机器学习经典算法---线性回归(Linear Regression)算法
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入欢迎使用Ma.
线性回归(Linear Regression)算法
一、对于回归的理解
回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。顾名思义,分类算法用于离散型分布预测,如KNN、决策树、朴素贝叶斯、adaboost、SVM、Logistic回归都是分类算法;回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
回归的目的就是建立一个回归方程用来预测目标值,回归的求解就是求这个回归方程的回归系数。预测的方法当然十分简单,回归系数乘以输入值再全部相加就得到了预测值。
1、回归的定义
回归最简单的定义是,给出一个点集D,用一个函数去拟合这个点集,并且使得点集与拟合函数间的误差最小,如果这个函数曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归。
2、多元线性回归
假定预测值与样本特征间的函数关系是线性的,回归分析的任务,就在于根据样本X和Y的观察值,去估计函数h,寻求变量之间近似的函数关系。定义:
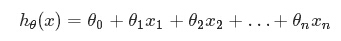
其中,n = 特征数目;
xj = 每个训练样本第j个特征的值,可以认为是特征向量中的第j个值。
为了方便,记x0= 1,则多变量线性回归可以记为:
,(θ、x都表示(n+1,1)维列向量)
Note:注意多元和多次是两个不同的概念,“多元”指方程有多个参数,“多次”指的是方程中参数的最高次幂。多元线性方程是假设预测值y与样本所有特征值符合一个多元一次线性方程。
3、广义线性回归
广义的线性函数:

wj是系数,w就是这个系数组成的向量,它影响着不同维度的Φj(x)在回归函数中的影响度,Φ(x)是可以换成不同的函数,这样的模型我们认为是广义线性模型,Φ(x)=x时就是多元线性回归模型。逻辑回归就是一个广义的线性回归。
二、线性回归方程的求解
假设有连续型值标签(标签值分布为Y)的样本,有X={x1,x2,…,xn}个特征,回归就是求解回归系数θ=θ0, θ1,…,θn。那么,手里有一些X和对应的Y,怎样才能找到θ呢?在回归方程里,求得特征对应的最佳回归系数的方法是最小化误差的平方和,这里的误差是指预测y值和真实y值之间的差值,采用平方误差(最小二乘法)。平方误差可以写做:
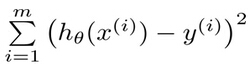
1、一般情况下为什么要用最小二乘法作为性能度量而不是最小绝对值法(最小一乘法)?
首先最小二乘法不永远是最优的方法。对于一般情况下我们认为最小二乘法为较优的度量方式
两者的定义公式

从极大似然估计分析(概率角度的诠释)

多方面分析:
相比于最小绝对值法,最小二乘法有以下的优点:
- 1、最优解唯一。 对于最小二乘法而言,只要自变量不是多重共线性的,解就是唯一的。但是对于最小绝对值法却不是固定的。举例而言,如果我们没有任何自变量(x),而只用截距去回归。最小二乘法会用平均值作为预测值,而最小绝对值法会得出中位数,而中位数往往是不唯一的。例如当数据是两个点:0和2时,最小二乘法会用1作为预测值,但是最小绝对值法会用0~2的任意值作为预测值。
- 2、求解方便。 对于最小二乘法而言,由于误差项是处处可导而且导数连续的,所以我们可以写出求解的等式。但是对于最小绝对值法而言,由于在原点不可导,所以求解会比较复杂。而且由于导数相对恒定(正误差始终为1,负误差始终为-1),所以最小绝对值法求解也会有导数过大的问题。
- 3、有好的解析性质。 最小二乘法在正态分布假设下可以用极大似然估计(MLE)解释,也可以证明解是最优线性无偏估计。
但之所以最小绝对值法也会被使用的原因,主要是最小二乘法的一个大缺点:受异常值扰动影响大。 正因为最小二乘法会将误差开平方,所以当某个预测值和真实值差别过大的时候,最小二乘法会愿意“牺牲”其他本来预测不错的数据点,调节模型使得过差的数据点变得更好一些。在工业界中,常常会因为数据品质的问题,数据集中被混入极端值被影响。而最小绝对值法认为单个大误差无所谓,它只在乎误差绝对值的和。因此,在数据存在异常值的时候,最小二乘法不是一个较好的解法。
结合两种方法——Huber Loss
在我们比较完两者的优劣,你可能意识到:最小二乘法的缺点主要是对于大误差会极度放大它的影响。那我们能不能结合最小二乘法和最小绝对值法,得到一个综合两个优点的方法呢?因此,Huber Loss (SMAE, Smoothed MAE)被提出来,它划定了一个范围delta,当误差小于delta的时候,用最小二乘的方法去算误差,当误差大于delta的时候,用最小绝对值法。用数学方式可表达如下:
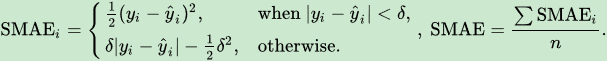
但是这种方法的一大问题就是我们引入了另一个另一个未知参数delta。为了确定最优的delta,我们还需要尝试不同的参数来确定delta的选取。在此就不做展开了。
总结:
- 最小二乘法不永远是最优的方法。对于不同数据形式和建模需求,需要能自行选择合适的建模方式。
- 相比于最小绝对值法,最小二乘法的优点在于最优解唯一、求解方便和有好的解析性质,但缺点在于受异常值扰动影响大。
- Huber Loss (SMAE, Smoothed MAE)结合最小二乘法和最小绝对值法的优点,但引入了另一个另一个未知参数delta。
- 线性回归还有许多问题不能被最小二乘法或最小绝对值法解决。线性回归里没有一个永远最优的方法。

2、线性回归的优化方法
梯度下降法(Gradient Descent)
设定初始参数θ,不断进行迭代,使得J(θ)最小化:
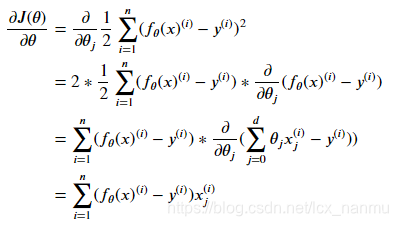
即:
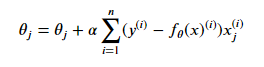
注:下标j表示的是第j个参数,上标i表示的是第i个数据点。
把所有的参数用向量形式表示,可以得到:
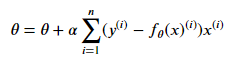
由于在这个方法中,参数在每一个数据点上同时进行了移动,所有被称为批梯度下降法,相应地,我们也可以每一次让参数只针对一个数据点进行移动,即:
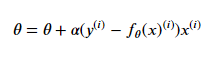
这个算法被称为随机梯度下降法,随机梯度下降法的好处是:当数据点很多的时候,运行效率更高;缺点是:因为每次只针对一个样本更新参数,所以未必能找到最快路径达到最优值,甚至有的时候会出现参数在最小值附近徘徊而不是立即收敛。但是,当数据量很大的时候,随机梯度下降法经常会优于批梯度下降法。
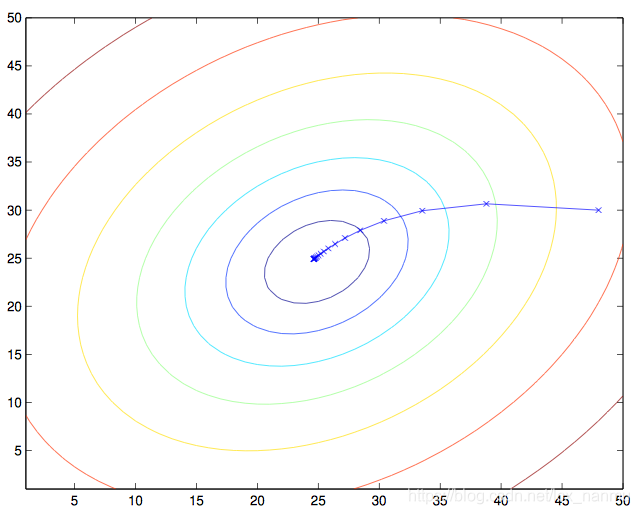
当J为凸函数的时候,梯度下降法相当于让参数θ不断向J的最小值位置移动。
梯度下降法的缺陷是:如果函数为非凸函数的时候,有可能找到的不是全局最优值,而是局部最优值。
最小二乘法矩阵求解、正规方程法(Normal Equation)
令:
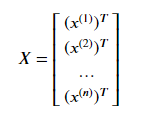
其中,
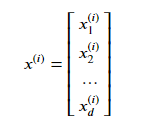
由于,
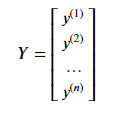
hθ(x)可以写成:

对于向量来说,有:
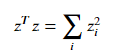
所以,可以把损失函数写作:

为最小化J(θ),对θ求导可以得到:
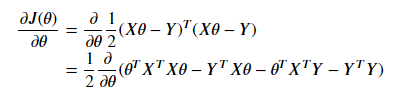
中间两项互为转置,由于求得的值是个标量,矩阵和转置相同,所以可以写成:
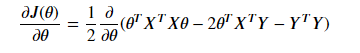
令偏导数等于零,由于最后一项和θ无关,偏导数为0。
所以:
利用矩阵求导性质:
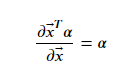
和
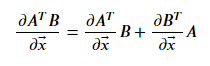
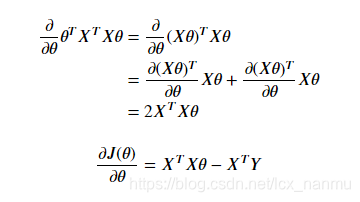
令导数等于零,得:
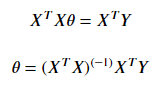
牛顿法
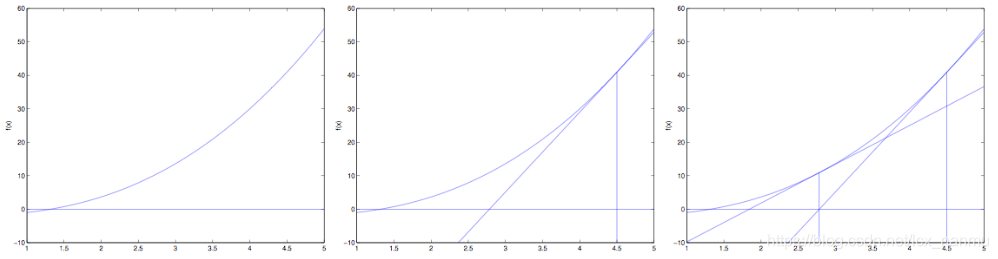
通过上图可知:
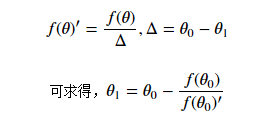
重复迭代,可以让逼近取到f(θ)的最小值。
当我们对损失函数l(θ)进行优化的时候,实际上是想要取到 L’(θ) 的最小值,因此迭代公式为:
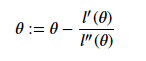
当θ时向量值的时候,
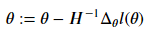
其中, Δ𝜃𝑙(𝜃)是𝑙(𝜃)对𝜃𝑖的偏导数 ,H是J(θ)的海森矩阵,
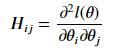
问题:用泰勒展开法推导牛顿法公式。
回答:把f(x)用泰勒公式展开到第二阶,
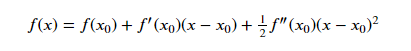
对上式求导,并且令导数等于0,可以求得x的值为:
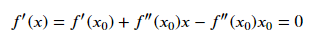
继而可以求得:
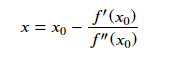
牛顿法的收敛速度会非常快,但是海森矩阵的计算会比较复杂,尤其是当参数的维度很多的时候,会耗费掉大量的计算成本。我们可以用其他矩阵代替海森矩阵,用拟牛顿法进行估计。
拟牛顿法
拟牛顿法的思路是用一个矩阵代替计算复杂的海森矩阵H,因此需要找到符合H性质的矩阵。
要求得海森矩阵符合的条件,同样是对泰勒公式求导:
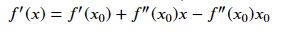
让x = x1,即迭代后的值,代入可得:
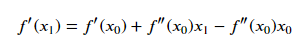
更一般的:
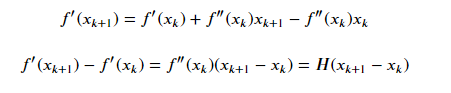
Xk 为第k个迭代值。
即找到矩阵G,使得它符合上式。常用的拟牛顿法的算法包括DFP、BFGS等。
三、回归模型性能度量指标
均方误差(MSE):
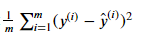
均方根误差(RMSE):
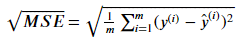
平均绝对误差(MAE):
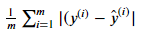
但以上评价指标都不能消除量纲不一致而导致的误差值差别大的问题,最常用的指标是 𝑅2 ,可以避免量纲不一致的问题:
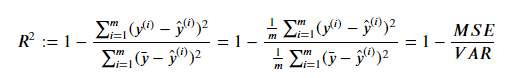
我们可以把 𝑅2 理解为,回归模型可以成功解释的数据方差部分在数据固有方差中所占的比例, 𝑅2 越接近1,表示可解释力度越大,模型拟合的效果越好。
1、线性回归损失函数、代价函数、目标函数
- 损失函数(Loss Function): 度量单样本预测的错误程度,损失函数值越小,模型就越好。
- 代价函数(Cost Function): 度量全部样本集的平均误差。
- 目标函数(Object Function): 代价函数和正则化函数,最终要优化的函数。
常用的损失函数包括:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等;常用的代价函数包括均方误差、均方根误差、平均绝对误差等。

思考题:既然代价函数已经可以度量样本集的平均误差,为什么还要设定目标函数?
当模型复杂度增加时,有可能对训练集可以模拟的很好,但是预测测试集的效果不好,出现过拟合现象,这就出现了所谓的“结构化风险”。结构风险最小化即为了防止过拟合而提出来的策略,定义模型复杂度为 𝐽(𝐹) ,目标函数可表示为:
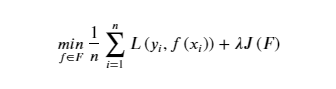
2、经验风险、期望风险、结构风险
经验风险 :对所有训练样本都求一次损失函数,再累加求平均。即,模型f(x)对训练样本中所有样本的预测能力。
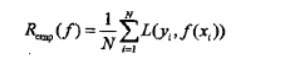
所谓经验风险最小化即对训练集中的所有样本点损失函数的平均最小化。经验风险越小说明模型f(x)对训练集的拟合程度越好。
期望风险: 对所有样本(包含未知样本和已知的训练样本)的预测能力,是全局概念。(经验风险则是局部概念,仅仅表示决策函数对训练数据集里的样本的预测能力。)
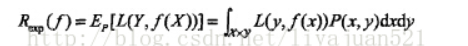
理想的模型(决策)函数应该是让所有的样本的损失函数最小(即期望风险最小化)。但是期望风险函数往往不可得,所以用局部最优代替全局最优。这就是经验风险最小化的理论基础。
总结经验风险和期望风险之间的关系:
经验风险是局部的,基于训练集所有样本点损失函数最小化。经验风险是局部最优,是现实的可求的。
期望风险是全局的,基于所有样本点损失函数最小化。期望风险是全局最优,是理想化的不可求的。
缺点:只考虑经验风险的话,会出现过拟合现象,即模型f(x)对训练集中所有的样本点都有最好的预测能力,但是对于非训练集中的样本数据,模型的预测能力非常不好。怎么办?这就需要结构风险。
结构风险: 对经验风险和期望风险的折中,在经验风险函数后面加一个正则化项(惩罚项),是一个大于0的系数lamada。J(f)表示的是模型的复杂度。
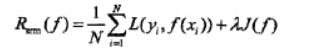
经验风险越小,模型决策函数越复杂,其包含的参数越多,当经验风险函数小到一定程度就出现了过拟合现象。也可以理解为模型决策函数的复杂程度是过拟合的必要条件,那么我们要想防止过拟合现象的方式,就要破坏这个必要条件,即降低决策函数的复杂度。也即,让惩罚项J(f)最小化,现在出现两个需要最小化的函数了。我们需要同时保证经验风险函数和模型决策函数的复杂度都达到最小化,一个简单的办法把两个式子融合成一个式子得到结构风险函数然后对这个结构风险函数进行最小化。
四、python实现线性回归算法
0、生成数据
#生成数据
import numpy as np
#生成随机数
np.random.seed(1234)
x = np.random.rand(500,3)
print(x.shape)
print(x)
#构建映射关系,模拟真实的数据待预测值,映射关系为y = 4.2 + 5.7*x1 + 10.8*x2,可自行设置值进行尝试
y = x.dot(np.array([4.2,5.7,10.8])) # 矩阵相乘 x.dot(y) 等价于 np.dot(x,y)
print(y.shape)
print(y)
# np.array([4.2,5.7,10.8]) (3,)既不是行向量也不是列向量,只是有3个元素,是一个维度为3的数组
1、先尝试调用sklearn的线性回归模型训练数据
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
# 调用模型
lr = LinearRegression(fit_intercept=True)
# 训练模型
lr.fit(x,y)
print("估计的参数值为:%s" %(lr.coef_))
# 计算R平方
print('R2:%s' %(lr.score(x,y)))
# 任意设定变量,预测目标值
x_test = np.array([2,4,5]).reshape(1,-1) # 定义一个行向量
y_hat = lr.predict(x_test)
print("预测值为: %s" %(y_hat))
2、最小二乘法的矩阵求解
class LR_LS():
def __init__(self):
self.w = None
def fit(self, X, y):
# 最小二乘法矩阵求解
#============================= show me your code =======================
self.w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
#============================= show me your code =======================
y_pred = X.dot(self.w)
#============================= show me your code =======================
return y_pred
if __name__ == "__main__":
lr_ls = LR_LS()
lr_ls.fit(x,y)
print("估计的参数值:%s" %(lr_ls.w))
x_test = np.array([2,4,5]).reshape(1,-1)
print("预测值为: %s" %(lr_ls.predict(x_test)))
3、梯度下降法
class LR_GD():
def __init__(self):
self.w = None
def fit(self,X,y,alpha=0.02,loss = 1e-10): # 设定步长为0.002,判断是否收敛的条件为1e-10
y = y.reshape(-1,1) #重塑y值的维度以便矩阵运算
[m,d] = np.shape(X) #自变量的维度
self.w = np.zeros((d)) #将参数的初始值定为0
tol = 1e5
#============================= show me your code =======================
while tol > loss:
h_f = X.dot(self.w).reshape(-1,1)
theta = self.w + alpha*np.mean(X*(y - h_f),axis=0) #计算迭代的参数值
tol = np.sum(np.abs(theta - self.w))
self.w = theta
#============================= show me your code =======================
def predict(self, X):
# 用已经拟合的参数值预测新自变量
y_pred = X.dot(self.w)
return y_pred
if __name__ == "__main__":
lr_gd = LR_GD()
lr_gd.fit(x,y)
print("估计的参数值为:%s" %(lr_gd.w))
x_test = np.array([2,4,5]).reshape(1,-1)
print("预测值为:%s" %(lr_gd.predict(x_test)))
参考:
1、在进行线性回归时,为什么最小二乘法是最优方法?
2、极大似然估计
3、机器学习优化问题-经验风险、期望风险、结构风险

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)