注意力机制Attention Machnism是什么以及为什么
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力
大脑在处理信号信息时是有一定的权重划分的,注意力机制正是模仿了大脑的这种核心特性。注意力机制可以帮助模型对输入的每个部分赋予不用的权重,抽取出更加关键及重要的信息,使模型做出更准确的判断,同时不会对模型的计算和存储带来更大的开销,这是注意力机制应用如此广泛的原因。
下面我们结合Seq2Seq模型来讲解注意力机制。
1、不引入注意力机制的Seq2Seq模型有什么问题?
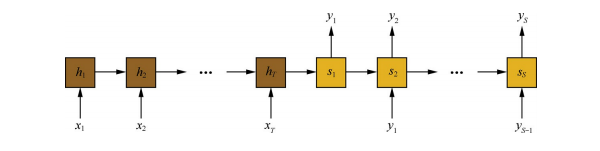
在Seq2Seq模型中,解码阶段,当前隐状态以及上一个输出词决定了当前输出词,即

其中
f
f
f和
g
g
g是非线性变换,通常是多层神经网络;
y
i
y_i
yi是输出序列中的一个词,
s
i
s_i
si是对应的隐状态。
我们举一个单词生成的过程为例:
X
=
<
x
1
,
x
2
,
.
.
.
,
x
m
>
X=<x_1,x_2,...,x_m>
X=<x1,x2,...,xm>
Y
=
<
y
1
,
y
2
,
.
.
.
,
y
n
>
Y=<y_1,y_2,...,y_n>
Y=<y1,y2,...,yn>
从这里可以看出,在解码生成目标 y i y_i yi,不管 y i y_i yi是什么,他们使用的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)。
另一个问题是把输入X的所有信息有压缩到一个固定长度的隐向量Z,忽略了输入X的长度,当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降。
总结一下Seq2Seq存在的问题,也就是注意力机制主要解决的问题?
1、随着序列的增长,模型的性能显著下降。
2、对输入的每个词都赋予相同的权重,是不合理的。
2、注意力机制原理
理解注意力机制的核心在于:原先解码阶段生成每个 y i y_i yi的时候,中间语义表示C都是相同的,而引入注意力机制之后,中间语义表示C会根据当前生成单词而不断变化。

在注意力机制中,仍然可以用普通的循环神经网络对输入序列进行编码,得到隐状态
h
1
,
h
2
,
.
.
.
,
h
T
h_1,h_2,...,h_T
h1,h2,...,hT。但是在解码时,每一个输出词都依赖于前一个隐状态以及输入序列每一个对应的隐状态:
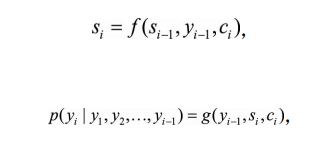
其中语境向量
c
i
c_i
ci是输入序列全部隐状态
h
1
,
h
2
,
.
.
.
,
h
T
h_1,h_2,...,h_T
h1,h2,...,hT的一个加权和

其中注意力权重参数
α
i
j
\alpha_ij
αij并不是一个固定权重,而是由另一个神经网络计算得到

神经网络
a
a
a将上一个输出序列隐状态
s
(
i
−
1
)
s_(i-1)
s(i−1)和输入序列隐状态
h
j
h_j
hj作为输入,计算出一个
x
i
x_i
xi,
y
i
y_i
yi对齐的值
e
i
j
e_ij
eij,再归一化得到权重
α
i
j
\alpha_ij
αij。
3、怎么理解注意力机制的物理含义?
一般文献里会把AM模型看作是单词对齐模型,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
当然,我觉得从概念上理解的话,把AM模型理解成影响力模型也是合理的,就是说生成目标单词的时候,输入句子每个单词对于生成这个单词有多大的影响程度。这种想法也是比较好理解AM模型物理意义的一种思维方式。
下图是论文“A Neural Attention Model for Sentence Summarization”中,Rush用AM模型来做生成式摘要给出的一个AM的一个非常直观的例子

这个例子中,Encoder-Decoder框架的输入句子是:“russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism”。
对应图中纵坐标的句子。系统生成的摘要句子是:“russia calls for joint front against terrorism”,对应图中横坐标的句子。可以看出模型已经把句子主体部分正确地抽出来了。
矩阵中每一列代表生成的目标单词对应输入句子每个单词的AM分配概率,颜色越深代表分配到的概率越大。这个例子对于直观理解AM是很有帮助作用的。
参考文献:
https://mp.weixin.qq.com/s/o5cFu3q8uJCZMVeODlxIoA 作者:张俊林
百面机器学习

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)