
R语言卡方检验与结果可视化---ggstatsplot包
R语言卡方分析与结果可视化1,卡方分析简介2,R语言chisq.test()3,基于ggstatsplot包的可视化分析
R语言卡方检验与结果可视化
1,卡方分析简介与实例
2,R语言chisq.test()
3,基于ggstatsplot包的可视化分析
卡方分析简介与实例:
卡方检验是生物学中应用很广的一种假设检验,可以通过对构成比,率进行检验,进而判断分类资料间的偏差程度。若卡方值越大,二者偏差程度越大;反之,二者偏差越小。其中卡方分析的原假设是观察频数与期望频数无差别,所以说当p值显著时,则拒绝原假设,认为二者之间有明显差异。总而言之,卡方分析即是用来判断两个样本间的差异程度,从而推断两个变量之间有没有关系。
一般常见的卡方分析是2x2列联表形式,例如服用某种药物是否对死亡率有影响:(自己编的数据)

简单统计之后,得到总数和死亡率:

原假设是:服药组和未服药组之间频数无显著差异(服药对死亡率无影响)
先计算自由度:(行数-1)*(列数-1)=1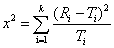
这个是卡方的计算公式,R代表实际值,T代表理论值,理论值需要进一步计算才可以知道。
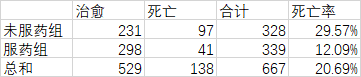
此处理论的死亡率就是20.69%,根据该数值计算出各个值的理论值:未服药组【治愈:328x(1-0.2069),死亡:328x0.2069】服药组同理也可以计算出结果,得到:
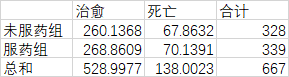
根据公式计算出卡方的值:
x2=(231-260.1368)2/260.1368+(97-67.8632)2/67.8632+(298-268.8609)2/268.8609+(41-70.1391)2/70.1391=31.03711
查表可知在自由度为1的情况下,临界概率是:3.84(95%),显然31.03711>3.84,远超卡方分布的临界值,同时31.03711>10.83(99.9%),对此我们便能得到结论,服药组和未服药组间有显著差异。
R语言chisq.test()
在R语言中进行卡方检验还是十分方便的,只需要使用chisq.test即可实现,可以返回卡方值和对应的p值,同时还可以计算自由度。但是其对数据集的格式有一定的要求,如图所示为实际的操作步骤:
>治愈<-c(231,298)
>死亡<-c(97,41)
>data<-data.frame(治愈,死亡,row.names = c("未服药组","服药组"))
>chisq.test(data)
Pearson's Chi-squared test with Yates' continuity correction
data: data
X-squared = 29.981, df = 1, p-value = 4.362e-08
>data
治愈 死亡
未服药组 231 97
服药组 298 41
此处为2X2列链表的实例,在实际生活中,往往需要将结果反应到图像上,一般采用prism8或AI来制图,在R语言中ggstatsplot包也可以实现在这方面的功能。
基于ggstatsplot包的可视化分析
ggstatsplot包常用于各种检验的可视化制图中,在这里只简单介绍关于卡方分析的可视化。此处需要使用到ggbarstats函数,其参数可谓是非常的多,详细的参数表我放在另一个博客中了,有兴趣的朋友可以去看看(https://blog.csdn.net/m0_45248682/article/details/104086729)。务必记住ggbarstats函数对数据集的要求不同于chisq.test,它只能接受比率或者原始的统计数据,详细的将举例说明:
> head(mtcars) #原始数据集
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
> table(mtcars$vs) #频数统计(chisq.test使用)
0 1
18 14
在此处若只有下图的原始的数据则需要转换一下(不知道有没有更简单的方法,向大家请教一下)
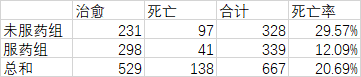
数据处理:
> status<-c(rep("治愈",231),rep("治愈",298),rep("死亡",97),rep("死亡",41))
> group<-c(rep("未服药组",231),rep("服药组",298),rep("未服药组",97),rep("服药组",41))
> data<-data.frame(status,group)
调用ggstatsplot包:(计算出95%置信区间并标记p值)
> ggstatsplot::ggbarstats(
+ data = data,
+ main = status,
+ nboot = 10,condition = group,
+ legend.title = "Group"
+ )
Note: 95% CI for effect size estimate was computed with 10 bootstrap samples.
# A tibble: 2 x 11
group counts perc N 死亡 治愈 statistic p.value parameter method significance
<fct> <int> <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr> <chr>
1 未服药组 328 49.2 (n = 328) 29.57% 70.43% 54.7 1.37e-13 1 Chi-squared test for given probabilities ***
2 服药组 339 50.8 (n = 339) 12.09% 87.91% 195. 2.80e-44 1 Chi-squared test for given probabilities ***
 可以看见p值以及卡方值都被标注出来了,同时还可以通过title参数来加入标题,还可以转化绘图类型(从堆砌直方图转化为饼图)。
可以看见p值以及卡方值都被标注出来了,同时还可以通过title参数来加入标题,还可以转化绘图类型(从堆砌直方图转化为饼图)。
详细的参数以及说明已经放到另一篇博文中了,有兴趣的朋友可以打开看看。
https://blog.csdn.net/m0_45248682/article/details/104086729
参考文献:
https://www.jianshu.com/p/6547fa7e97c1
https://www.meiwen.com.cn/subject/qfmmvftx.html

鸿蒙生态一站式服务平台。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)