[NLP] 文本分类之TextCNN模型原理和实现(超详细)
1. 模型原理1.1论文Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的n-gram),从而能够更好地捕捉局部相关性。1.2 网络结构Te...
1. 模型原理
1.1论文
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的n-gram),从而能够更好地捕捉局部相关性。与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化(甚至更加简单了), 从图一可以看出textCNN 其实只有一层卷积,一层max-pooling, 最后将输出外接softmax 来n分类。
1.2 网络结构


第(2)部分是重点,理解好卷积过程是关键。
(1)第一层为输入层。输入层是一个 n*k 的矩阵,其中 n 为一个句子中的单词数,k 是每个词对应的词向量的维度。也就是说,输入层的每一行就是一个单词所对应的 k 维的词向量。另外,这里为了使向量长度一致对原句子进行了padding操作。我们这里使用  表示句子中第 i个单词的 k维词嵌入。
表示句子中第 i个单词的 k维词嵌入。
每个词向量可以是预先在其他语料库中训练好的,也可以作为未知的参数由网络训练得到。这两种方法各有优势,预先训练的词嵌入可以利用其他语料库得到更多的先验知识,而由当前网络训练的词向量能够更好地抓住与当前任务相关联的特征。因此,图中的输入层实际采用了双通道的形式,即有两个 n*k 的输入矩阵,其中一个用预训练好的词嵌入表达,并且在训练过程中不再发生变化;另外一个也由同样的方式初始化,但是会作为参数,随着网络的训练过程发生改变。
(2)第二层为卷积层,第三层为池化层。
首先,我们要注意到卷积操作在计算机视觉(CV)和NLP中的不同之处。在CV中,卷积核往往都是正方形的,比如 3*3 的卷积核,然后卷积核在整张image上沿高和宽按步长移动进行卷积操作。与CV中不同的是,在NLP中输入层的"image"是一个由词向量拼成的词矩阵,且卷积核的宽和该词矩阵的宽相同,该宽度即为词向量大小,且卷积核只会在高度方向移动。因此,每次卷积核滑动过的位置都是完整的单词,不会将几个单词的一部分"vector"进行卷积,词矩阵的行表示离散的符号(也就是单词),这就保证了word作为语言中最小粒度的合理性(当然,如果研究的粒度是character-level而不是word-level,需要另外的方式处理)。
然后,我们详述这个卷积、池化过程。由于卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector,其shape=(sentence_len - filter_window_size + 1, 1),那么,在经过max-pooling操作后得到的就是一个Scalar。我们会使用多个filter_window_size(原因是,这样不同的kernel可以获取不同范围内词的关系,获得的是纵向的差异信息,即类似于n-gram,也就是在一个句子中不同范围的词出现会带来什么信息。比如可以使用3,4,5个词数分别作为卷积核的大小),每个filter_window_size又有num_filters个卷积核(原因是卷积神经网络学习的是卷积核中的参数,每个filter都有自己的关注点,这样多个卷积核就能学习到多个不同的信息。使用多个相同size的filter是为了从同一个窗口学习相互之间互补的特征。 比如可以设置size为3的filter有64个卷积核)。一个卷积核经过卷积操作只能得到一个scalar,将相同filter_window_size卷积出来的num_filter个scalar组合在一起,组成这个filter_window_size下的feature_vector。最后再将所有filter_window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入。对这个过程若有不清楚的地方,可以对照着图2来看,图2非常完美地诠释了这个过程。

(3)得到文本句子的向量表示之后,后面的网络结构就和具体的任务相关了。本例中展示的是一个文本分类的场景,因此最后接入了一个全连接层,并使用Softmax激活函数输出每个类别的概率。
TextCNN的详细过程原理图如下:

1.2 TextCNN的优势
与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取。 自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如 “今天” 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是"今天"这个词汇, 这种滑动没有帮助.
TextCNN的成功, 不是网络结构的成功, 而是通过引入已经训练好的词向量来在多个数据集上达到了超越benchmark 的表现,进一步证明了构造更好的embedding, 是提升nlp 各项任务的关键能力。
TextCNN网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。
网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
2.TextCNN详细过程
2.1 Word Embedding 分词构建词向量
如图二所示, textCNN 首先将 “今天天气很好,出来玩” 分词成"今天/天气/很好/,/出来/玩, 通过word2vec或者GLOV 等embedding 方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如 “今天” -> [0,0,0,0,1], “天气” ->[0,0,0,1,0], “很好” ->[0,0,1,0,0]等等。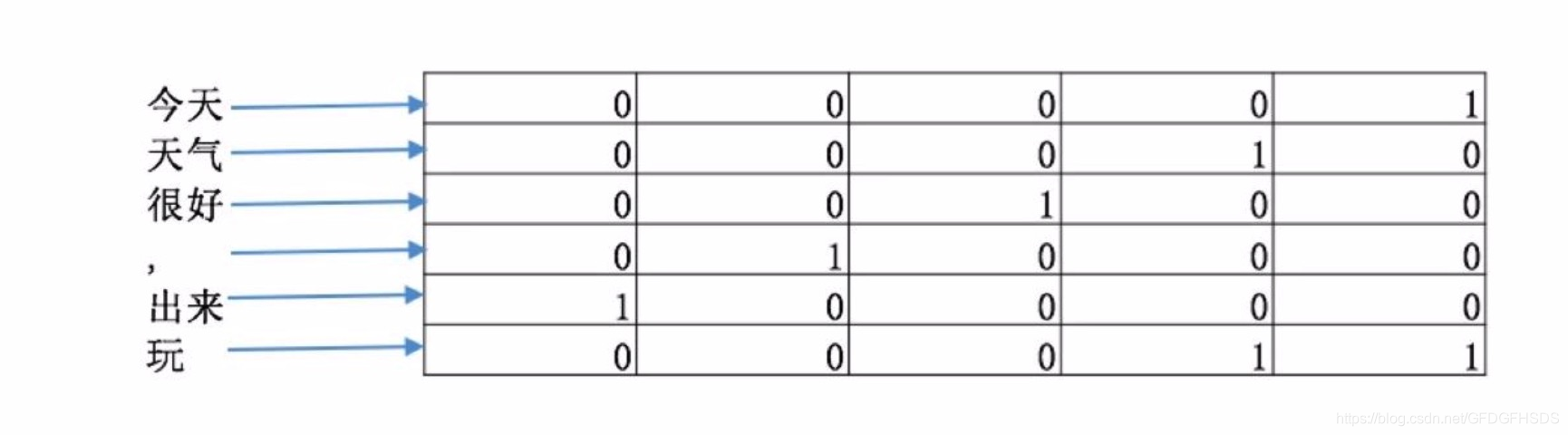
这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, nlp 当中目前最火热的研究方向便是如何将自然语言映射成更好的词向量。我们构建完词向量后,将所有的词向量拼接起来构成一个6*5的二维矩阵,作为最初的输入。
2.2 Convolution 卷积

卷积是一种数学算子。我们用一个简单的例子来说明一下
step.1 将 “今天”/“天气”/“很好”/"," 对应的4*5 矩阵 与卷积核做一个point wise 的乘法然后求和, 便是卷积操作:
feature_map[0] =0*1 + 0*0 + 0*1 + 0*0 + 1*0 + //(第一行)
0*0 + 0*0 + 0*0 + 1*0 + 0*0 + //(第二行)
0*1 + 0*0 + 1*1 + 0*0 + 0*0 + //(第三行)
0*1 + 1*0 + 0*1 + 0*0 + 0*0 //(第四行)
= 1
step.2 将窗口向下滑动一格(滑动的距离可以自己设置),“天气”/“很好”/","/“出来” 对应的4*5 矩阵 与卷积核(权值不变) 继续做point wise 乘法后求和
feature_map[1] = 0*1 + 0*0 + 0*1 + 1*0 + 0*0 + //(第一行)
0*0 + 0*0 + 1*0 + 0*0 + 0*0 + //(第二行)
0*1 + 1*0 + 0*1 + 0*0 + 0*0 + //(第三行)
1*1 + 0*0 + 0*1 + 0*0 + 0*0 //(第四行)
= 1
step.3 将窗口向下滑动一格(滑动的距离可以自己设置) “很好”/","/“出来”/“玩” 对应的4*5 矩阵 与卷积核(权值不变) 继续做point wise 乘法后求和
feature_map[2] = 0*1 + 0*0 + 1*1 + 1*0 + 0*0 + //(第一行)
0*0 + 1*0 + 0*0 + 0*0 + 0*0 + //(第二行)
1*1 + 0*0 + 0*1 + 0*0 + 0*0 + //(第三行)
0*1 + 0*0 + 0*1 + 1*0 + 1*0 //(第四行)
= 2
feature_map 便是卷积之后的输出, 通过卷积操作 将输入的65 矩阵映射成一个 31 的矩阵,这个映射过程和特征抽取的结果很像,于是便将最后的输出称作feature map。一般来说在卷积之后会跟一个激活函数,在这里为了简化说明需要,我们将激活函数设置为f(x) = x
2.3 关于channel 的说明

在CNN 中常常会提到一个词channel, 图三 中 深红矩阵与 浅红矩阵 便构成了两个channel 统称一个卷积核, 从这个图中也可以看出每个channel 不必严格一样, 每个4*5 矩阵与输入矩阵做一次卷积操作得到一个feature map. 在计算机视觉中,由于彩色图像存在 R, G, B 三种颜色, 每个颜色便代表一种channel。
根据原论文作者的描述, 一开始引入channel 是希望防止过拟合(通过保证学习到的vectors 不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。
不过使用多channel 相比与单channel, 每个channel 可以使用不同的word embedding, 比如可以在no-static(梯度可以反向传播) 的channel 来fine tune 词向量,让词向量更加适用于当前的训练。
对于channel在textCNN 是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集 单channel 的textCNN 表现都要优于 多channels的textCNN。
我们在这里也介绍一下论文中四个model 的不同
CNN-rand (单channel), 设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整.
CNN-static(单channel), 拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量.
CNN-non-static(单channel), pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调.
CNN-multiple channel(多channels), 类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来做.
Embedding: 第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution: 然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling: 第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax: 最后接一层全连接的 softmax 层,输出每个类别的概率。
2.4 max-pooling

得到feamap = [1,1,2] 后, 从中选取一个最大值[2] 作为输出, 便是max-pooling。max-pooling 在保持主要特征的情况下, 大大降低了参数的数目, 从图五中可以看出 feature map 从 三维变成了一维, 好处有如下两点:
降低了过拟合的风险, feature map = [1, 1, 2] 或者[1, 0, 2] 最后的输出都是[2], 表明开始的输入即使有轻微变形, 也不影响最后的识别。
参数减少, 进一步加速计算。
pooling 本身无法带来平移不变性(图片有个字母A, 这个字母A 无论出现在图片的哪个位置, 在CNN的网络中都可以识别出来),卷积核的权值共享才能.
max-pooling的原理主要是从多个值中取一个最大值,做不到这一点。cnn 能够做到平移不变性,是因为在滑动卷积核的时候,使用的卷积核权值是保持固定的(权值共享), 假设这个卷积核被训练的就能识别字母A, 当这个卷积核在整张图片上滑动的时候,当然可以把整张图片的A都识别出来。
2.5 使用softmax k分类

将 max-pooling的结果拼接起来, 送入到softmax当中, 就可得到各个类别比如 label 为1 的概率以及label 为-1的概率。如果是预测的话,到这里整个textCNN的流程遍结束了。
如果是训练的话,此时便会根据预测label以及实际label来计算损失函数, 计算出softmax 函数,max-pooling 函数, 激活函数以及卷积核函数 四个函数当中参数需要更新的梯度, 来依次更新这四个函数中的参数,完成一轮训练 。
通道(Channels):
图像中可以利用 (R, G, B) 作为不同channel;文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
图像是二维数据;文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
比如在情感分析场景,举个例子:“我觉得这个地方景色还不错,但是人也实在太多了”。
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
2.6 TextCNN模型超参数
首先,我们默认的模型超参数一般都是这种配置。如下表:

输入词向量表征:词向量表征的选取(如选word2vec还是GloVe)。
卷积核大小:一个合理的值范围在1~10。若语料中的句子较长,可以考虑使用更大的卷积核。另外,可以在寻找到了最佳的单个filter的大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往比单个最佳filter表现更出色。
feature map特征图个数:主要考虑的是当增加特征图个数时,训练时间也会加长,因此需要权衡好。当特征图数量增加到将性能降低时,可以加强正则化效果,如将dropout率提高过0.5。
激活函数:ReLU和tanh是最佳候选者。
池化策略:1-max pooling表现最佳。
正则化项(dropout/L2):相对于其他超参数来说,影响较小点。
2.7 textCNN的总结
本次我们介绍的textCNN是一个应用了CNN网络的文本分类模型。
- textCNN的流程:先将文本分词做embeeding得到词向量, 将词向量经过一层卷积,一层max-pooling,
最后将输出外接softmax 来做n分类。 - textCNN 的优势:模型简单, 训练速度快,效果不错。
- textCNN的缺点:模型可解释型不强,在调优模型的时候,很难根据训练的结果去针对性的调整具体的特征,因为在textCNN中没有类似gbdt模型中特征重要度(feature importance)的概念, 所以很难去评估每个特征的重要度。
- 不同维的卷积使用是根据卷积输入的数据来定,另外,当数据有多个channel时,也要进行相应处理。在文本分类中,主要是要注意一下和CV场景中不同的情况,卷积核不是一个正方形,是一个宽和word embedding相同、长表示n-gram的窗口。一个卷积层会使用多个不同大小的卷积核,往往是(3, 4, 5)这种类型。每一种大小的卷积核也会使用很多个。
2. 实现
基于Keras深度学习框架的实现代码如下:
import logging
from keras import Input
from keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding
from keras.models import Model
from keras.utils import plot_model
def textcnn(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None):
""" TextCNN: 1. embedding layers, 2.convolution layer, 3.max-pooling, 4.softmax layer. """
x_input = Input(shape=(max_sequence_length,))
logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60)
if embedding_matrix is None:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input)
else:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,
weights=[embedding_matrix], trainable=True)(x_input)
logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300)
pool_output = []
kernel_sizes = [2, 3, 4]
for kernel_size in kernel_sizes:
c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)
p = MaxPool1D(pool_size=int(c.shape[1]))(c)
pool_output.append(p)
logging.info("kernel_size: %s \t c.shape: %s \t p.shape: %s" % (kernel_size, str(c.shape), str(p.shape)))
pool_output = concatenate([p for p in pool_output])
logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6)
x_flatten = Flatten()(pool_output) # (?, 6)
y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2)
logging.info("y.shape: %s \n" % str(y.shape))
model = Model([x_input], outputs=[y])
if model_img_path:
plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False)
model.summary()
return model
**特征:**这里用的是词向量表示方式
**数据量较大:**可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
**数据量较小:**可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
**静态(static)方式:**训练过程中不再更新embeddings。实质上属于迁移学习,特别是在目标领域数据量比较小的情况下,采用静态的词向量效果也不错。(通过设置trainable=False)
**非静态(non-static)方式:**在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)
**plot_model()**画出的TextCNN模型结构图如下: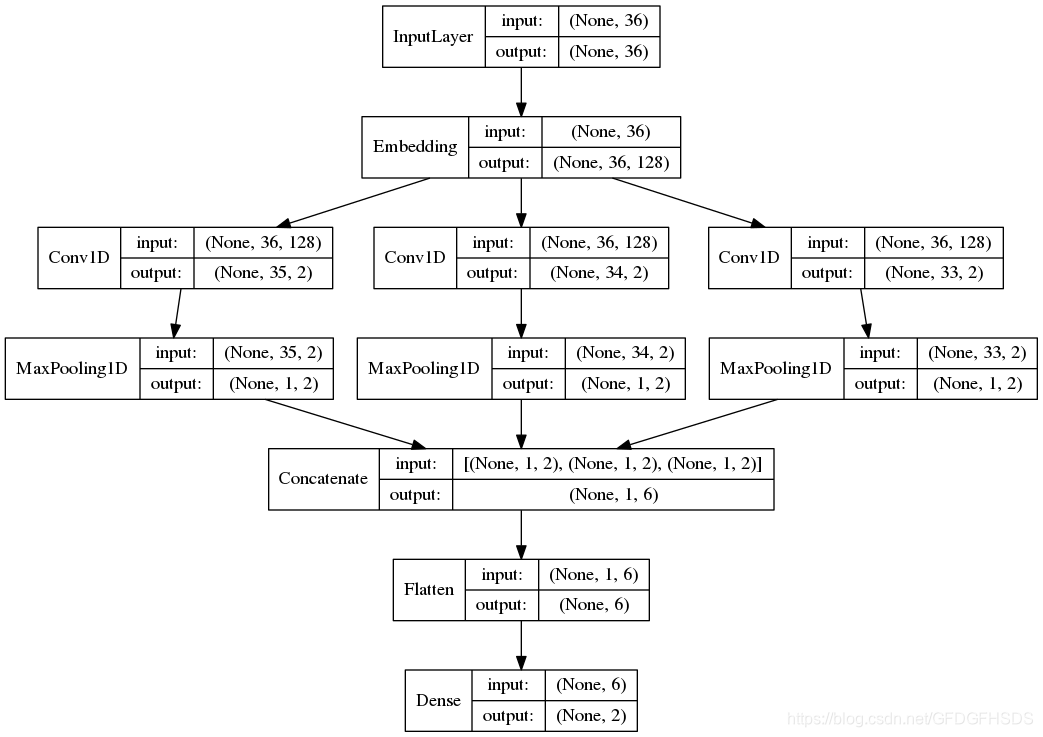
另外附上一维二维三维的卷积描述:

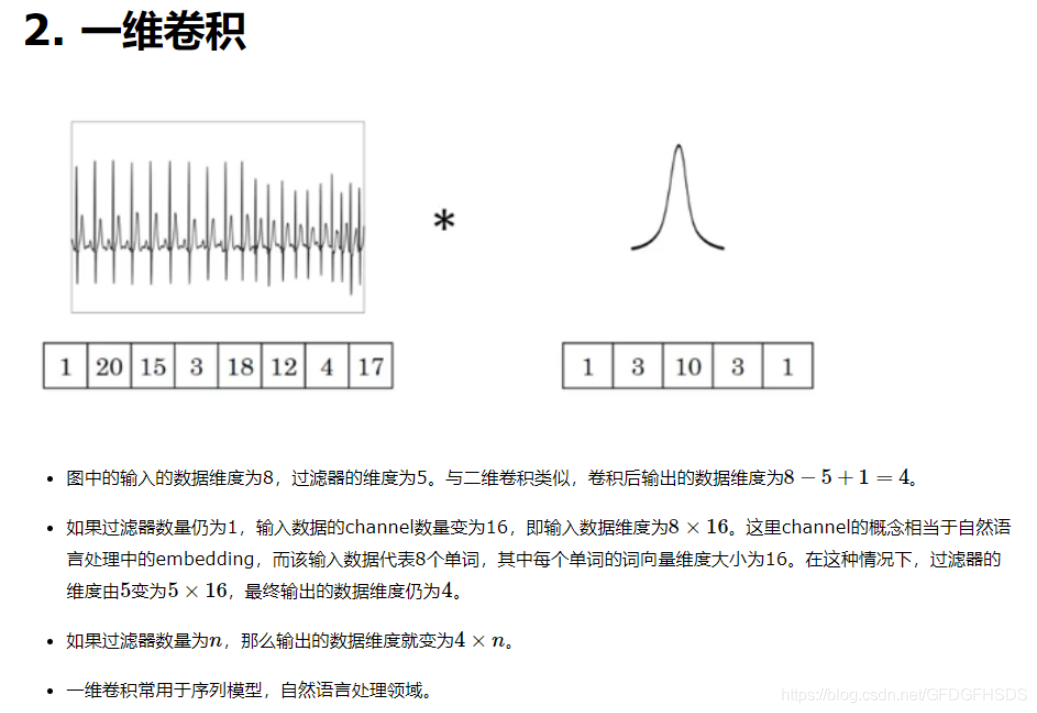

参考:
[NLP] TextCNN模型原理和实现
卷积神经网络(CNN)入门讲解
【原创】文本分类算法TextCNN原理详解(一)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)