
详解编辑距离算法-Levenshtein Distance
目录•写在前面•什么是编辑距离?•思路•思路可视化•代码实现•写在前面编辑距离算法被数据科学家广泛应用,是用作机器翻译和语音识别评价标准的基本算法。最简单的方法是检查所有可能的编辑序列,从中找出最短的一条。但这个序列总数可能达到指数级,但完全不需要这么多,因为我们只要找到距离最短的那条而不是所有可能的序列。这个概念是由俄罗斯科学家Vladimir Levenshtein...
目录
•写在前面
编辑距离算法被数据科学家广泛应用,是用作机器翻译和语音识别评价标准的基本算法。最简单的方法是检查所有可能的编辑序列,从中找出最短的一条。但这个序列总数可能达到指数级,但完全不需要这么多,因为我们只要找到距离最短的那条而不是所有可能的序列。这个概念是由俄罗斯科学家Vladimir Levenshtein在1965年提出来的,所以也叫 Levenshtein 距离。总是比较相似的,或多或少我们可以考虑编辑距离。我们在解决这个问题中,使用动态规划的思想进行求解。
•什么是编辑距离?
这里给一个题目的描述:给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。你可以对一个单词进行如下三种操作。
- 插入一个字符
- 删除一个字符
- 替换一个字符
为了更好的理解,我这里给出两个示例,帮助理解这个概念
示例一:
输入: word1 = "horse", word2 = "ros"
输出: 3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')示例二:
输入: word1 = "intention", word2 = "execution"
输出: 5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')•思路
我们的目的是让问题简单化,比如说两个单词 horse 和 ros 计算他们之间的编辑距离 D,容易发现,如果把单词变短会让这个问题变得简单,很自然的想到用 D[n][m] 表示输入单词长度为 n 和 m 的编辑距离。具体来说,D[ i ][ j ] 表示 word1 的前 i 个字母和 word2 的前 j 个字母之间的编辑距离。
更通俗的理解,假设我们可以使用d[ i , j ]个步骤(可以使用一个二维数组保存这个值,使用动态规划的思想),表示将串s[ 1…i ] 转换为串t [ 1…j ]所需要的最少步骤个数,那么,在最基本的情况下,即在 i 等于 0 时,也就是说串 s 为空,那么对应的d[ 0 , j ] 就是 增加 j 个字符,使得 s 转化为 t,在 j 等于 0 时,也就是说串 t 为空,那么对应的 d[ i, 0] 就是 减少 i 个字符,使得 s 转化为 t。
更一般的情况,加一点动态规划的想法,我们要想得到将 s[1..i] 经过最少次数的增加,删除,或者替换操作就转变为 t[1..j],那么我们就必须在之前可以以最少次数的增加,删除,或者替换操作,使得现在串 s 和串 t 只需要再做一次操作或者不做就可以完成 s[1..i] == t[1..j] 的转换。所谓的“之前”分为下面三种情况:
- 要得到 s[1…i] == t[1…j-1],需要 k 个操作
- 要得到 s[1..i-1] == t[1..j],需要 k 个操作
- 要得到 s[1…i-1] == t [1…j-1],需要 k 个操作
在上面的这三种情况的基础下,我们需要得到 s[1..i] == t[1..j] ,我们分别给出解决思路,如下
- 第1种情况,只需要在最后将 t[1…j-1] 加上 s[i] 就完成了匹配,这样总共就需要 k+1 个操作。
- 第2种情况,只需要在最后将 s[1..i-1] 加上 t[j] 就完成了匹配,所以总共需要 k+1 个操作。
- 第3种情况,只需要在最后将 s[ i ] 替换为 t[ j ],使得满足 s[1..i] == t[1..j],这样总共也需要 k+1 个操作。
特别注意:而如果在第3种情况下,s[i]刚好等于t[j],那我们就可以仅仅使用k个操作就完成这个过程。
最后,为了保证得到的操作次数总是最少的,我们可以从上面三种情况中选择消耗最少的一种最为将s[1..i]转换为t[1..j]所需要的最小操作次数。我们把储存k的二维数组命名为 D[ ][ ] ,显而易见,当我们获得 D[i-1][j],D[i][j-1] 和 D[i-1][j-1] 的值之后就可以计算出 D[i][j]。
如果两个子串的最后一个字母相同,即word1[i] = word2[i] 的情况下:
如果两个子串的最后一个字母不相同,即word1[i] != word2[i] 我们将考虑替换最后一个字符使得他们相同:
•思路可视化
在上面的思路描述下,我们大致能够理解了,当然,如果还是有点迷糊的,这里我将思路用表格一步一步的表示出来,帮助理解。首先我们先初始化一个二维数组,如下。“.” 代表空串。第一行和第一列按照个数进行初始化,这一步要想明白,想明白了之后就好理解了。
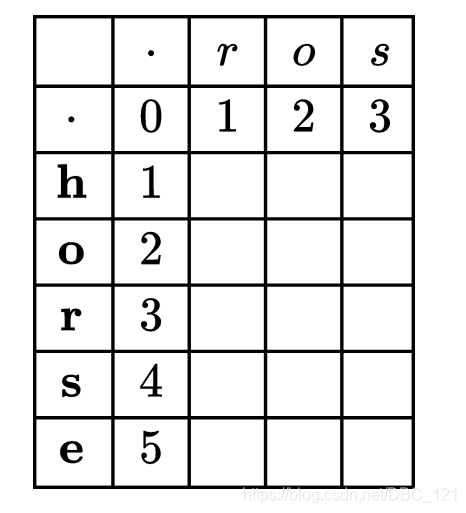
如果两个子串的最后一个字母相同,即word1[i] = word2[i] 的情况下:
,图形如下。


如果两个子串的最后一个字母不相同,即word1[i] != word2[i] 我们将考虑替换最后一个字符使得他们相同:
,图形如下。
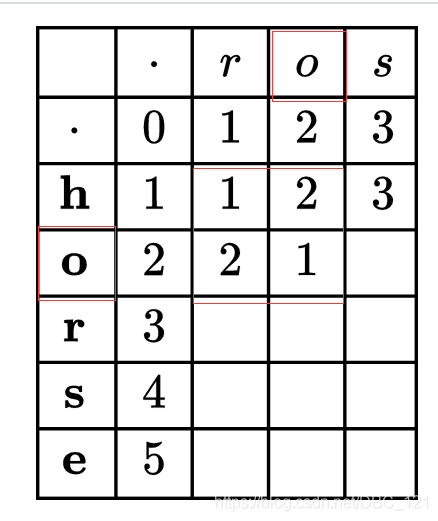
最后我们会得到如下的结果,二维数组最后的 3 就是我们的答案。

•代码实现
public int minDistance(String word1, String word2){
int n = word1.length();
int m = word2.length();
if(n * m == 0)
return n + m;
int[][] d = new int[n + 1][m + 1];
for (int i = 0; i < n + 1; i++){
d[i][0] = i;
}
for (int j = 0; j < m + 1; j++){
d[0][j] = j;
}
for (int i = 1; i < n + 1; i++){
for (int j = 1; j < m + 1; j++){
int left = d[i - 1][j] + 1;
int down = d[i][j - 1] + 1;
int left_down = d[i - 1][j - 1];
if (word1.charAt(i - 1) != word2.charAt(j - 1))
left_down += 1;
d[i][j] = Math.min(left, Math.min(down, left_down));
}
}
return d[n][m];
}

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 44
44 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)