
数据预处理Part1——数据清洗
在数据清洗过程中,主要处理的是**缺失值**、**异常值**和**重复值**。所谓清洗,是对数据集通过丢弃、填充、替换、去重等操作。达到去除异常、纠正错误、补足缺失的目的。
文章目录
一、数据预处理
数据预处理是数据建模前的重要环节,他直接决定了后期所有数据工作的质量和价值输出。从数据预处理的主要内容看,包括数据清洗、转换、规约、聚合、抽样等。
本篇文章参考《Python数据分析与数据化运营》,补充一部分书中未提到的方法和代码实现,仅供大家参考。
二、数据清洗
在数据清洗过程中,主要处理的是缺失值、异常值和重复值。所谓清洗,是对数据集通过丢弃、填充、替换、去重等操作。达到去除异常、纠正错误、补足缺失的目的。
1、缺失值处理
数据缺失分为两种,一种是行记录的缺失,这种情况又称数据记录丢失;另一种是数据列值的缺失,即由于各种原因导致的数据记录中某些列的值空缺。
不同的数据存储和环境中对于缺失值的表示结果不同,数据库中Null,Python中是None,Pandas和Numpy中是NaN。
丢失的数据记录通常无法找回,这里重点讨论数据列类型缺失值的处理思路。通常有以下几种思路:
- 丢弃
- 补全
- 真值转换
- 不处理
- 特征选择
1.1 丢弃缺失值
这种处理会直接删除带有缺失值的行记录(整行删除)或者列字段(整列删除),减少缺失数据记录对总体数据的影响。但是丢弃意味着会消减数据特征。所以,以下两种场景不适合使用该方法:
-
数据集中缺失值比例超过10%,删除这些带有缺失值的记录意味着会损失过多有用信息。
-
带有缺失值得数据记录大量存在着明显的数据分布规律特征,例如,在带有缺失值的数据主要集中于某一类或几类标签。一旦删除这些标签,可能会导致模型对于这类标签的拟合或分类不准确。
代码实现:
1. 导包
[1]:import pandas as pd
import numpy as np
from sklearn.preprocessing import Imputer
2. 加载数据
[2]:missing_data = pd.read_excel("missing_data.xlsx",index_col = 0)
missing_data.head()

3. 查看数据
[3]:missing_data.shape
(506, 13)
[4]:missing_data.info()

查看哪些列有缺失
[5]:missing_data.isnull().any()

丢弃缺失值
[6]:drop_missing_data = missing_data.dropna() # 直接丢失含有缺失值的行记录
drop_missing_data.shape
(28, 13)
可以看到,只有28行数据不包含缺失值,其余行数据都被删除。
1.2 补全缺失值
相对丢弃而言,补全是更加常用的缺失值处理方式。通过一定的方法将缺失的数据补上,从而形成更完整的数据记录,对于后续的数据处理、分析和建模至关重要。
常用的补全方法如下:
- 统计法:对于数值型的数据,使用均值、加权均值、中位数等方法补全;对于分类型数据,使用众数补足
- 模型法:更多时候我们会基于已有的其他字段,将缺失字段作为目标变量进行预测,从而得到最为可能的补全值。
- 如果带有缺失值的列是数值变量,采用回归模型补全,如果随机森林回归
- 如果带有缺失值的列是分类变量,采用分类模型补全
- 专家补全:对于少量且具有重要意义的数据记录,使用专家补全
- 其他方法:例如随机法、特殊值法、多重填补等
代码实现:
通过手动获取均值填充或者使用Imputer类进行填充,以及使用随机森林填补缺失值。
使用均值补全
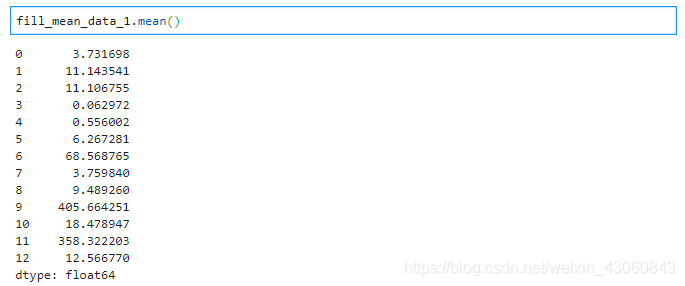
[7]:fill_mean_data_1 = missing_data.fillna(missing_data.mean())
fill_mean_data_1.mean()
[8]:fill_model = Imputer(missing_values='NaN',strategy ="mean",axis=0)
fill_mean_data_2 = pd.DataFrame(fill_model.fit_transform(missing_data))
fill_mean_data_2.mean()
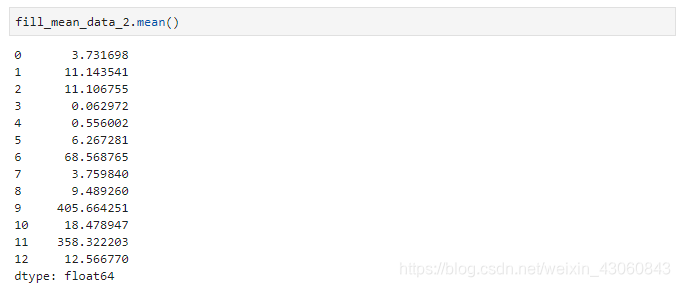
可以看出,手动计算均值填充与使用sklearn中方法填充是一致的。
使用模型补全:
[9]:from sklearn.ensemble import RandomForestRegressor
from sklearn.impute import SimpleImputer
[10]:fill_model_data = missing_data.copy() # 在缺失数据集的复制数据上操作
[11]:sortindex = np.argsort(fill_model_data.isnull().sum(axis=0)).values # 按照每列缺失数据数量由高到低对列名进行排序
[12]:for i in sortindex: # 每次将一列数据作为标签,其他列数据作为特征来预测缺失部分数据
df = fill_model_data
fill_target = df.iloc[:,i] # 标签列
fill_feature = df.iloc[:,df.columns != i] # 特征列
fill_feature = SimpleImputer(missing_values = np.nan,strategy="constant",fill_value=0).fit_transform(fill_feature) # 将特征列中的缺失值用0进行填充
# 划分测试集和训练集
Ytrain = fill_target[fill_target.notnull()]
Ytest = fill_target[fill_target.isnull()]
Xtrain = fill_feature[Ytrain.index,:]
Xtest = fill_feature[Ytest.index,:]
# 用随机森林回归来填补缺失值
rfc = RandomForestRegressor()
rfc = rfc.fit(Xtrain,Ytrain)
predict_value = rfc.predict(Xtest)
# 将预测值替换到缺失值中
fill_model_data.loc[fill_model_data.iloc[:,i].isnull(),i] = predict_value
1.3 真值转换
在某些情况下,我们可能无法得知缺失值的分布规律,并且无法对于缺失值采用上述任何一种补全方法做处理;或者我们认为缺失也是一种规律,不应该轻易对缺失值随意处理,那我们就要使用真值转换进行缺失值的填充。
该方法的根本观点是:我们承认缺失值得存在,并且把数据缺失也作为数据分布规律的一部分,将变量的实际值和缺失值都作为输入维度参与后续数据处理和模型计算中。但是缺失值无法参与模型计算,会报错。因此需要对缺失值进行真值转换
以用户性别为例,很多数据集都无法对会员的性别进行补足,但又舍不得将其丢弃。那么我们选择将其中的值,包括男、女、未知从一个变量的多种结果转换为多个变量的一种结果。
- 转换前:
- 特征:性别 值域:(男 女 未知)
- 转换后:
- 特征1:性别男 值域(1或0)
- 特征2:性别女 值域(1或0)
- 特征1:性别未知 值域(1或0)
然后将这三列新字段替换原来的一个字段参与模型计算。
1.4 不处理
在数据预处理阶段,对于具有缺失值得数据记录不做任何处理,也是一种思路。这种思路主要看后期的数据分析和建模应用。很多模型对于缺失值具有容忍度或者灵活的处理方法,因此在预处理阶段可以不做处理。
常见的能够自动处理缺失值的模型包括:
- KNN:缺失值不参与距离计算
- 决策树和随机森林:将缺失值作为分布的一种状态,并参与到建模流程
- DBSCAN:不基于距离做计算,一次基于值得距离做计算本身的影响就消除了
- …
1.5 特征选择
在数据建模前的数据规约阶段,有一种规约的思路是降维,降维中有一种直接选择特征的方法。假如我们通过一定方法确定带有缺失值的字段对于模型的影响非常小,那我们根本就不需要对缺失值进行处理,无论特征中缺失值比例有多少。因此,后期建模时的字段或特征的重要性判断也是决定是否处理缺失值的重要参考因素之一。
以泰坦尼克号生存预测举例,对于生还来说,姓名,票号等特征几乎无法影响生还概率的。不可能因为姓名稀少,票号流畅等就增加生还概率。所以这种特征无论是否包含缺失值,对后续建模几乎没有影响,可以直接舍弃。
2、异常值
异常数据是数据分布的常态,处于特定分布区域或范围之外的数据通常会被定义为异常或者‘噪音’。产生噪音的原因很多,例如数据抓取问题,业务操作问题等。在对异常数据进行处理前,需辨别出哪些数据是真正的异常。所以,从数据异常的状态看分为两种:
- 一种是假异常:这些异常是由于业务原因产生的,是正常反应业务状态,而不是数据本身的异常规律
- 一种是真异常:这些异常并不是由于特性的业务动作引起的,而是客观地反应了数据本身分布异常的分布个案
2.1 异常值处理
代码实现:
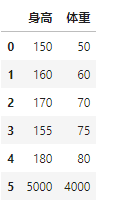
[1]:import pandas as pd
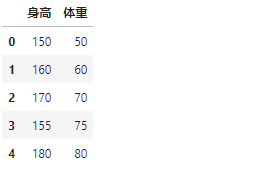
[2]:df = pd.DataFrame({'身高':[150,160,170,155,180,5000],
'体重':[50,60,70,75,80,4000]
})
df
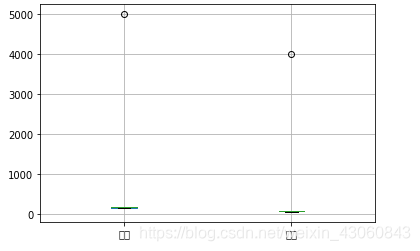
使用箱型图查看异常值:
[3]:df.boxplot()
使用Z-score查看异常值:
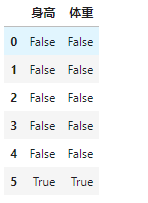
[4]:df_zscore = df.copy()
for col in df.columns:
z_score = (df[col]-df[col].mean()) / df[col].std()
print(z_score)
df_zscore[col] = z_score.abs() > 2 # Z-score标准化得分一般大于2.2,就是相对异常的表现值,这里阈值为2
[5]:df_zscore
删除异常值
[6]:df[df_zscore["身高"]== False]
2.2 保留异常数据的情况
大多数数据挖掘工作中,异常值都会在数据的预处理过程中被认为是噪音而剔除,以避免其对总体数据评估和分析挖掘的影响。但在一下集中情况下,我们无需对异常值做抛弃处理。
2.2.1 异常值正常反映了业务运营结果
例如:某商品正常日销量为1000个左右。由于昨天举行促销活动导致日销量巨增,出售10000个,但是由于前一天出售过多,后端库存备货不足,导致今天销量仅有100台。在这种情况下,数据都是合理且真实的,真实反映了业务运营的结果,所以不能直接抛弃。
2.2.2 异常检测模型
异常检测模型是针对整体样本中的异常数据进行分析和挖掘,以便找到其中的异常个案和规律,这种数据应用围绕异常数据展开,因此异常值不能做抛弃处理。
2.2.3 包容异常值的数据建模
如果数据算法和模型对异常值的包容很好,那么即使不处理异常也不会对模型造成影响。例如在决策树中,异常值本身就可以作为一种分裂节点。
3、重复值
数据中的重复值包括以下两种情况:
- 数据值完全相同的多条数据记录。这是最常见的数据重复情况
- 数据主体相同,但匹配到的唯一属性值不同。这种情况多见于数据仓库中的变化维度表。
3.1 直接去重
去重是重复值处理的主要方法,主要目的是保留能显示特征的唯一数据记录。
代码实现
[1]:import pandas as pd
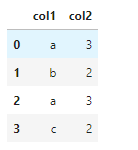
[2]:data1,data2,data3,data4 = ['a',3],['b',2],['a',3],['c',2]
[3]:df = pd.DataFrame([data1,data2,data3,data4],columns=["col1","col2"])
df
查看缺失值:
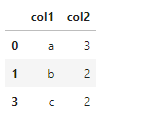
[4]:isDuplicated = df.duplicated()
isDuplicated

删除缺失值:
[5]:df.drop_duplicates()
3.2 保留重复值的情况
3.2.1 重复值用于分析演变规律
例如,某辆汽车在过去的一段时间为畅销品,而在最近的一段时间,为滞销品。那么同样一辆车,在不同的时间维度分属于不同的标签。这时,我们就需要根据实际情况来判断是否去重。
- 如果两条数据需要做整个,那么就需要一个整合字段来合并这两条记录,合成一个新标签;
- 如果需要同时保留这两条数据,那么此时就需要根据需求确定处理规则。
3.2.2 重复值用于样本不均衡处理
在开展分类数据建模工作时,样本不均衡时影响分类模型效果的关键因素之一。解决分类方法的一种方法就是对少数样本类别做简单过采样。通过随机过采样,采取简单复制样本的策略来增加少数类样本。这时,数据集中会产生多条相同记录的数据,我们就不能对重复值进行去重操作。
以信用卡模型为例,不能偿还信用卡的人终究是少数。而我们的目标正是这些不能偿还信用卡的人的特征。这时我们就需要对这部分数据进行过采样处理。
关联文章:
数据预处理Part2——数据标准化
数据预处理Part3——真值转换
数据预处理Part4——数据离散化
数据预处理Part5——样本分布不均衡
数据预处理Part6——数据抽样
数据预处理Part7——特征选择
数据预处理Part8——数据共线性
数据预处理Part9——数据降维

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 137
137 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)