
矩阵归一化的处理原理和方法
矩阵归一化的两种方式最近一直在学习机器学习和人工神经网络,总是设计矩阵的归一化处理,以达到无量纲的效果。一直是调用函数包,没有去研究其原理,今天遇到了问题,研究了下。这里说的矩阵归一化是两个层面的应用及其对应的处理方法,原理不同,公式不同,应用场景也不同。在数据处理中的归一化原理数据处理的归一化就是将矩阵的数据以列为单元,按照一定比例,映射到某一区间,当然这里说的归一化是狭义的归一化,不包...
矩阵归一化的两种方式
最近一直在学习机器学习和人工神经网络,总是设计矩阵的归一化处理,以达到无量纲的效果。一直是调用函数包,没有去研究其原理,今天遇到了问题,研究了下。这里说的矩阵归一化是两个层面的应用及其对应的处理方法,原理不同,公式不同,应用场景也不同。
在数据处理中的归一化
原理
数据处理的归一化就是将矩阵的数据以列为单元,按照一定比例,映射到某一区间,当然这里说的归一化是狭义的归一化,不包含标准化,单纯的说归一化:
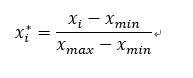
其中的字母含义就不解释了
当然这只是映射到(0,1)之间,常用的还有(-1,1)之间,当然其他任何区间都可以。一般神经网络都是(0,1)之间。
(m,n)之间的公式大家也应该会推导:
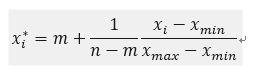
不多解释。神经网络归一化是为了无量纲化,达到均衡各类特征值的影响,但是最后的结果还是要反归一化,才能和原数据的对照。
实现
实现的方法很多,当然你可以一步一步拿numpy库去编写,来训练你的python能力,最快的方法是调用sklearn的函数,直接上代码。
from sklearn.preprocessing import MinMaxScaler
import numpy as pd
scalar = MinMaxScaler(feature_range=(0, 1)) # 加载函数
a = pd.array([[2, 4, 12, 8], [1, 5, 3, 2], [3, 23, 4, 14]]) # 随机的矩阵
b = scalar.fit_transform(a) # 归一化
print(b)
c = scalar.inverse_transform(b) # 反归一化
print©
运行结果为:
[[0.5 0. 1. 0.5 ]
[0. 0.05263158 0. 0. ]
[1. 1. 0.11111111 1. ]]
[[ 2. 4. 12. 8.]
[ 1. 5. 3. 2.]
[ 3. 23. 4. 14.]]
一定记住,按照行计算的。
不会插入python代码,不好意思,以后就会了。
在数学中的归一化
数学中,矩阵的列归一化,就是将矩阵每一列的值,除以每一列所有元素平方和的绝对值,这样做的结果就是,矩阵每一列元素的平方和为1了。
举个例子,矩阵[1,2,3],将其归一化的结果就是[0.2673,0.5345,0.8018]。其平方和就为1了。
有没有发现这种情况下就不会有0和1两个数了,前提是全是正数的数据。
这个做法很简单,感兴趣的小伙伴可以去探索,我还是去学习神经网络把。
加油!
会把代码加到博客上的伙伴可以给我留言,谢谢!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)