib-local python resource-managers sql
assembly conf dev external LICENSE NOTICE R sbin streaming
bin CONTRIBUTING.md dist graphx licenses pom.xml README.md scalastyle-config.xml target
build core docs hadoop-cloud mllib project repl spark-3.0.0-bin-2.6.0-cdh5.16.2.tgz tools
解压根目录spark-3.0.0-bin-2.6.0-cdh5.16.2.tgz即可使用

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)