ASRT中文语音识别系统
系统流程1.特征提取输入:语音.wav操作:分帧加窗等操作输出:语谱图(二维频谱图像信号)2.声学模型参考VGG的深度卷积神经网络- 输入:语谱图- 操作:VGG模型训练- 输出:VGG输出3.CTC解码输入:VGG输出输出:汉语拼音序列4.语言模型基于概率图的最大熵隐马尔可夫模型输入:汉语拼音序列操作:隐含马尔可夫链输出:汉字文本无需...
项目:ASRT_SpeechRecognition
学习中…持续更新
系统流程
1.特征提取
- 输入:语音.wav
- 操作:分帧加窗等操作
- 输出:语谱图(二维频谱图像信号)
2.声学模型
- 参考VGG的深度卷积神经网络
- 输入:语谱图
- 操作:VGG模型训练
- 输出:VGG输出
3.CTC解码
- 输入:VGG输出
- 输出:汉语拼音序列
4.语言模型
- 基于概率图的最大熵隐马尔可夫模型
- 输入:汉语拼音序列
- 操作:隐含马尔可夫链
- 输出:汉字文本
- 无需中文分词算法的简单词频统计
def sub_run(path, n): # n 记录每次切片的一组中包含的字符数
f1 = open(path, 'rb')
stxt = f1.read()
stxt = str(stxt, 'utf-8')
f1.close()
tmp_str = {}
for i in list(range(len(stxt) - 1)):
tmp_str[stxt[i:i + n]] = 0
for i in list(range(len(stxt) - 1)):
tmp_str[stxt[i:i + n]] += 1
#print(tmp_str.items())
tmp_str = sorted(tmp_str.items(), key=lambda d: d[1], reverse=True)
print('*****' + str(n) + '字符***************')
print(tmp_str)
print('*************************')
代码目录结构
general_function
-
file_dict.py
- 函数:GetSymbolList_trash(“路径”)
- 功能:加载dict.txt文件中的拼音符号列表,用于标记符号
- 返回:list_symbol列表,[a1,a2,a3…pou2,_]
- 函数:GetSymbolList_trash(“路径”)
-
file_wav.py
-
函数:read_wav_data(“一条语音.wav”)
- 功能:读取一个wav文件
- 输入:
语音.wav文件
- 返回:
wave_date,fs
wave_data:(声道数,帧数)语音信号的时域谱矩阵(一声道为一行)
fs: 帧速率/采样率
-
函数:GetMfccFeature(音频信号数据矩阵wave_data,采样率fs)
-
关于MFCC:Python之python_speech_features
- 功能:获取语音信号的mfcc特征
- 返回值:mfcc特征向量的矩阵、一阶差分矩阵、二阶差分矩阵
-
函数:GetFrequencyFeature(音频信号数据矩阵wave_signal,采样率fs)
- 功能:获取输入语音信号的特征矩阵(语谱图)
- 输入:
wave_data,fs - 输出:
FrequencyImg语谱图:大小为(特征数量,窗口数)的矩阵,如(200, 978)
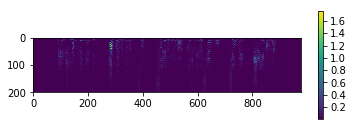
-
函数:get_wav_list(filename)
- 返回:从wavlist文件中获取的wav字典(语音id,语音路径)、语音id列表
-
函数:get_wav_symbol(filename)
- 返回:从symbollist文件中获取的拼音字典(语音id,语音路径)、语音列表
-
test.py
- 功能:测试整个语音识别系统
- 流程:
- 初始化语音模型:
ms = ModelSpeech(datapath)- _init_():初始化
- CreateModel():创建模型,CNN/LSTM/CTC模型
- 加载训练好的语音模型:
ms.LoadModel(speech_model251.model) - 读取音频文件,返回拼音序列:
r = ms.RecognizeSpeech_FromFile('20170001P00241I0052.wav')- read_wav_data():读音频文件
- RecognizeSpeech():语音处理
- GetFrequencyFeature3():获取音频特征
- Predict():预测结果,返回拼音序列
- 加载语言模型:
ml = ModelLanguage('model_language') ml.LoadModel()- GetLanguageModel():读取语音模型文件,返回模型
- 将拼音序列传入语言模型,得到语音识别结果:
r = ml.SpeechToText(str_pinyin)
- 初始化语音模型:
train_mspeech.py
用于训练语音模型
- 创建模型
ms = ModelSpeech(datapath) - 训练模型
ms.TrainModel(datapath, epoch = 50, batch_size = 16, save_step = 500)- 参数:datapath数据保存路径、epoch迭代轮数、batch_size、每save_step步保存一次模型。
readdata.py
DataSpeech类
- init(路径path,数据集类型type=train/dev/test)
- 调用LoadDataList()加载数据列表
- 属性如下:
datapath数据存放根目录
type数据集类型
dic_wavlist_thchs30:thchs30数据集(语音id,语音路径)字典
dic_symbollist_thchs30:thchs30数据集(语音id,拼音列表)字典
dic_wavlist_stcmds:stcmds数据集(语音id,语音路径)字典
dic_symbollist_stcmds:stcmds数据集(语音id,拼音列表)字典
list_wavnum_thchs30:thchs30数据集(语音id)列表
list_wavnum_stcmds:stcmds数据集(语音id)列表
list_symbolnum_thchs30:thchs30数据集(语音id)列表,同list_wavnum_thchs30
list_symbolnum_stcmds:stcmds数据集(语音id)列表,同list_wavnum_stcmds
SymbolNum:记录拼音符号数量
list_symbol:全部汉语拼音符号列表GetSymbolList()读dict.txt
list_wavnum:wav文件标记列表
list_symbolnum:symbol标记列表
DataNum:记录数据量
-
函数:LoadDataList()
根据type属性加载用于计算的数据列表
读取thchs30和stcmds数据集的wavalist(语音id 语音路径)和symbollist(语音id 拼音) -
函数:GetDataNum()
获取thchs30和stcmds数据集的总数据量
当wav数量和symbol数量一致的时候返回正确的值,否则返回-1,代表出错。 -
函数:GetData()
- 功能:读取数据,返回神经网络输入值和输出值矩阵(可直接用于神经网络训练的那种)
- 参数:
n_start:从编号为n_start数据开始选取数据
n_amount:选取的数据数量,默认为1,即一次一个wav文件 - 返回:data_input语音的特征矩阵(三维,原始二维加一维),和神经网络输出值标签(语音对应的拼音序号数组)
-
函数:data_genetator(batch_size=32, audio_length = 1600)
数据生成器函数,用于Keras的generator_fit训练。
yield [X, y, input_length, label_length ], labels -
函数:GetSymbolList()
- 从文件dict.txt中加载拼音符号列表,用于标记符号
- 返回一个列表list_symbol:[a1,a2,a3…,_]
-
函数:GetSymbolNum()
返回拼音符号列表的大小len(self.list_symbol) -
函数:SymbolToNum()
拼音符号转位数字,即该拼音在list_symbol中的位置 -
函数:NumToVector()
数字转为对应的one-hot向量
SpeechModel.py
语音模型类
- 函数:CreateModel()
定义CNN/LSTM/CTC模型,使用函数式模型
输入层:200维的特征值序列,一条语音数据的最大长度设为1600(大约16s)
隐藏层:卷积池化层,卷积核大小为3x3,池化窗口大小为2
隐藏层:全连接层
输出层:全连接层,神经元数量为self.MS_OUTPUT_SIZE,使用softmax作为激活函数,
CTC层:使用CTC的loss作为损失函数,实现连接性时序多输出
-
函数:ctc_lambda_func()
- 返回
K.ctc_batch_cost(labels, y_pred, input_length, label_length)
- 返回
-
函数:TrainModel()
- 功能:训练模型
参数:
datapath: 数据保存的路径
epoch: 迭代轮数
save_step: 每多少步保存一次模型
filename: 默认保存文件名,不含文件后缀名 -
函数:LoadModel()
加载模型参数 -
函数:SaveModel()
保存模型参数 -
函数:TestModel()
使用编辑距离测试模型错误率 -
函数:Predict()
- 返回:语音识别后的拼音符号列表
-
函数:RecognizeSpeech()

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)