
mysql详解(持续更新)
去重语句:select distinct 列名 from 表名字符类型转数值类型语句:select to_number('000123') from dual;插入语句:insert into 表名(字段)values(字段值)新增表字段:alter table 表名 add (字段名 integer default 0 not null);删除表字段:alter.................
in、exists、case when、insert into select
库表基础属性
-
数据库字符集
Mysql默认的字符集编码是Latin1,其不支持中文,所以建库时需要进行设置charset=utf8
-
数据库变量
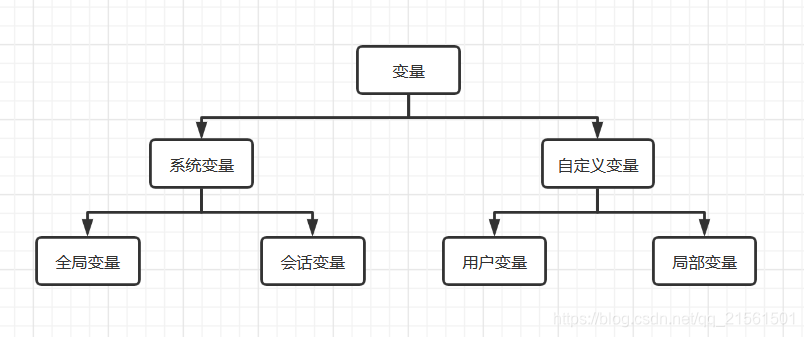
变量分为,系统变量和自定义变量两种。系统变量是由系统提供,不是用户定义,属于服务器层面;自定义变量则是用户自定义的。系统变量下有全局变量和会话变量。服务器每次启动将为所有的全局变量赋初始值,针对于所有的会话(连接)有效,但不能跨重启,而会话变量则仅仅针对于当前会话(连接)有效。
-
全局变量使用示例
语句 内容 show global variables; 查看所有的系统变量 show global variables like ‘%char%’; 查看满足条件的部分系统变量 select @@global.系统变量名; 查看指定的某个系统变量的值 set @@global.系统变量名=值; 为某个系统变量赋值 set global 系统变量名=值; 为某个系统变量赋值 -
会话变量使用示例
语句 内容 show session variables; 查看所有的会话变量 show session variables like ‘%char%’; 查看满足条件的部分会话变量 select @@session.tx_isolation; 查看指定的某个会话变量的值 set @@tx_isolation=‘’ ; 为某个会话变量赋值 set session tx_isolation=‘’; 为某个会话变量赋值
[注]如果是全局级别,则需要加global,如果是会话级别,则需要加session,如果不写,默认session
自定义变量分为用户变量和局部变量。用户变量针对于当前会话(连接)有效,同于会话变量的作用域,可应用在任何地方,也就是begin end 里面或begin end外面;局部变量则仅仅在定义它的begin end 中有效,应该再 begin end中的第一句话!
-
用户变量使用示例
-
声明并初始化
方式一:set @用户变量名=值;
方式二:set @用户变量名:=值;
方式三:select @用户变量名:=值;
-
使用变量
select @用户变量名;
-
-
局部变量使用示例
-
声明变量
方式一:declare 变量名 类型;
方式二:declare 变量名 类型 default 值 ;
-
赋值变量
方式一:set @局部用户变量名=值 ;
方式二:set @局部用户变量名:=值 ;
方式三:select @局部用户变量名 :=值 ;
-
使用变量
select 局部变量名;
-
-
-
表字段属性
1)默认:设置默认的值,如sex,默认值为男,如果不指定该列的值,则会有默认的值
2)自动递增:自动在上一条记录的基础上+1(默认),通常用来设计唯一的主键 index ,必须是整数类型,可以自定义设计主键自增的起始值和步长
3)无符号:无符号的整数,声明了该列不能声明负数
4)填充零:不足的位数,使用0来填充,如int(3),存5 ,005
5)不是null:设置为 not null,如果不给它赋值,就会报错;null,如果不填写值,默认就是null
sql的类别有:
• DDL(data Definition Language) 数据定义语言:用来定义数据库对象:库、表、列 等。关键字:create ,drop ,alter 等
• DML(data Manipulation Language) 数据操作语言:用来对数据库中表的数据进行增删改,关键字:insert, delete ,update 等
• DQL(data Query Language) 数据查询语言:用来查询数据库中表的记录(数据)。关键字:select where 等
• DCL(data Control Language) 数据控制语言:用来定义数据库的访问权限和安全级别,及创建用户,关键字:GRANT ,REVOKE 等
DDL(data Definition Language) 数据定义语言
数据库操作
-
创建数据库
#创建数据库 create database 数据库名称; #创建数据库,判断为不存在,再创建 create database if not exists 数据库名称; #创建数据库,判断为不存在,在创建,并制定字符集为gbk create database if not exists 数据库名称 character set gbk; -
显示数据库
#查询所有数据库的名称 show databases; #查询当前正在使用的数据库 select database (); #查询某个数据库的字符集:查询某个数据库的创建语句 show create database 数据库名称; -
修改数据库
#修改数据库的字符集 alter database 数据库名称 character set 字符集名称; -
删除数据库
#删除数据库 drop database 数据库名称; #判断数据库为存在,再删除数据库 drop database if exists 数据库名称;[注]使用数据库命令:
use 数据库名称;
建表规范
名字
建表的时候,给 表、字段、索引 起个好的名字能够提高沟通和降低维护成本。名字要遵守如下规范:
1. 见名知意:如:user_name
2. 大小写:尽量都用小写,小写字母更容易让人读懂
3. 分隔线:多个单词间采用_分隔,如:product_name
4. 表名:带上业务前缀,如果是订单相关的业务表,可以在表名前面加个前缀order_
5. 索引名:每张表的主键只有一个,一般使用id或者sys_no命名,普通索引和联合索引,其实是一类。在建立该类索引时,可以加ix_前缀,如:ix_product_status;唯一索引,可以加ux_前缀,比如:ux_product_code
字段类型
| 数据类型 | 作用 | 占字节数 |
|---|---|---|
| tinyint | 非常小的数据 | 1个字节 |
| smallint | 较小的数据 | 2个字节 |
| mediumint | 中等大小的数据 | 3个字节 |
| int | 标准的整数 | 4个字节 |
| bigint | 较大的数据 | 8个字节 |
| float | 浮点数 | 4个字节 |
| double | 浮点数 | 8个字节(精度问题) |
| decimal | 字符串形式的浮点数 金融计算的时候,一般使用decimal | |
| char | 定长字符串,长度是固定的 | 字符串固定大小的0~255 |
| varchar | 可变长字符串,长度是可变的 | 可变字符串0~65535 |
| tinytext | 微型文本 | 2^8-1 |
| text | 用于存储大字符串,且有一个字符集,根据字符集的校对规则对值进行排序和比较 | 2^16-1 |
| date | 日期格式 | |
| time | 时间格式 | |
| datetime | 最常用的时间格式 | |
| timestamp | 时间戳 | |
| year | 年份格式 | |
| null | 未知 |
在navicat如下所处位置:
相关字段的异同
1. char 和 varchar
char:• char表示定长字符串,长度是固定的;
• 如果插入数据的长度小于char的固定长度时,则用空格填充;
• 因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
• 对于char来说,最多能存放的字符个数为255,和编码无关
varchar:• varchar表示可变长字符串,长度是可变的;
• 插入的数据是多长,就按照多长来存储;
• varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
• 对于varchar来说,最多能存放的字符个数为65532
[注]日常的设计,对于长度相对固定的字符串,可以使用char,对于长度不确定的,使用varchar更合适一些。
2. DateTime 和 TimeStamp
相同点: • 两个数据类型存储时间的表现格式一致。均为 YYYY-MM-DD HH:MM:SS
• 两个数据类型都包含「日期」和「时间」部分
• 两个数据类型都可以存储微秒的小数秒(秒后6位小数秒)
区 别: • DATETIME 的日期范围是 1000-01-01 00:00:00.000000 到 9999-12-31 23:59:59.999999;
TIMESTAMP 的时间范围是1970-01-01 00:00:01.000000 UTC 到 ``2038-01-09 03:14:07.999999 UTC
• 存储空间:DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节
• 时区相关:DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区
• 默认值:DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
空间字段的拓展
mysql空间还扩展支持几何数据的存储、生成、分析、优化
MySQL支持以下数据类型(存储):
| 数据类型 | 说明 |
|---|---|
| Geometry | 是几何对象的基类, 也就是说Point, LineString, Polygon都是Geometry的子类 |
| Point | (简单点)有一个坐标值,没有长度、面积、边界。数据格式为『经度(longitude)在前,维度(latitude)在后,用空格分隔』 例: POINT(121.213342 31.234532) |
| LineString | (简单线)由一系列点连接而成。如果线从头至尾没有交叉,那就是简单的(simple)、如果起点和终点重叠,那就是封闭的(closed)数据格式为『点与点之间用逗号分隔;一个点中的经纬度用空格分隔,与POINT格式一致』例:LINESTRING(121.342423 31.542423,121.345664 31.246790,121.453178 31.456862) |
| POLYGON | (简单面)多边形对象。可以是一个实心平面形,即没有内部边界,也可以有空洞,类似纽扣.数据格式为『实心型: 一个表示外部边界的LineString和0个表示内部边界的LineString组成』例:POLYGON((121.342423 31.542423,121.345664 31.246790,121.453178 31.456862),(121.563633 31.566652,121.233565 31.234565,121.568756 31.454367));『纽扣型: 一个表示外部边界的LineString和多个表示内部边界的LineString组成』例: POLYGON((0 0,10 0, 10 10, 0 10)) |
| MultiPoint | 多点对象的集合 |
| MULITILINESTRING | 多线对象的集合 |
| MUILITIPOLYGON | 很多方面对象的集合 |
| GEOMETRYCOLLECTION | 任何几何集合对象的集合 |
在创建表的时候可以根据需求选择合适的几何类型存储你的空间数据。
空间数据类型生成
MySQL支持WKB,WKT数据生成空间数据类型,提供如下函数:
GeomFromText(wtk [,srid)PointFromText LINESTRINGFROMTEXT …
GeomFromWKB(wtk [,srid)GeomFromWKB GeomFromWKB …
建表约束
用于对表中的数据进行限定,保证数据的正确性,有效性和完整性,根据特点可分为四种:
-
SQL主键约束
要知道SQL中的主键是什么。表由列和行组成,通常,表具有一列或多列,列的值唯一地标识表中的每一行, 此列或多列称为主键。由两列或更多列组成的主键也称为复合主键。
每个表都有一个且只有一个主键。 主键不接受NULL或重复值。如果主键由两列或更多列组成,则值可能在一列中重复,但主键中所有列的值组合必须是唯一的。
通常,在创建表时定义主键。 如果主键由一列组成,则可以使用PRIMARY KEY约束作为列或表约束。 如果主键由两列或更多列组成,则必须使用PRIMARY KEY约束作为表约束。
建表时有两种方式定义主键:
• 在列定义中添加PRIMARY KEY
CREATE TABLE projects ( project_id INT PRIMARY KEY, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL );• 不使用PRIMARY KEY约束作为列约束,而是使用表约束
--CREATE TABLE语句末尾的CONSTRAINT子句将project_id列指定为主键。 CREATE TABLE projects ( project_id INT, project_name VARCHAR(255), start_date DATE NOT NULL, end_date DATE NOT NULL, CONSTRAINT pk_id PRIMARY KEY (project_id) );当主键由两列或以上组成时,必须使用PRIMARY KEY作为表约束。
CREATE TABLE project_assignments ( project_id INT, employee_id INT, join_date DATE NOT NULL, CONSTRAINT pk_assgn PRIMARY KEY (project_id , employee_id) );在初建表没有定义主键的话(尽管这不是一个好习惯),可以使用ALTER TABLE语句将主键添加到表中。
例如,以下语句创建没有主键的project_milestones表。
CREATE TABLE project_milestones( milestone_id INT, project_id INT, milestone_name VARCHAR(100) );现在,可以使用以下ALTER TABLE语句将milestone_id列设置为主键。
ALTER TABLE project_milestones ADD CONSTRAINT pk_milestone_id PRIMARY KEY (milestone_id);一般很少删除表的主键。 但是,如果必须这样做,可以使用ALTER TABLE语句,如下所示:
ALTER TABLE table_name DROP CONSTRAINT primary_key_constraint;例如,要删除project_milestones表的主键约束,请使用以下语句。
ALTER TABLE project_milestones DROP CONSTRAINT pk_milestone_id; -
SQL外键约束
-
SQL唯一约束
唯一约束即UNIQUE约束,有时,希望确保一列或多列中的值不重复。 例如,employees表中不能接受的重复电子邮件。由于电子邮件列不是主键的一部分,因此防止电子邮件列中重复值的唯一方法是使用UNIQUE约束。
根据定义,SQL UNIQUE约束定义了一个规则,该规则可防止存储在不参与主键的特定列中有重复值。
要注意,PRIMARY KEY约束最多只能有一个,而表中可以有多个UNIQUE约束。 如果表中有多个UNIQUE约束,则所有UNIQUE约束必须在不同的列集。
与PRIMARY KEY约束不同,UNIQUE约束允许NULL值。 这取决于RDBMS要考虑NULL值是否唯一。
例如,MySQL将NULL值视为不同的值,因此,可以在参与UNIQUE约束的列中存储多个NULL值。 但是,Microsoft SQL Server或Oracle数据库不是这种情况。建表时有两种方式定义UNIQUE约束:
• 在创建表时创建UNIQUE约束
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL UNIQUE, password VARCHAR(255) NOT NULL );• 使用表约束语法创建的UNIQUE约束
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(255) NOT NULL, password VARCHAR(255) NOT NULL, CONSTRAINT uc_username UNIQUE (username) );在初建表没有定义UNIQUE约束的话,可以使用ALTER TABLE语句将主键添加到表中,前提条件是参与UNIQUE约束的列或列组合必须包含唯一值。
ALTER TABLE users ADD CONSTRAINT uc_username UNIQUE(username);如果要添加新列并为创建UNIQUE约束,请使用以下形式的ALTER TABLE语句。
ALTER TABLE users ADD new_column data_type UNIQUE;要删除UNIQUE约束,请使用ALTER TABLE语句
ALTER TABLE table_name DROP CONSTRAINT unique_constraint_name; -
SQL Not Null约束
NOT NULL约束是一个列约束,它定义将列限制为仅具有非NULL值的规则。
这意味着当使用INSERT语句向表中插入新行时,必须指定NOT NULL列的值。以下语句是NOT NULL约束语法。 它强制column_name不能接受NULL值。
建表时有两种方式定义NOT NULL约束:
• 建表字段添加
CREATE TABLE table_name( ... column_name data_type NOT NULL, ... );• NOT NULL约束等同于CHECK约束
CREATE TABLE table_name ( ... column_name data_type, ... CHECK (column_name IS NOT NULL) );
存储引擎
-
定义
存储引擎是一种用来存储mysql中对象(记录和索引)的一种特定的结构(文件结构),处于mysql服务器的最底层,直接存储数据。
MySQL数据库由于其自身架构的特点,存在多种数据存储引擎,每种存储引擎所针对的应用场景特点都不太一样。
-
设置存储引擎
在创建表的时候我们使用sql语句:
Create table tableName () engine=myisam|innodb;engine指明了存储引擎是myisam还是innodb
-
查看支持的存储引擎
show engines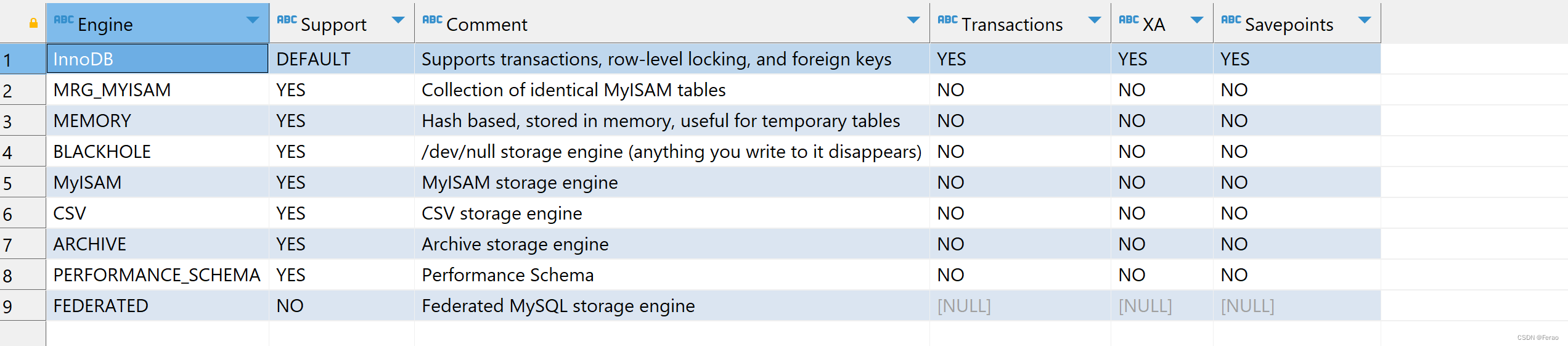
-
默认存储引擎
• 5.5版本前:MylSAM
• 5.5版本后:InnoDB -
推荐存储引擎
• InnoDB:要提供提交、回滚和恢复的事务安全(ACID 兼容)能力,并要求实现并发控制优选
• MyISAM:主要用来插入和查询记录
-
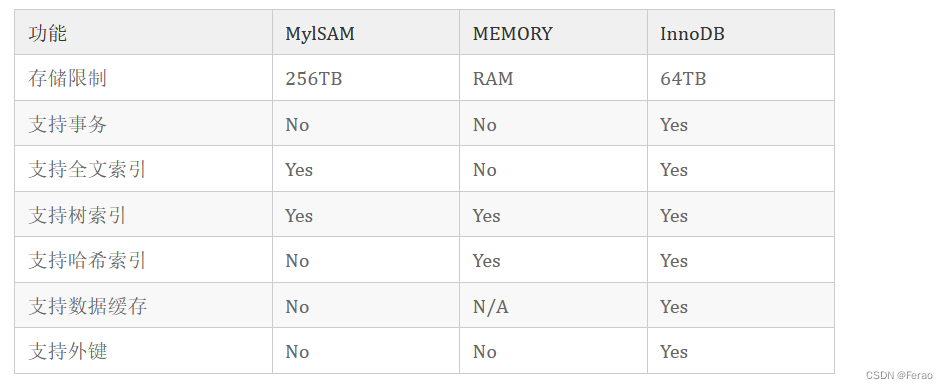
存储引擎功能列表
mysql事务
-
前提
发生在InnoDB 引擎下,MyISAM 引擎不支持事务
-
定义
事务内部是一组数据的操作,事务的结束有两种情况:全部成功(事务提交)、全部失败(事务回滚)
-
事务特性
• 原子性( Atomicity ):原子操作单元
• 一致性( Consistency ):开始到结束的时间段内,数据都必须保持一致状态
• 隔离性( Isolation ):隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行
• 持久性( Durability ):事务完成后,它对于数据的修改是永久性的 -
事务操作
-
查询:
select @@autocommit;• 自动提交:1
• 手动提交: 0 -
修改:
set @@autocommit = 0;
-
-
事务常见问题
• 脏读:事务A读取了事务B已经修改但尚未提交的数据。若事务B回滚数据,事务A的数据存在不一致性的问题
• 不可重复读:事务A第一次读取最初数据,第二次读取事务B已经提交的修改或删除数据。导致两次读取数据不一致。
• 幻读:事务A根据相同条件第二次查询到事务B提交的新增数据,两次数据结果集不一致幻读和脏读有点类似:脏读是事务B里面修改了数据,幻读是事务B里面新增了数据
脏读、不可重复读、幻读,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。 -
隔离机制
-
定义
将事务在一定程度上"串行"进行,这显然与"并发"是矛盾的。
根据自己的业务逻辑,权衡能接受的最大副作用。从而平衡了"隔离" 和 "并发"的问题。MySQL默认隔离级别是可重复读。事务隔离机制可以解决上述常见问题。 -
操作
查看:
select @@tx_isolation;修改:
set global transaction isolation level 级别字符串; -
隔离级别
隔离级别 读数据一致性 脏读 不可重复读 幻读 未提交读(Read uncommitted) 最低级别 是 是 是 已提交读(Read committed) 语句级 否 是 是 可重复读(Repeatable read) 事务级 否 否 是 可序列化(Serializable) 最高级别,事务级 否 否 否
-
数据记录存储格式
InnoDB存储引擎下数据记录的存储格式——Row Format行格式
在MySQL中,所谓Row Format行格式是指数据记录(或者称之为行)在磁盘中的物理存储方式。具体地,对于InnoDB存储引擎而言,常见的行格式类型有Compact、Redundant、Dynamic和Compressed。
在创建、修改数据表的时候,可以显式地指定row format行格式。SQL语句语法如下
-- 创建数据表时,显示指定行格式
create table 表名 (列的信息) row_format=行格式名称;
-- 创建数据表时,修改行格式
alter table 表名 row_format=行格式名称;
与此同时,如果需要查看某数据表的行格式,可通过如下语句实现
show table status from 数据库名 like '<数据表名>';
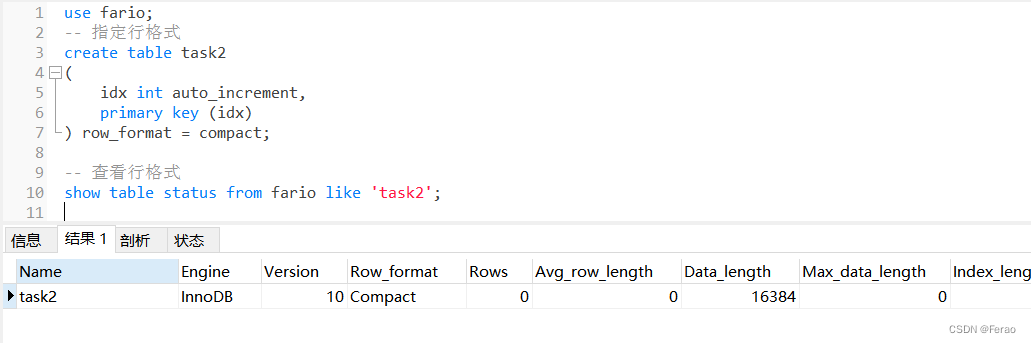
下面通过一个示例来验证上述语句的使用及效果。在test1数据库中创建一张名为task2的数据表,并指定行格式的类型为compact:
use test1;
-- 指定行格式
create table task2
(
idx int auto_increment,
primary key (idx)
) row_format = compact;
-- 查看行格式
show table status from test1 like 'task2';
从下图可以看出表的行格式类型被设置为compact
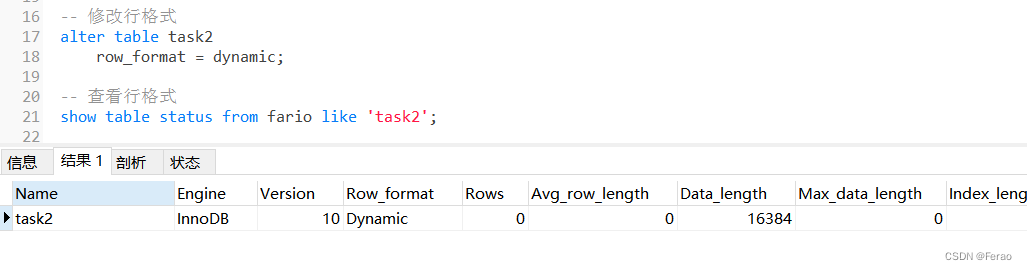
然后再将该表的行格式类型修改为dynamic
-- 修改行格式
alter table task2
row_format = dynamic;
-- 查看行格式
show table status from test1 like 'task2';
从下图可以看出表的行格式类型已被修改为dynamic
mysql表操作
-
查看表
#查询某个数据库中所有的表名称 show tables; #查询表结构 desc 表名; #查看表内容 select * from 表名; -
创建表
#创建数据表 create table 表名( 列名 类型 comment 'remark', 列名 类型 comment 'remark', 列名 类型 comment 'remark', primary key('fieldName') using btree, spatial key 'remark' ('fieldName'), key 'remark' ('filedName') using btree ) engine = innodb; #复制表 create table 表名 like 被复制的表名; -
删除表
#删除表 drop table 表名; #判断表存在,再删除表 drop table if exists 表名; -
清空表
delete from 表名 truncate table 表名 -
修改表
#修改表名 alter table 表名 rename to 新表名; #修改表的字符集 alter table 表名 character set 字符集名称; #添加列 alter table 表名 add 列名 类型 #添加多列 alter table 表名 add (字段名1 字段类型(长度),字段名2 字段类型(长度),...) #删除列 alter table 表名 drop 列名; #修改列类型 alter table 表名 modify 列名 新数据类型; #修改列名称 类型 alter table 表名 change 列名 新列名 新数据类型; #添加主键 alter table 表名 add primary key(列名); #删除主键 alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; #修改默认值 ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; #删除默认值 ALTER TABLE testalter_tbl ALTER i DROP DEFAULT; #添加外键 alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); #删除外键 alter table 表名 drop foreign key 外键名称
mysql表内容操作
表内容操作无非就是增删改查,当然用的最多的还是查,而且查这一块东西最多,用起来最难。
-
增
--插入单条 insert into 表 (列名,列名...) values (值,值,...) --插入多条 insert into 表 (列名,列名...) values (值,值,...),(值,值,值...) --插入多条 insert into 表 (列名,列名...) select (列名,列名...) from 表 -
删
#删除表里全部记录 delete from 表 #先删除表,然后再创建一张一样的表 truncate table 表 #删除表中部分记录 delete from 表 where 列=值 -
改
update 表 set 列=值 where 列=值; update 表 set 列=值,列=值 where 列=值 and 列=值; -
查
select * from 表; --限制范围 select * from 表 where age >20; select * from 表 where age between 20 and 30 --[20,30]; select * from 表 where age in (20,18,25); --通配符like select * from 表 where name like 'zhang%' # zhang开头的所有(多个字符串) select * from 表 where name like 'zhang_' # zhang开头的所有(一个字符) --限制limit select * from 表 limit 5; # 前5行 select * from 表 limit 4,5; # 从第4行开始的5行 select * from 表 limit 5 offset 4 # 从第4行开始的5行 --排序asc,desc select * from 表 order by 列 asc # 根据 “列” 从小到大排列 select * from 表 order by 列 desc # 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc # 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序 --分组group by select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 -
基本查询
select fieldName as alias, fieldName as alias, (fieldName + fieldName) as alias from 表名列表 where 条件列表 group by 分组字段 having 分组之后的条件 order by fieldName desc limit 分页限定 -
(distinct)去重查询
distinct关键字用来查询记录不重复的数据,使用时需要放在查询字段开头,并且使用也分为两种场景:
• 单个字段去重:选取字段一列数据不重复

• 多个字段去重:多个字段拼接成一条记录,筛选出不重复的数据

mysql函数
字符函数
-
返回字符串所在的位置数[locate()]
查找指定字符在目标字符中出现位置的位置数,有两种用法:
• LOCATE(substr,str):返回字符串substr中第一次出现子字符串的位置 str,不存在则返回0
• LOCATE(substr,str,pos):返回字符串substr中第一个出现子 字符串的 str位置,从位置开始 pos。0 如果substr不在,则 返回str。返回 NULL如果substr 或者str是NULL

-
字段合并函数[concat()]
concat()函数将多个字符串连接成一个字符串,如果有任何一个参数为null,则返回值为null。
函数语法:
concat(str1, str2,...)concat()函数缺点是三个字段需要输入两次逗号,如果10个字段,要输入九次逗号

-
字段合并函数[concat_ws()]
concat_ws 即 concat with separator,它和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符,并且参数str有null值时不进行处理,后续字段不影响。若把分隔符separator换为null值,则都为null值。
函数语法:
concat_ws(separator, str1, str2, ...)
-
模糊查询[instr()函数]
进行模糊查询时,可使用内部函数 instr,替代传统的 like 方式,并且速度更快,该函数模糊匹配时默认不区分大小写。
函数语法:
instr(field, substr)第一个参数 field 是字段,第二个参数 str 是要查询的字符串,返回字符串 str 的第一次出现的位置坐标[1开始],没找到就是0。

要强制INSTR函数根据以区分大小写的方式进行搜索,可以使用BINARY关键字,如SELECT INSTR(‘MySQL INSTR’, BINARY ‘sql’);
另外,有时候我们需要按照in条件里的id顺序输出结果,可sql语句在不加order by的时候是按照asc排序的。
下边的sql解决按照in条件顺序的id输出查询结果SELECT * FROM xxxx WHERE `id` IN (688,686) ORDER BY INSTR('688,686', `id`) -
剔除字符[trim()函数]
可以移除字符串的首尾信息。最常见的用法为移除字符首尾空格。
函数语法:
trim(field)
-
字符截取[left()函数]
函数 作用 left(被截取字符串, 截取长度) select left(‘www.csdn.com’,5) ,结果:www.c right(被截取字符串, 截取长度) select right(‘www.csdn.com’,6),结果:dn.com substring(被截取字符串, 从第几位开始截取) select substring(‘www.csdn.com’, 9),结果:com substring(被截取字符串,从第几位开始截取,截取长度) select substring(‘www.csdn.com’, 7, 3) ,结果:n.c substring_index(被截取字符串,关键字,关键字出现的次数) select substring_index(‘www.csdn.com’, ‘.’, 2),结果:www.csdn substring_index(被截取字符串,关键字,关键字出现的次数) select substring_index(‘www.csdn.com’, ‘.’, -2),结果:csdn.com
日期函数
-
获得当前日期和获得当前时间的函数

-
获得年份、月份、日、时、分、秒的函数

-
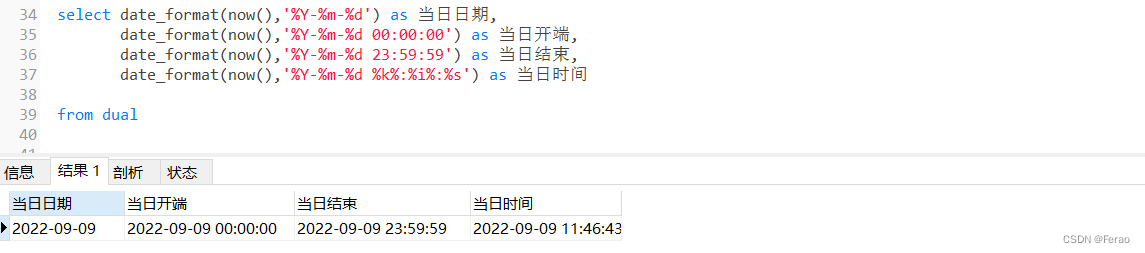
日期类型转换字符类型的函数
-
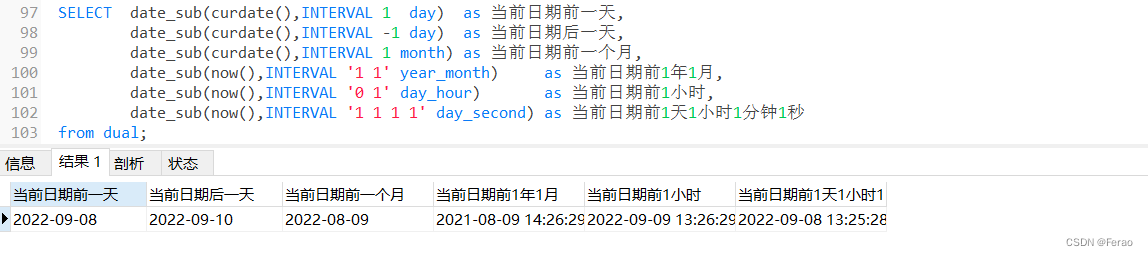
计算日期和时间的函数
interval 得到的是一个时间间隔,是一种数据类型,可以直接与日期进行计算
-
时间处理
时间转换 字符类型(varchar) --> 时间格式(Date) 函数: str_to_date(varchar str,varchar format) 示例: SELECT STR_TO_DATE('2016-01-02', '%Y-%m-%d') AS 字符列转日期列 2016-01-02 SELECT STR_TO_DATE('2016-01-02', '%Y-%m-%d %H') AS 字符列转日期列 2016-01-02 00:00:00 SELECT STR_TO_DATE('2016-01-02 23:59:59', '%Y-%m-%d %H') AS 字符列转日期列 2016-01-02 23:00:00 时间类型(Date) --> 时间戳类型(timestamp) 函数: unix_timestamp() 示例: SELECT UNIX_TIMESTAMP(NOW()) 1606792491 时间戳类型(timestamp) --> 时间类型(Date) 函数: from_unixtime(unix_timestamp, format) 示例: SELECT FROM_UNIXTIME(1606792491) 2020-12-01 11:14:51 字符类型(varchar) --> 时间戳类型(timestamp) 函数: unix_timestamp() 示例: SELECT UNIX_TIMESTAMP('2019-04-04') 1554307200 时间戳类型(timestamp) --> 字符类型(varchar) 函数: from_unixtime(unix_timestamp, format) 示例: SELECT FROM_UNIXTIME(1451997924,'%Y-%m-%d') 2016-01-05
条件函数
-
if(expr,v1,v2)函数

-
ifnull(v1,v2)函数

聚合函数
-
总个数、总合、最大值、最小值、平均数
函数 作用 count() 计算个数 max() 计算最大值 min() 计算最小值 sum() 计算和 avg() 计算平均值 -
group by聚合行
子句的书写顺序:FROM --> WHERE --> GROUP BY --> SELECT
根据执行顺序SELECT 子句是在 group by 子句之后执行。所以执行到 group by 子句时无法识别别名。
WHERE 子句智能指定记录(行)的条件,而不能用来指定组的条件。

类型转换相关函数
-
| 类型转换[>convert()函数]
用来把一个数据类型的值转换为另一个数据类型的值,该函数与
CAST(value as type);函数作用相同。其可以转换的类型是有限制的。这个类型可以是以下值其中的一个:二进制,同带binary前缀的效果 : BINARY
字符型,可带参数 : CHAR()
日期 : DATE
时间: TIME
日期时间型 : DATETIME
浮点数 : DECIMAL
整数 : SIGNED
无符号整数 : UNSIGNED函数语法:
CONVERT(value, type);
-
partition by()分析函数
group by是分组函数,查询字段只能是分组条件和一些聚合函数。
partition by是分区函数,只分区并不进行聚合汇总。over函数的写法:
over(partition by cno order by degree )先对cno 中相同的进行分区,在cno 中相同的情况下对degree 进行排序
这里再额外拓展Partition By与rank() 、Partition By与row_number() 两者用法的区别
(1)使用rank()
SELECT * FROM (select sno,cno,degree, rank()over(partition by cno order by degree desc) mm from score) where mm = 1;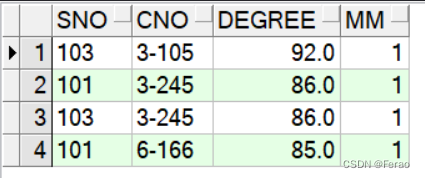
(2)使用row_number()
SELECT * FROM (select sno,cno,degree, row_number()over(partition by cno order by degree desc) mm from score) where mm = 1;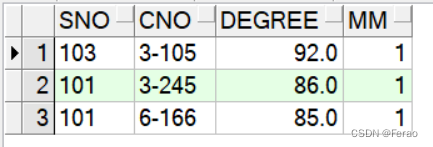
由以上的例子得出,在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果。
系统信息函数
-
获取MYSQL版本号

-
查看当前用户的连接数

数字函数
| 函数 | 作用 | 示例 |
|---|---|---|
| ABS(x) | 返回x的绝对值 | SELECT ABS(-1) 返回1 |
| CEIL(x),CEILING(x) | 返回大于或等于x的最小整数 | SELECT CEIL(1.5) 返回2 |
| FLOOR(x) | 返回小于或等于x的最大整数 | SELECT FLOOR(1.5) 返回1 |
| RAND() | 返回0->1的随机数 | SELECT RAND() 0.93099315644334 |
| SIGN(x) | 返回x的符号,x是负数、0、正数分别返回-1、0和1 | SELECT SIGN(-10) (-1) |
| ROUND(x) | 返回离x最近的整数 | SELECT ROUND(1.23456) 1 |
| ROUND(x,y) | 保留x小数点后y位的值,但截断时要进行四舍五入 | SELECT ROUND(1.23456,3) 1.235 |
字符函数
日期时间函数
mysql关键字
union 与 union all
概述
sql集合运算分两种维度:行维度、列维度。
行维度会固定行的个数,会对各表列数据进行合并;列维度会导致记录行的增减,列数据不会影响。
搭建学习环境
①DDL创建Shohin表
CREATE TABLE Shohin
(shohin_id CHAR(4) NOT NULL,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE ,
PRIMARY KEY (shohin_id));
②DML插入Shohin数据
INSERT INTO Shohin VALUES ('0001', 'T恤' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO Shohin VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Shohin VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Shohin VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO Shohin VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO Shohin VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO Shohin VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO Shohin VALUES ('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
③DDL创建Shohin2表
CREATE TABLE Shohin2
(shohin_id CHAR(4) NOT NULL,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE ,
PRIMARY KEY (shohin_id));
④DML插入数据
INSERT INTO Shohin2 VALUES ('0001', 'T恤' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO Shohin2 VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO Shohin2 VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO Shohin2 VALUES ('0009', '手套', '衣服', 800, 500, NULL);
INSERT INTO Shohin2 VALUES ('0010', '水壶', '厨房用具', 2000, 1700, '2009-09-20');
表的集合
union 或者 union all 可将两个或多个select语句的结果作为一个整体显示出来。
使用时必须保证各个select 集合的查询结果集有相同个数的列,并且每个列的类型是一样的.但列名则不一定需要相同,其中union 称为 联合。
语句默认规则的排序,可以在最后一个结果集中指定Order by子句改变排序方式
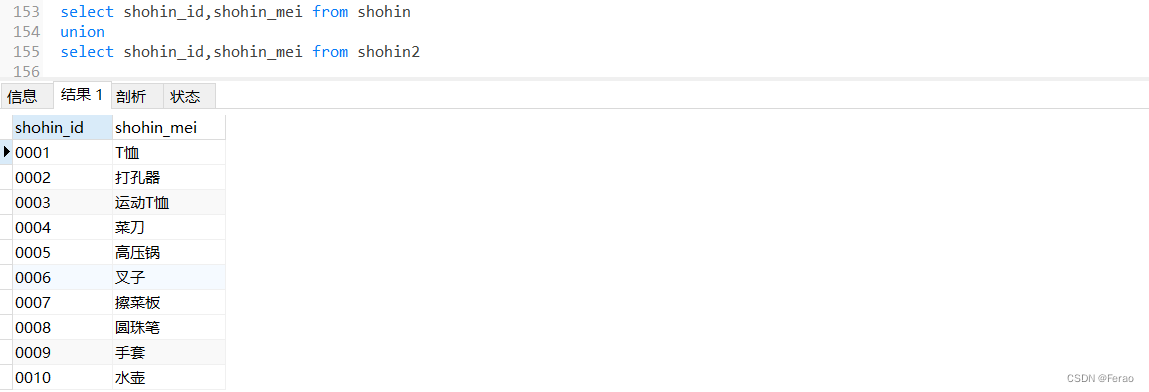
union并集图,会移除重复的记录。
ALL 选项 - 包含重复行的集合运算

sql表的联结
表联结原理有两表联结、多表联结的区分:
• 两表联结:对两表求积(笛卡尔积)并用ON条件和连接连接类型进行过滤形成中间表;然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
• 多表联结:先对第一个和第二个表按照两表连接做查询,然后用查询结果和第三个表做连接查询,以此类推,直到所有的表都连接上为止,最终形成一个中间的结果表,然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
ON条件和WHERE条件
ON条件:是过滤两个链接表笛卡尔积形成中间表的约束条件。
WHERE条件:
在有ON条件的SELECT语句中是过滤中间表的约束条件。
在没有ON的单表查询中,是限制物理表或者中间查询结果返回记录的约束。
在两表或多表连接中是限制连接形成最终中间表的返回结果的约束。
从这里可以看出,将WHERE条件移入ON后面是不恰当的。推荐的做法是:ON只进行连接操作,WHERE只过滤中间表的记录。
连接查询
连接运算符是用来实现多表联合查询的一种重要方式,主要分为三种:内连接、外连接、交叉连接。
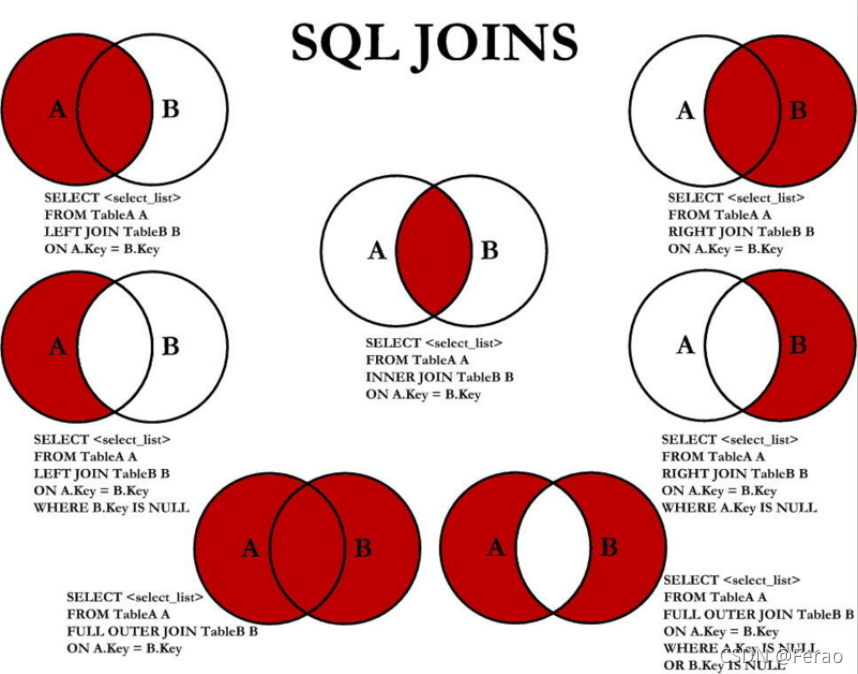
-
内连接 INNER JOIN
内连接(INNER JOIN)有两种,显式的和隐式的,返回连接表中符合连接条件和查询条件的数据行。(所谓的链接表就是数据库在做查询形成的中间表)。
内连接使用比较运算符(包括=、>、<、<>、>=、<=、!> 和!<)进行表间的比较操作,查询与连接条件相匹配的数据。根据所使用的比较方式不同,内连接分为等值连接、自然连接和自连接三种。
语句1:隐式内连接,没有INNER JOIN,形成的中间表为两个表的笛卡尔积
SELECT O.ID,O.ORDER_NUMBER,C.ID,C.NAME FROM CUSTOMERS C,ORDERS O WHERE C.ID=O.CUSTOMER_ID;语句2:显示的内连接,一般称为内连接,有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积
SELECT O.ID,O.ORDER_NUMBER,C.ID,C.NAME FROM CUSTOMERS C INNER JOIN ORDERS O ON C.ID=O.CUSTOMER_ID;语句3:等值连接:使用”=”关系将表连接起来的查询,其查询结果中列出被连接表中的所有列,包括其中的重复列。
SELECT PM_ACT_JOB_RLS.*, PM_ACT_RLS.* FROM PM_ACT_JOB_RLS INNER JOIN PM_ACT_RLS ON PM_ACT_JOB_RLS.RlsPK = PM_ACT_RLS.RlsPK语句4:自然连接:等值连接中去掉重复的列,形成的连接。
说真的,这种连接查询没有存在的价值,既然是SQL2标准中定义的,就给出个例子看看吧。自然连接无需指定连接列,SQL会检查两个表中是否相同名称的列,且假设他们在连接条件中使用,并且在连接条件中仅包含一个连接列。不允许使用ON语句,不允许指定显示列,显示列只能用*表示(ORACLE环境下测试的)。对于每种连接类型(除了交叉连接外),均可指定NATURAL。
SELECT PM_ACT_JOB_RLS.JobPK, PM_ACT_RLS.RlsPK, RlsName FROM PM_ACT_JOB_RLS Natural INNER JOIN PM_ACT_RLS ON PM_ACT_JOB_RLS.RlsPK = PM_ACT_RLS.RlsPK语句5:自连接:如果在一个连接查询中,设计到的两个表都是同一个表,这种查询称为自连接查询。
--c1、c2逻辑上是两张表,物理上是一张表 SELECT c1.CategoryID, c1.CategoryName FROM [dbo].[Category] c1 INNER JOIN [dbo].[Category] c2 ON c1.[CategoryID] = c2.[ParentID]语句6:联合连接(UNION JOIN):这是一种很少见的连接方式。Oracle、MySQL均不支持,其作用是:找出全外连接和内连接之间差异的所有行。这在数据分析中排错中比较常用。也可以利用数据库的集合操作来实现此功能。
-
外连接
内连接只返回满足连接条件的数据行,外连接不只列出与连接条件相匹配的行,而是列出左表(左外连接时)、右表(右外连接时)或两个表(全外连接时)中所有符合搜索条件的数据行。
外连接分为左外连接、右外链接、全外连接三种。
-
left join(left outer join)
左向外联接的结果集包括 left outer子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
select o.id, o.order_number, o.customer_id, c.id, c.name from orders o left join customers c on c.id = o.customer_id;当右表存在多条记录时,即一对多的情况时,表结构与数据:
create `image`( `id `int(11)not null auto_increment, `productid`int(11)default null, `name`varchar(255)default null, primary key(`id`) )engine=innodb auto_increment=7 default charset=utf8; -- ---------------------------- --图像记录 -- ---------------------------- insert`image`VALUES('1','1','商品1.的图⽚1'); insert`image`VALUES('2','1','商品1.的图⽚2'); insert`image`VALUES('3','1','商品1.的图⽚3'); insert`image`VALUES('4','2','商品2.的图⽚1'); insert`image`VALUES('5','2','商品2.的图⽚2'); insert`image`VALUES('6','3','商品2.的图⽚1'); -- ---------------------------- create `product`( `id `int(11)not null auto_increment, `name`varchar(255)default null, primary key(`id`) )engine=innodb auto_increment=4 default charset=utf8; -- ---------------------------- --产品记录 -- ---------------------------- insert`product`VALUES('1','商品1'); insert`product`VALUES('2','商品2'); insert`product`VALUES('3','商品3');执行左关联查询:
select * from product as p left join image as img on p.id=img.productId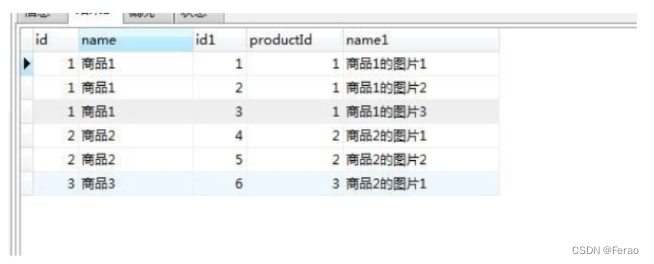
发现一对多关联然后全部查询出来了
-
RIGHT JOIN 或 RIGHT OUTER JOIN
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME FROM ORDERS O RIGHT OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID; -
FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
注意:MySQL是不支持全外的连接的,这里给出的写法适合Oracle和DB2。但是可以通过左外和右外求合集来获取全外连接的查询结果。
SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME FROM ORDERS O FULL OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID;左外和右外的合集
实际上查询结果和上面的全外连接语句是相同的
SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME FROM ORDERS O LEFT OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID UNION SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME FROM ORDERS O RIGHT OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID;
-
-
交叉连接
交叉连接(CROSS JOIN):有两种,显式的和隐式的。不带ON子句,返回的是两表的乘积,也叫笛卡尔积。
语句1:隐式的交叉连接,没有CROSS JOIN。
SELECT O.ID, O.ORDER_NUMBER, C.ID, C.NAME FROM ORDERS O , CUSTOMERS C WHERE O.ID=1;语句2:显式的交叉连接,使用CROSS JOIN。
SELECT O.ID,O.ORDER_NUMBER,C.ID, C.NAME FROM ORDERS O CROSS JOIN CUSTOMERS C WHERE O.ID=1;
数据库拓展操作
数据库视图
mysql 从5.0.1版本开始提供视图功能。在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表,是一种虚拟存在的表。视图包含行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。只保存了sql逻辑,不保存查询结果。
实际开发中,当多个地方用到同样的查询结果以及该查询结果使用的sql语句较复杂会用到视图
视图的语法如下:
//创建视图
create view 视图名 as 查询语句;
//查看视图
show create view 视图名;
//查看视图
desc 视图名;
//修改视图
create or replace view 视图名 as 查询语句;
//修改视图
alter view 视图名 as 查询语句;
//删除视图
drop view 视图名,视图名,...;
//使用视图
select * from v1;
//查看本库所有视图(oracle)
select * from all_views t
//查看本用户所有视图(oracle)
select * from user_views t
//查看本库每个用户视图数(oracle)
select owner, count(*) from all_views t group by owner
视图的可更新性和视图中查询的定义有关系,以下类型的视图是不能更新的
• 包含一下关键字的sql语句:分组函数、distinct、group by、having、union或者unionall
• 常量视图
• select 中包含子查询
• join
存储过程
一组预先编译好的sql语句的集合,可理解成批处理语句。可提高代码的重用性、简化操作、减少编译次数并且减少了和数据库服务器的连接次数,提高了效率。
-
查看存储过程
show create procedure 存储过程名称; -
创建存储过程(无参)
-- delimiter :自定义语句结尾符号,因为这里要执行好多句sql语句,所以就得自定义,以防止出错 delimiter // create procedure p1() begin select * from tab1; end// delimiter ; -- 执行存储过程 call p1(); -
创建存储过程(有参)
-- 创建存储过程 delimiter \\ create procedure p1( in i1 int, -- 传入参数i1 in i2 int, -- 传入参数i2 inout i3 int, -- 即传入又能得到返回值 out r1 int -- 得到返回值 ) BEGIN DECLARE temp1 int; DECLARE temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end\\ delimiter ; -- 执行存储过程 DECLARE @t1 INT default 3; -- 设置变量默认值为3 DECLARE @t2 INT; -- 设置变量 CALL p1 (1, 2 ,@t1, @t2); -- 执行存储过程,并传入参数,t2自动取消 SELECT @t1,@t2; -- 查看存储过程输出结果 -
删除存储过程
drop procedure p1;
数据库系统操作
系统表
information_schema库中存放着各种系统表,保存了MySQL服务器所有数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。再简单点,这台MySQL服务器上,到底有哪些数据库、各个数据库有哪些表,每张表的字段类型是什么,各个数据库要什么权限才能访问,等等信息都保存在information_schema库中,重点介绍几种常用的表:
-
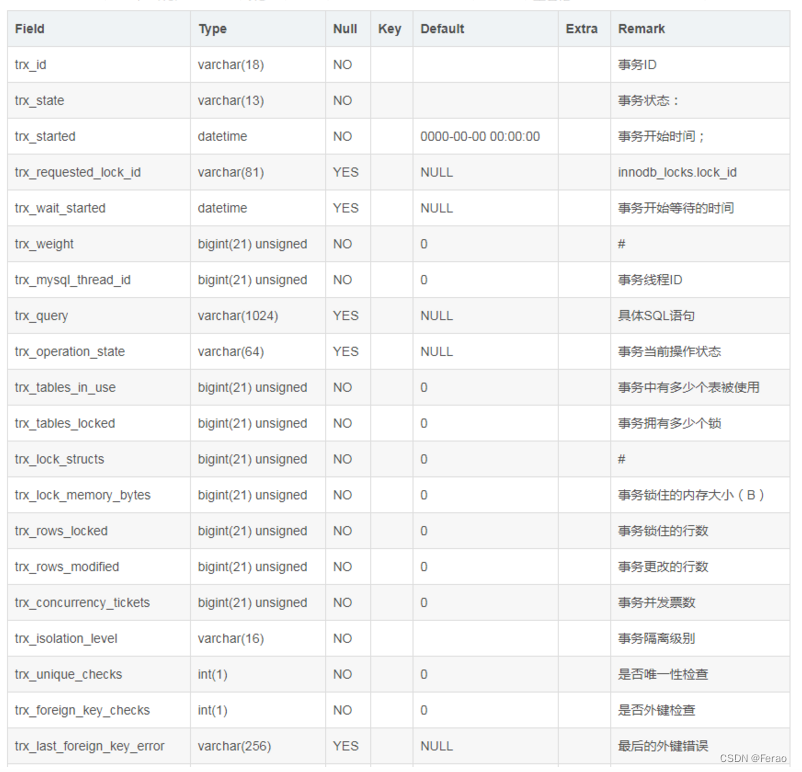
innodb_trx 事务表
该表用于记录当前运行的所有事务,下面是表字段的定义:
通过以下语句来查看正在执行的事务:
记录trx_mysql_thread_id号,发现trx_state的状态为RUNNING,说明事务正在进行,没有锁,但是可能由于sql复杂影响查询效率,sql一直处于运行状态
INNODB_TRX 表的 trx_mysql_thread_id 字段对应 show full processlist 中的Id,执行 show full PROCESSLIST:
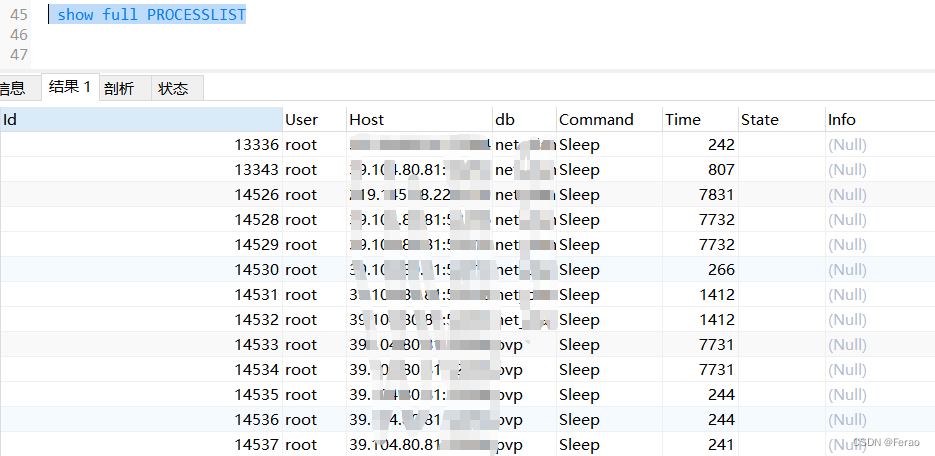
如果查询的 trx_mysql_thread_id 在列出的线程中,就说明这个 sleep 的线程事务一直没有 commit 或者 rollback,而是卡住了,需要我们手动删除。
手动删除的方法是执行Kill trx_mysql_thread_id 即可:

-
innodb_locks 表
该表用于记录当前出现的锁,下面是表字段的定义:
-
innodb_lock_waits 表
该表用于记录锁等待的对应关系,下面是表字段的定义:
binlog日志
-
定义
mysql的二进制日志记录了除了查询语句外的信息,还包含语句所执行的消耗的时间。
-
日志种类
• 二进制日志索引文件:(文件名后缀为.index)用于记录所有的二进制文件
• 二进制日志文件:(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件 -
作用
• Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的
• 通过使用mysqlbinlog工具进行恢复数据 -
开启binlog日志
-
操作binlog日志
mysql查询流程
我们先来看下,一条查询语句下来,会经历哪些流程。
比如我们有一张数据库表
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`gender` int(8) NOT NULL DEFAULT '0' COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`),
KEY `idx_gender` (`gender`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
我们平常写的应用代码(go或C++之类的),这时候就叫客户端了。
客户端底层会带着账号密码,尝试向mysql建立一条TCP长链接。
mysql的连接管理模块会对这条连接进行管理。
建立连接后,客户端执行一条查询sql语句。比如:
select * from user where gender = 1 and age = 100;
客户端会将sql语句通过网络连接给mysql。
mysql收到sql语句后,会在分析器中先判断下SQL语句有没有语法错误,比如select,如果少打一个l,写成slect,则会报错You have an error in your SQL syntax;。这个报错对于我这样的手残党来说可以说是很熟悉了。
接下来是优化器,在这里会根据一定的规则选择该用什么索引。
之后,才是通过执行器去调用存储引擎的接口函数。
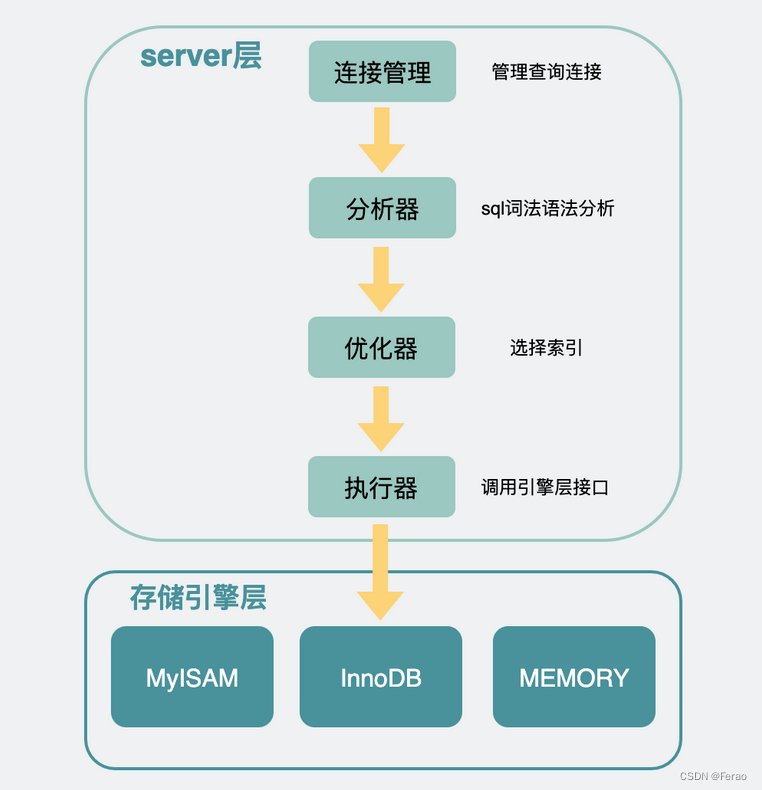
存储引擎类似于一个个组件,它们才是mysql真正获取一行行数据并返回数据的地方,存储引擎是可以替换更改的,既可以用不支持事务的MyISAM,也可以替换成支持事务的Innodb。这个可以在建表的时候指定。比如
CREATE TABLE `user` (
...
) ENGINE=InnoDB;
现在最常用的是InnoDB。
我们就重点说这个。
InnoDB中,因为直接操作磁盘会比较慢,所以加了一层内存提提速,叫buffer pool,这里面,放了很多内存页,每一页16KB,有些内存页放的是数据库表里看到的那种一行行的数据,有些则是放的索引信息。
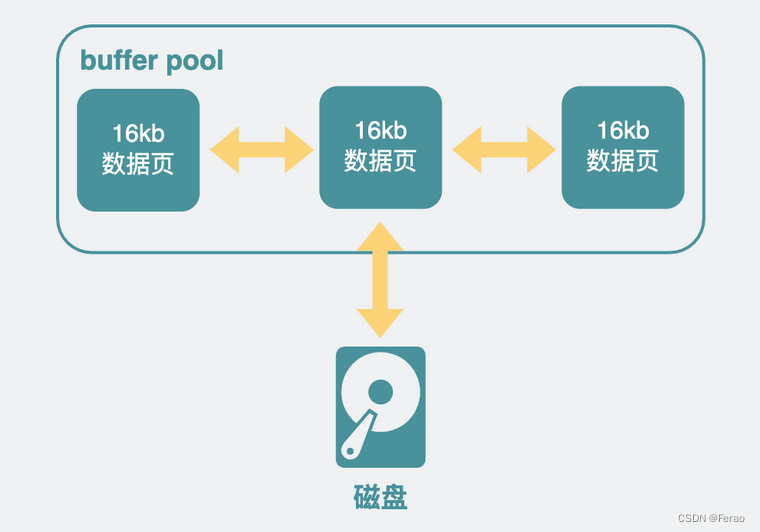
查询SQL到了InnoDB中。会根据前面优化器里计算得到的索引,去查询相应的索引页,如果不在buffer pool里则从磁盘里加载索引页。再通过索引页加速查询,得到数据页的具体位置。如果这些数据页不在buffer pool中,则从磁盘里加载进来。
这样我们就得到了我们想要的一行行数据。
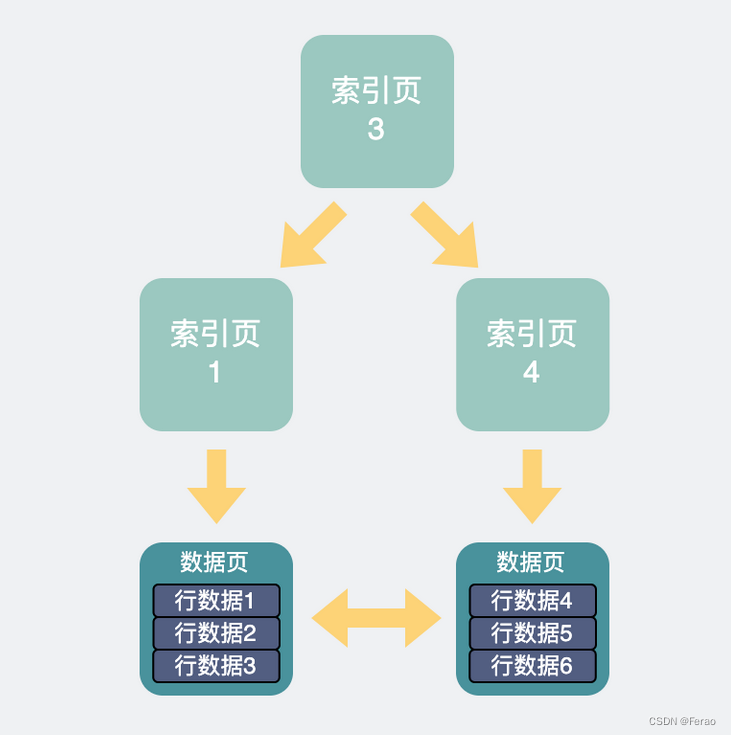
最后将得到的数据结果返回给客户端。
in、exists、case when、insert into select
-
in 关键字
In查询只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录.
select * from A where id in(select id from B)当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次.
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历100001000000次,效率很差.
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000100次,遍历次数大大减少,效率大大提升.结论:in()适合B表比A表数据小的情况
-
exists 关键字
exists指定一个子查询,检测 行 的存在,如果子查询包含行,则返回 TRUE ,否则返回 FLASE。其中子查询是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。
exists语句会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
select a.* from A a where exists(select 1 from B b where a.id=b.id)当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等.
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果.再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
结论:exists()适合B表比A表数据大的情况。当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
-
case when 关键字
Case函数返回第一个符合条件的值,剩下的Case部分将会被自动忽略。Case函数有两种写法,简单Case函数 以及 Case搜索函数。
两种格式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。
-
简单Case函数
--简单case函数 case 列名 when 条件值1 then 选项1 when 条件值2 then 选项2....... else 默认值 end -
Case搜索函数
case when 列名= 条件值1 then 选项1 when 列名= 条件值2 then 选项2....... else 默认值 end示例
--GROUP BY CASE WHEN 用法 SELECT CASE WHEN salary <= 500 THEN '1' WHEN salary > 500 AND salary <= 600 THEN '2' WHEN salary > 600 AND salary <= 800 THEN '3' WHEN salary > 800 AND salary <= 1000 THEN '4' ELSE NULL END salary_class, -- 别名命名 COUNT(*) FROM Table_A GROUP BY CASE WHEN salary <= 500 THEN '1' WHEN salary > 500 AND salary <= 600 THEN '2' WHEN salary > 600 AND salary <= 800 THEN '3' WHEN salary > 800 AND salary <= 1000 THEN '4' ELSE NULL END;
-
-
insert into select 关键字
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
--两个表结构一样 insert into table_name_new select * from table_name_old --两个表结构不一样 insert into table_name_new(column1,column2...) select column1,column2... from table_name_old
mysql索引
-
定义
索引在mysql中也叫做"键"或者"key"(primary key、unique key、index key),用于快速找到索引列的指定数据行;
如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息
• 如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止
• 如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,在查询该字段上的信息时能够快速找到对应的数据,而不必在遍历2W条数据 -
原理
创建表进行添加索引,MySQL默认通过Btree算法生成一个索引文件,在查询表时,找到索引文件进行遍历,在比较小的索引数据里查找,然后映射到对应的数据,能大幅提升查找的效率。
-
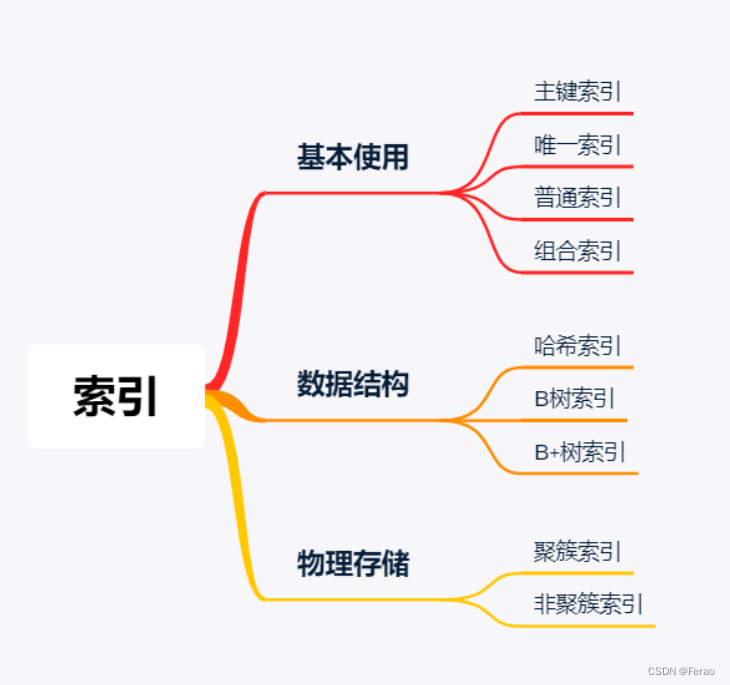
索引分类
• 单列索引
普通索引
唯一索引
主键索引
• 组合索引
• 全文索引
• 空间索引单列索引 内容 普通索引 基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点 唯一索引 索引列中的值必须是唯一的,但是允许为空值 主键索引 特殊的唯一索引,不允许有空值 -
索引存储类型
它有两种存储类型:
• BTREE
• HASH也就是用树或者Hash值来存储该字段
-
存储引擎
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引存储类型
• MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换
• MEMORY/HEAP存储引擎:支持HASH和BTREE索引
从三个不同维度对索引分类
「空间索引」
空间索引必须在 MYISAM类型的表中创建,而且空间类型的字段必须为「非空」

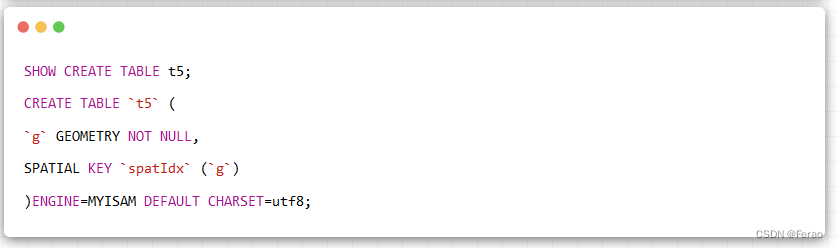
可以看到,t5表的g字段上创建了名称为spatIdx的空间索引。注意创建时指定空间类型字段值的非空约束
已经存在的表上创建索引
语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
ON table_name(col_name[length],...) [ASC|DESC]
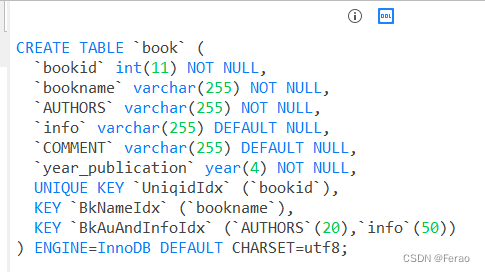
我们建立一个book表

建立普通索引:CREATE INDEX BkNameIdx ON book(bookname);
建立唯一索引:CREATE UNIQUE INDEX UniqidIdx ON book(bookId);
建立复合索引:CREATE INDEX BkAuAndInfoIdx ON book(AUTHORS(20),info(50));
聚簇索引与非聚簇索引
首先理解聚簇索引不是一种新的索引,而是而是一种数据存储方式。聚簇表示数据行和相邻的键值紧凑地存储在一起。我们熟悉的两种存储引擎——MyISAM采用的是非聚簇索引,InnoDB采用的是聚簇索引。
可以这么说:
索引是不是建的越多越好呢?
当然不是。索引会占据磁盘空间,并且索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
索引类别
-
单列索引
类别 描述 约束 全文索引 (fullTest) 只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。字段长度比较大时,如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。MyISAM和InnoDB中都可以使用全文索引 空间索引 MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。MySQL在空间索引这方面遵循OpenGIS几何数据模型规则 前缀索引 在文本类型如CHAR,VARCHAR,TEXT类列上创建索引时,可以指定索引列的长度,但是数值类型不能指定 无
索引示例
#添加PRIMARY KEY(主键索引)
alter table `table_name` add primary key(`column`);
#添加UNIQUE(唯一索引)
alter table `table_name` add unique(`column`);
#添加普通索引
alter table `table_name` add index index_name(`column`);
#添加全文索引
alter table `table_name` add fulltext(`column`);
#添加多列索引
alter table `table_name` add index index_name(`column1`,`column2`,`column3`);
索引的数据结构
任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
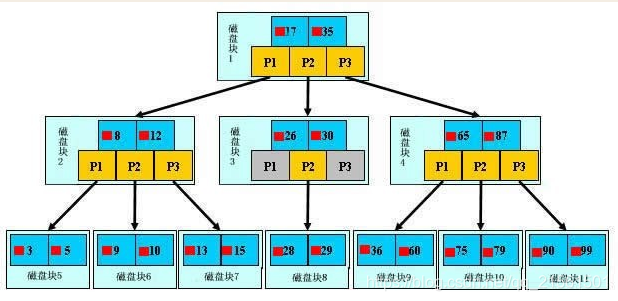
如上图,是一颗b+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
###b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
###b+树性质
1.索引字段要尽量的小:通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.索引的最左匹配特性(即从左往右匹配):当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
组合索引
-
定义
组合索引就是在多个字段上创建一个索引
-
最左匹配原则
组合索引遵从最左匹配原则,即利用索引中最左边的列集来匹配行。
如由:id、name和age3个字段构成的索引可索引情况:
• (id,name,age)
• (id,name)
• (id)不可索引情况:
• (age)
• (name,age) -
类别
类别 描述 约束 联合主键索引(primary key) (id,name) 联合唯一索引(unique) (id,name) id,name组合 在表中不能重复 联合普通索引(index) (id,name)
空间索引
空间索引
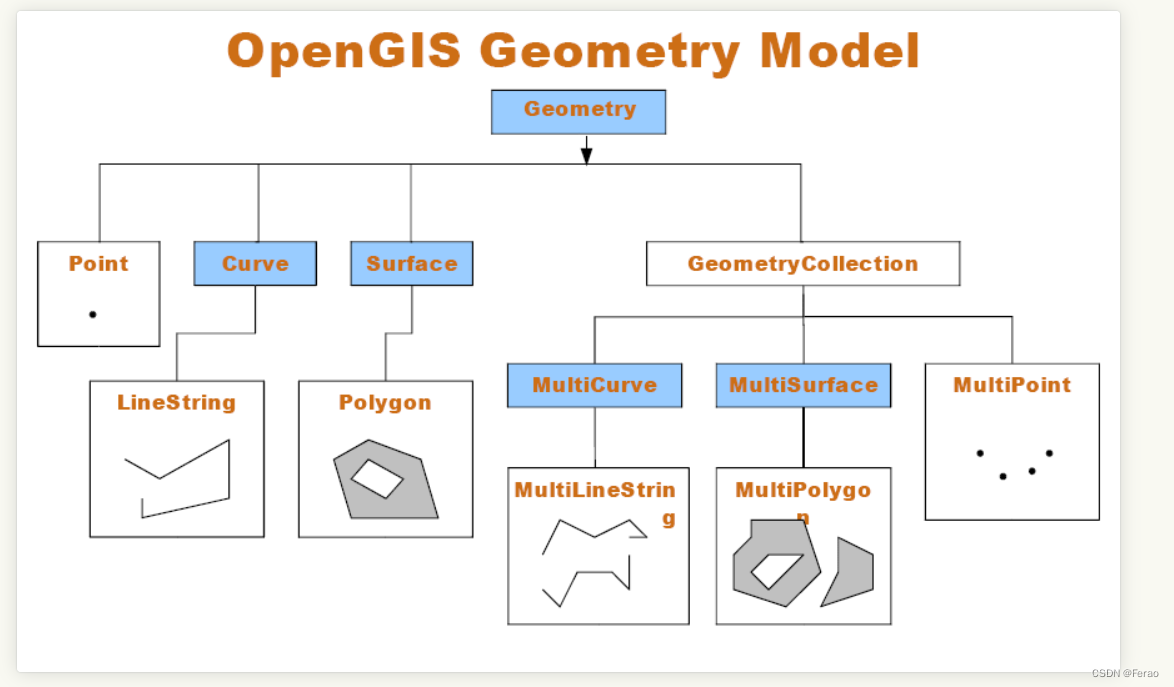
MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。国内的MySQL相关的书籍都比较老了,在这方面有详细描述的还没有见过。有一本比较新的PostgreSQL的数据介绍过空间搜索相关的内容,但是也不够详细。所以对于这方面的内容,不管是MySQL还是PostgreSQL,都建议直接去看官方文档,都有很详细的示例。
MySQL在空间索引这方面遵循OpenGIS几何数据模型规则,详情可见
-
空间运算分析
MySQL提供了在空间数据上执行各种操作的函数。根据操作的类型这些函数可以被分成几个大类
• 创建各种格式几何图形函数 (WKT, WKB, internal)
• 几何图形格式之间的转换函数
• 几何的定性或定量属性的访问函数
• 描述两个图形之间的关系函数
• 从现有的创建新的几何图形函数 -
常用函数
-
几何对象属性查询函数
Geometry(为基类函数, 点线面都可用)
• Dimension(g) : 返回几何对象g的维数, 点为0, 线为1, 多边形为2
• Envelope(g): 返回几何对象g的最小边界矩形(xy的极值点)。如果对象为点则返回该点对象,如果对象为线和多边形则返回极值xy坐标构造成的矩形Polygon
• GeometryType(g): 返回几何对象g的类型名称, 点为POINT, 线为LINEPOINT, 多边形为POLYGON
• IsClosed(g): 返回几何对象g是否封闭 ,条件为该线对象首尾point重合则为封闭, 封闭为1, 不封闭为0, 如果几何对象不为线对象的话, 返回为null
• IsSimple(g): 返回几何对象g是否简单, 条件为该线对象路径没有交叉则为简单, 简单为1, 不简单为0, 如果几何对象不为线对象的话, 返回为nullPoint
• X§: 返回该点X坐标
• Y§: 返回改点Y坐标LineString
• EndPoint(line): 返回对象line的最后一个点Point
• StartPoint(line): 返回对象line的第一个点Point
• PointN(line, N): 返回对象line中第N个点,N从1开始Polygon
• ExteriorRing(poly): 返回多边形对象poly的外轮廓线,类型为LineString
• InteriorRingN(poly, N): 返回对象poly的第N个空洞轮廓线,N从1开始
• NumInteriorRings(poly): 返回对象poly的空洞个数 -
返回新的几何对象
• st_union(g1, g2): 返回 面1和面2的并集
• st_difference(g1, g2): 返回 面1 - (面1和面2的交集)
• st_intersection(g1, g2): 返回 面1和面2的交集 -
查询几何对象关系
• ST_Contains(a,b): 如果几何对象a完全包含几何对象b, 则返回1, 否则0
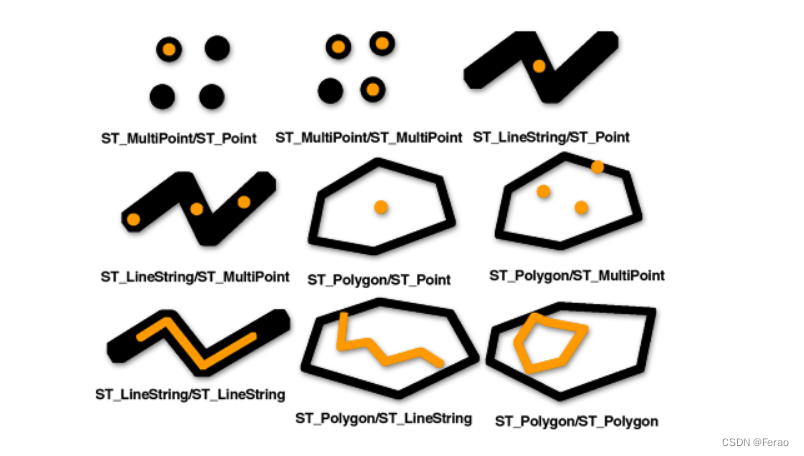
• ST_Crosses(a,b): 如果a横跨b,则返回1,否则返回0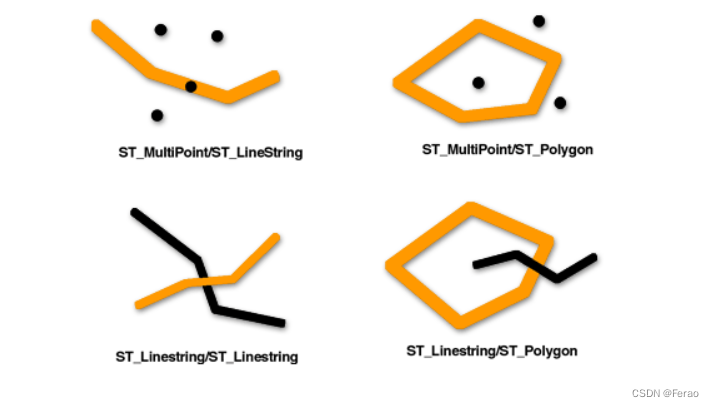
• ST_Disjoint(a,b): 如果a和b不相交,则返回1.否则返回0
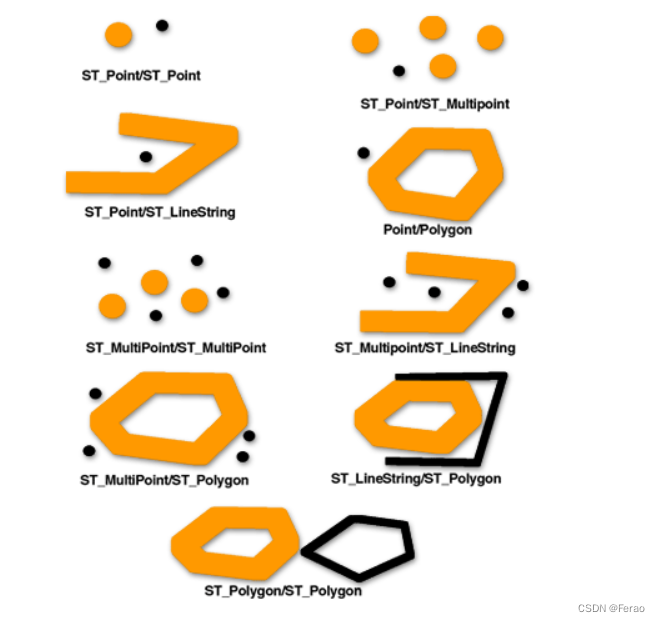
• ST_Equals(a,b): 如果a和b有相同的几何描述,则返回1, 否则返回0; 例如一栋楼的两层xy坐标描述一致,所以返回为1
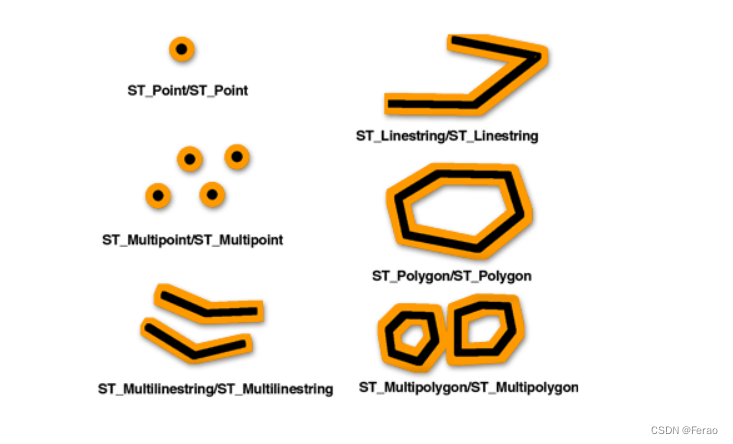
• ST_Touches(a,b): 几何对象a交且只交于b的边界时, 返回1, 否则0

• ST_Intersects(a,b): 与ST_Disjoint结果完全相反
• ST_Overlaps(a,b): 两个维度相同的几何对象相交的交集是一样维度的几何对象时, 返回1 , 否则返回0
• ST_Within(a,b): 与ST_Contains(a,b)结果完全相反 -
描述语言转化成几何对象
• geomfromtext(‘’): 空间函数中, 参数不可直接写空间描述格式, 需要用geomfromtext(‘’)来将描述语言转化成函数的对象,例如, 要查找test表中, 所有和 POLYGON((4 4, 4 6, 6 6, 6 4,4 4)) 相交的多边形, 则sql写为select polygon1 from test where st_disjoint(geomfromtext(‘POLYGON((4 4, 4 6, 6 6, 6 4,4 4))’),polygon1) = 0
-
-
附:MySQL空间相关函数一览表
名称 描述 Area() 返回Polygon或MultiPolygon区域 AsBinary() AsWKB()从内部几何格式转换为WKB AsText() AsWKT()从内部几何格式转换为WKT Buffer() 返回距离几何体给定距离内的点的几何 Centroid() 以质心为点 Contains() 一个几何的MBR是否包含另一个的MBR Crosses() 一个几何是否与另一个几何相交 Dimension() 几何尺寸 Disjoint() 两个几何的MBR是否不相交 EndPoint() LineString的结束点 Envelope() 返回几何体的MBR Equals() 两个几何的MBR是否相等 ExteriorRing() 返回Polygon的外环 GeometryCollection() 从几何构造几何集合 GeometryN() 从几何集合中返回第N个几何 GeometryType() 返回几何类型的名称 GLength() 返回LineString的长度 InteriorRingN() 返回Polygon的第N个内环 Intersects() 两个几何的MBR是否相交 IsClosed() 几何是否闭合且简单 IsEmpty() 占位符功能 IsSimple() 几何是否简单 LineString() 从Point值构造LineString X() 返回Point的X坐标 Y() 返回Point的Y坐标 ST_X() 返回Point的X坐标 ST_Y() 返回Point的Y坐标 ST_PointFromText() 从WKT构造Point ST_PointFromWKB() 从WKB构造Point ST_Intersects() 一个几何是否与另一个几何相交 ST_Intersection() 两个几何的返回点集交集 ST_Area() 返回Polygon或MultiPolygon区域 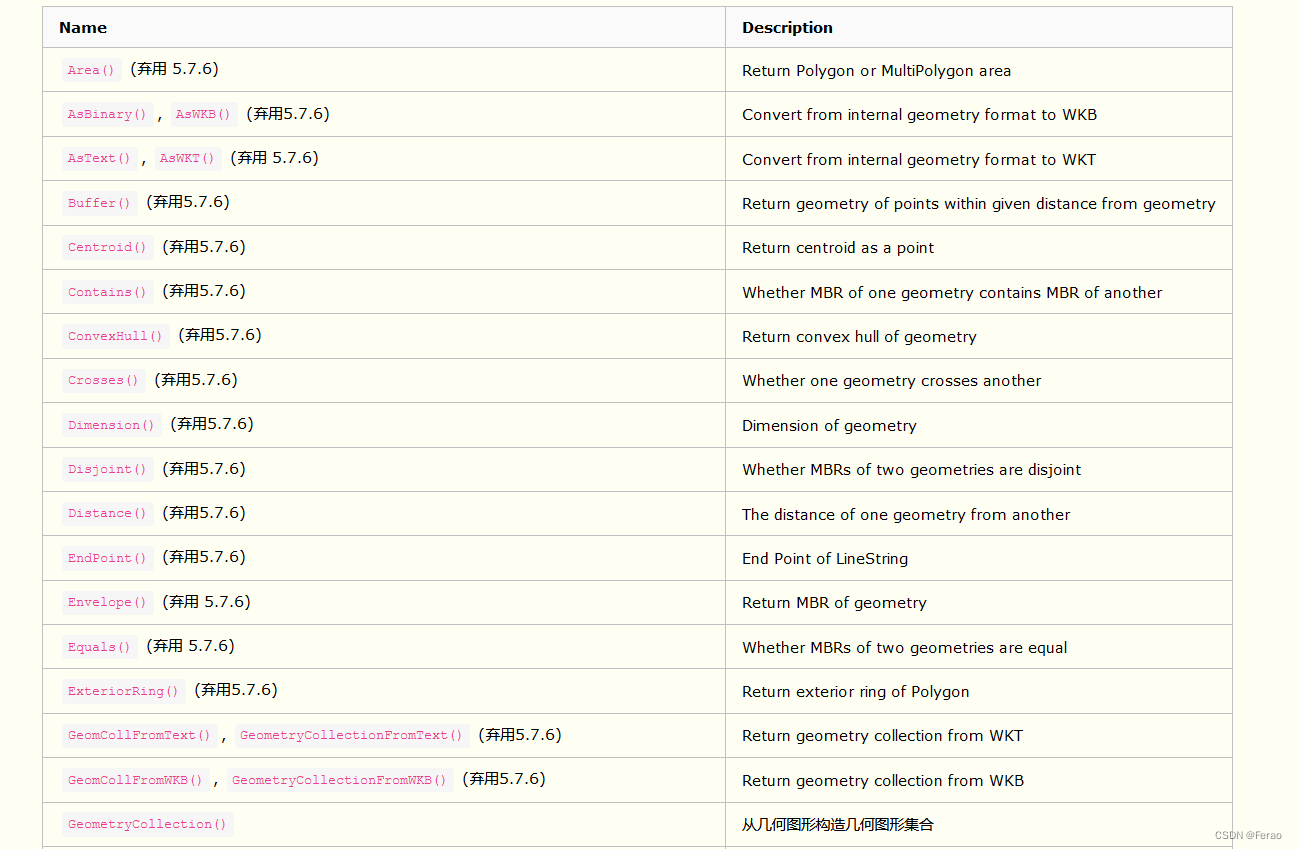







下面记录一下简单的使用
-
创建一个带有空间索引的表
我这里主要是用于检索遥感影像数据的,这里就只创建了两个字段,一个是影像路径path,一个是有效外包框box。
CREATE TABLE `gim` ( `path` varchar(512) NOT NULL, `box` geometry NOT NULL, PRIMARY KEY (`path`), SPATIAL KEY `box` (`box`) );这里创建好之后,就可以往里面插入数据了。
-
插入数据
数据的插入和普通的数据插入一样,只是geometry数据需要使用st_geomfromtext等函数来构造.
这里只展示一个简单数据插入,这里我使用的是单多边形,只有四个点(逆时针顺序),使用WKT描述几何数据
INSERT INTO gim ( path, box ) VALUES ( '%s', ST_GeomFromText ( 'Polygon((116.18866 39.791107, 116.124115 39.791107, 116.18866 39.833679, 116.124115 39.833679, 116.18866 39.791107))' )); -
查询数据
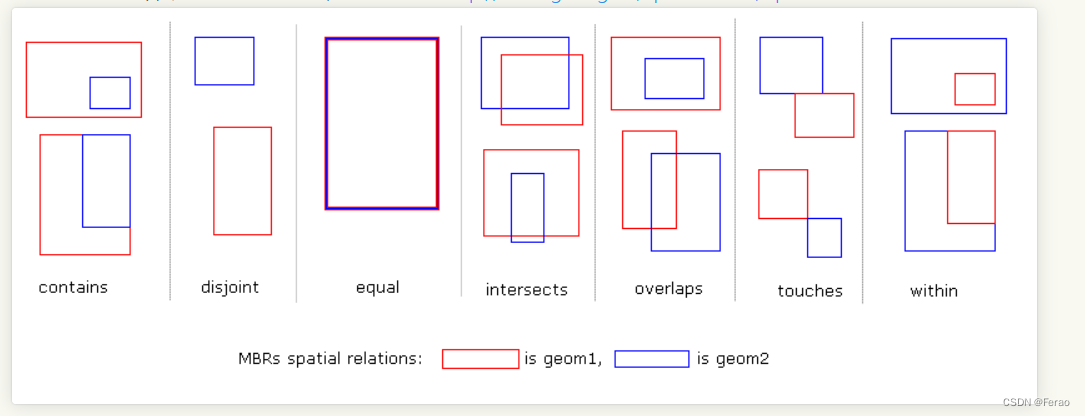
查询这里和普通的查询也一样,只是where字句后面使用空间过滤相关选项就是。MySQL的文档中只提及了MBRContains和MBRWithin两种方式,经过测试,MBRIntersects、MBREqual、MBROverlaps、MBRTouches、MBRDisjoint都可以使用。
SpatiaLite中有一幅关于空间检索的图,放在这里做个参考。
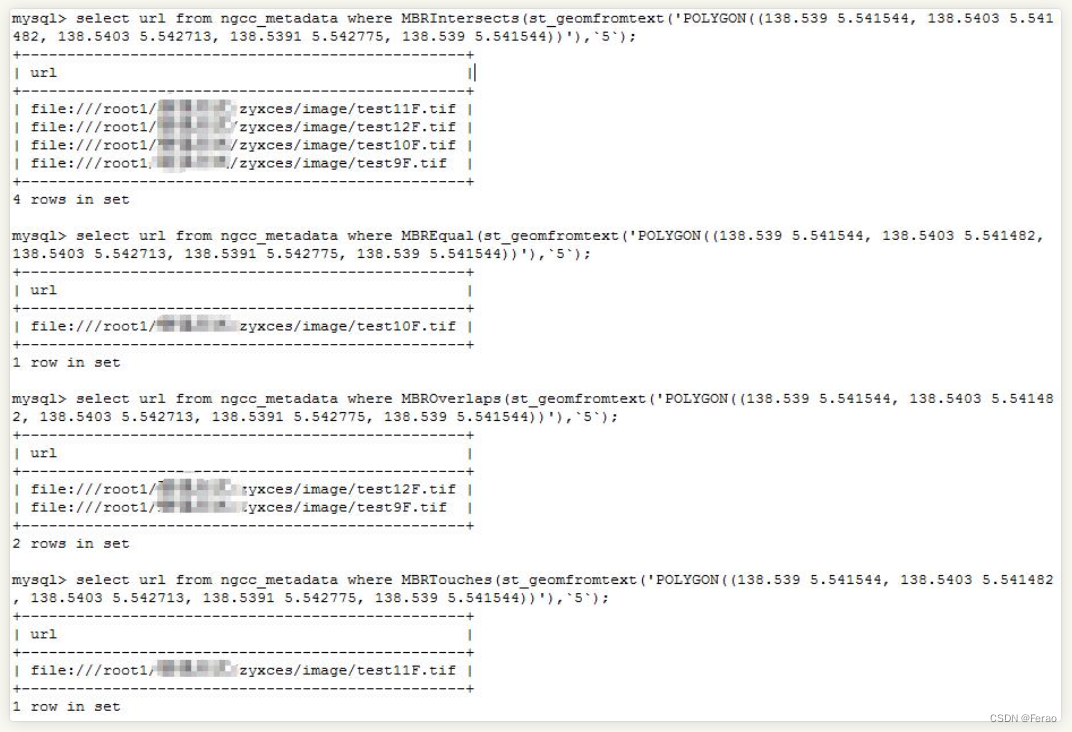
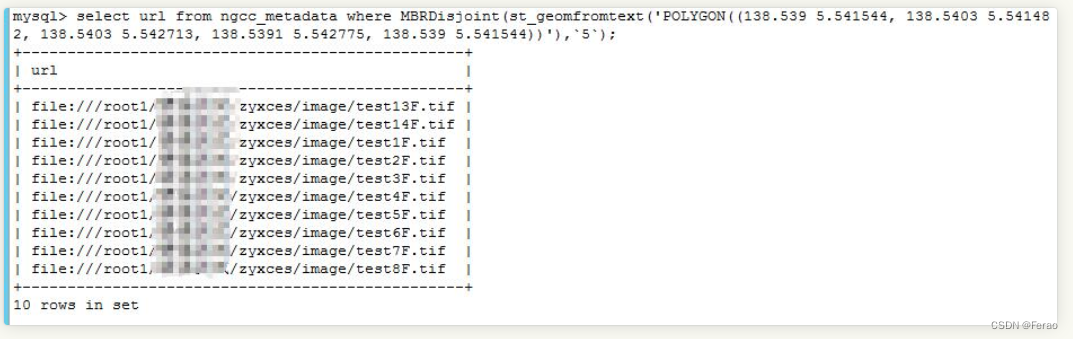
一个简单的查询示例:SELECT * FROM gim WHERE MBRContains ( st_geomfromtext ( 'polygon((116.438599 39.832306, 116.374054 39.832306, 116.438599 39.876251, 116.374054 39.876251, 116.438599 39.832306))' ), box );返回结果如下:

执行计划(explain)
执行计划(explain)用于优化SQL,在查询语句前增加explain 关键字即可,会返回执行相关的信息。
如:explain select * from t3 t where id = '111'

执行计划中各信息内容:
| 列 | 内容 | 参数 |
|---|---|---|
| id | 查询序列号 | |
| select_type | 查询的类型,根据关联、union、子查询等等分类,常见的查询类型有SIMPLE、PRIMARY | |
| table | 表示 explain 的一行正在访问哪个表 | |
| partitions | 分区 | |
| type | 决定如何查找表中的行 | 性能从最优到最差分别为: system > const(唯一索引)> eq_ref > ref (普通索引) > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL(全表扫描) |
| possible_keys 列 | 显示查询可能使用哪些索引来查找,使用索引优化sql的时候比较重要 | |
| key | 实际用到索引 | |
| key_len | 索引长度 | |
| ref 列 | ref 列展示的就是与索引列作等值匹配的值,常见的有:const(常量),func,NULL,字段名 | |
| rows 列 | 这也是一个重要的字段,MySQL查询优化器根据统计信息,估算SQL要查到结果集需要扫描读取的数据行数,这个值非常直观显示SQL的效率好坏,原则上rows越少越好 | |
| Extra 列 | 额外信息 | Using index:使用覆盖索引,以避免回表 Using where:表示会在存储引擎检索之后再进行过滤 Using temporary :表示对查询结果排序时会使用一个临时表 |
type 列拓展信息内容:
| 类型 | 内容 |
|---|---|
| system | 当表仅有一行记录时(系统表),数据量很少,往往不需要进行磁盘IO,速度非常快 |
| const | 通过索引一次就可以找到。即找到值就结束扫描返回查询结果 |
| ref | 非唯一性索引扫描。找到值还要继续扫描,直到将索引文件扫描完为止 |
| all | 全表扫描 |
• eq_ref:查询时命中主键primary key 或者 unique key索引, type 就是 eq_ref
• ref_or_null:这种连接类型类似于 ref,区别在于 MySQL会额外搜索包含NULL值的行
• index_merge:使用了索引合并优化方法,查询使用了两个以上的索引
• unique_subquery:替换下面的 IN子查询,子查询返回不重复的集合
• index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值
• range:使用索引选择行,仅检索给定范围内的行。简单点说就是针对一个有索引的字段,给定范围检索数据。在where语句中使用 bettween…and、<、>、<=、in 等条件查询 type 都是 range
• index:Index 与ALL 其实都是读全表,区别在于index是遍历索引树读取,而ALL是从硬盘中读取
mysql优化
mysql优化主要分为以下四大方面:
• 设计:存储引擎,字段类型,范式与逆范式
• 功能:索引,缓存,分区分表
• 架构:主从复制,读写分离,负载均衡
• 合理SQL:测试,经验
-
sql优化思路
首先要定位慢SQL,主要通过两个途径:
• 慢查询日志:开启MySQL的慢查询日志,再通过一些工具比如mysqldumpslow去分析对应的慢查询日志,当然现在一般的云厂商都提供了可视化的平台
• 服务监控:可以在业务的基建中加入对慢SQL的监控,常见的方案有字节码插桩、连接池扩展、ORM框架过程,对服务运行中的慢SQL进行监控和告警找到慢SQL后,主要从两个方面考虑优化,SQL语句本身的优化,以及数据库设计的优化。
SQL语句本身的优化方面有:1. 避免不必要的列
2. 分页优化:延迟关联、书签方式
3. 索引优化:覆盖索引、低版本避免使用or、避免使用!=/<>、避免列上函数运算、正确使用联合索引
4. JOIN优化 :优化子查询、小表驱动大表、适当增加冗余字段、避免join太多表
5. 排序优化:利用索引扫描做排序
6. union优化:条件下推 -
limit分页查询优化
在mysql大数据量的基础下,分页中随着页码的增加,查询时间也会响应的增加。所以到了百万级别的数据量时,我们就需要优化已有的查询代码进行合理有效的分页。
为了测试现在建一个业务订单历史表(order_history),字段有id、type,模拟5709294条数据;
现在测试第一条语句:
select count(*) from orders_history;三次查询时间分别为:8903 ms、8323 ms、8401 ms
现在测试第二条语句:
select * from orders_history limit 1000,10;三次查询时间分别为:3040 ms、3063 ms、3018 ms
针对这种查询方式,下面测试查询记录量对时间的影响:
select * from orders_history where type=8 limit 10000,1; select * from orders_history where type=8 limit 10000,10; select * from orders_history where type=8 limit 10000,100; select * from orders_history where type=8 limit 10000,1000; select * from orders_history where type=8 limit 10000,10000;三次查询时间如下:
查询1条记录:3072ms 3092ms 3002ms
查询10条记录:3081ms 3077ms 3032ms
查询100条记录:3118ms 3200ms 3128ms
查询1000条记录:3412ms 3468ms 3394ms
查询10000条记录:3749ms 3802ms 3696ms另外我还做了十来次查询,从查询时间来看,基本可以确定,在查询记录量低于100时,查询时间基本没有差距,随着查询记录量越来越大,所花费的时间也会越来越多。
针对查询偏移量的测试:
select * from orders_history where type=8 limit 100,100; select * from orders_history where type=8 limit 1000,100; select * from orders_history where type=8 limit 10000,100; select * from orders_history where type=8 limit 100000,100; select * from orders_history where type=8 limit 1000000,100;三次查询时间如下:
查询100偏移:25ms 24ms 24ms
查询1000偏移:78ms 76ms 77ms
查询10000偏移:3092ms 3212ms 3128ms
查询100000偏移:3878ms 3812ms 3798ms
查询1000000偏移:14608ms 14062ms 14700ms随着查询偏移的增大,尤其查询偏移大于10万以后,查询时间急剧增加。
出现慢的原因是limit 1000000,100的意思扫描满足条件的1000100行,扔掉前面的1000000行,返回最后的100行,问题就在这里,其实我们每次都只是需要100行的数据内容,那么到后面每次查询需要扫描超过100W+行,性能肯定大打折扣。
解决方式是对超过特定阈值的页数进行 SQL改写为使用子查询优化:
select * from orders_history where type=8 limit 100000,1; select id from orders_history where type=8 limit 100000,1; #这种方式先定位偏移位置的 id,然后往后查询,这种方式适用于 id 递增的情况。 select * from orders_history where type=8 and id>= (select id from orders_history where type=8 limit 100000,1) limit 100; select * from orders_history where type=8 limit 100000,100;4条语句的查询时间如下:
第1条语句:3674ms
第2条语句:1315ms
第3条语句:1327ms
第4条语句:3710ms上面的查询的原理是:利用覆盖索引来进行查询操作,避免回表。如果一本书需要知道第 11 章是什么标题,会翻开第 11 章对应的那一页吗?目录浏览一下就好,这个目录就是起到覆盖索引的作用。我们语句中的覆盖索引就使用的就是直接拿到我们要查询的20条数据的id,再去表中查询它的具体数据
-
使用 id 限定优化
这种方式假设数据表的id是连续递增 的,则我们根据查询的页数和查询的记录数可以算出查询的id的范围,可以使用 id between and 来查询:
select * from orders_history where type=2 and id between 1000000 and 1000100 limit 100;查询时间:15ms 12ms 9ms
这种查询方式能够极大地优化查询速度,基本能够在几十毫秒之内完成。限制是只能使用于明确知道id的情况,不过一般建立表的时候,都会添加基本的id字段,这为分页查询带来很多便利。
还可以有另外一种写法:
select * from orders_history where id >= 1000001 limit 100;当然还可以使用 in 的方式来进行查询,这种方式经常用在多表关联的时候进行查询,使用其他表查询的id集合,来进行查询:
select * from orders_history where id in (select order_id from trade_2 where goods = 'pen') limit 100;这种 in 查询的方式要注意:某些 mysql 版本不支持在 in 子句中使用 limit。
-
使用临时表优化
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
关于数据表的id说明
一般情况下,在数据库中建立表的时候,强制为每一张表添加 id 递增字段,这样方便查询。
如果像是订单库等数据量非常庞大,一般会进行分库分表。这个时候不建议使用数据库的 id 作为唯一标识,而应该使用分布式的高并发唯一 id 生成器来生成,并在数据表中使用另外的字段来存储这个唯一标识。
使用先使用范围查询定位 id (或者索引),然后再使用索引进行定位数据,能够提高好几倍查询速度。即先 select id,然后再 select *;
-
-
回表查询和覆盖索引
数据库表结构:
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engine=innodb;select id,name where name='shenjian' select id,name,sex where name='shenjian'• 多查询了一个属性,为何检索过程完全不同?
• 什么是回表查询?
• 什么是索引覆盖?
• 如何实现索引覆盖?
• 哪些场景可以利用索引覆盖优化sql?什么是回表查询?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
• 聚集索引(clustered index)
• 普通索引(secondary index)InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
1)如果表定义了PK,则PK就是聚集索引;
2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;InnoDB普通索引的叶子节点存储主键值。注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B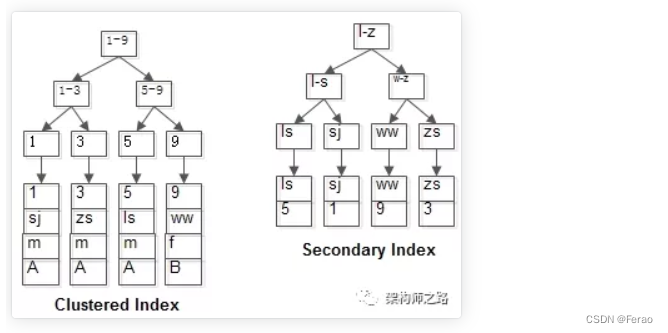
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
例如:
select * from t where name='lisi';是如何执行的呢?
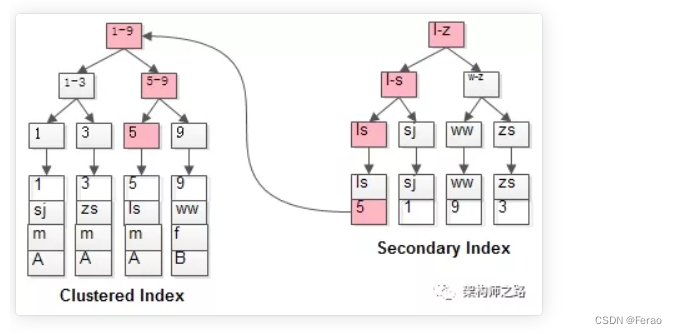
如粉红色路径,需要扫码两遍索引树:
• 1)先通过普通索引定位到主键值id=5;
• 2)在通过聚集索引定位到行记录;这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
什么是索引覆盖(Covering index)?
借用一下SQL-Server官网的说法。

MySQL官网,类似的说法出现在explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。

不管是SQL-Server官网,还是MySQL官网,都表达了:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。如何实现覆盖索引?
常见的方法是:将被查询的字段,建立到联合索引里去。
仍是之前中的例子:
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engine=innodb;第一个SQL语句:
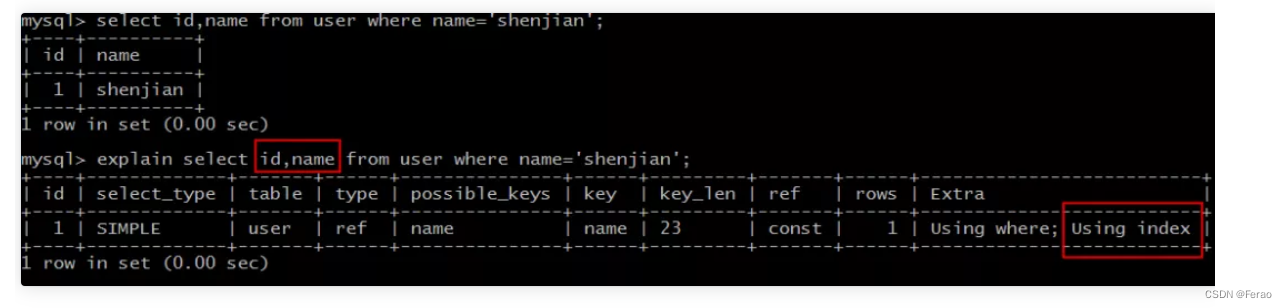
select id,name from user where name='shenjian';能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
第二个SQL语句:
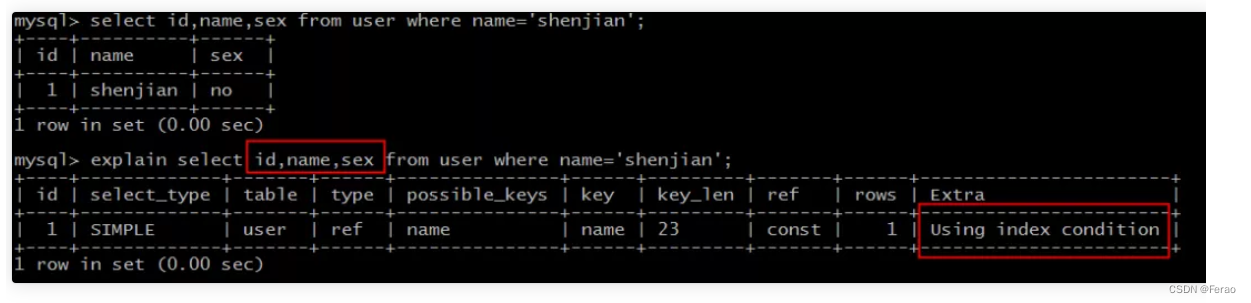
select id,name,sex from user where name='shenjian';能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name, sex) )engine=innodb;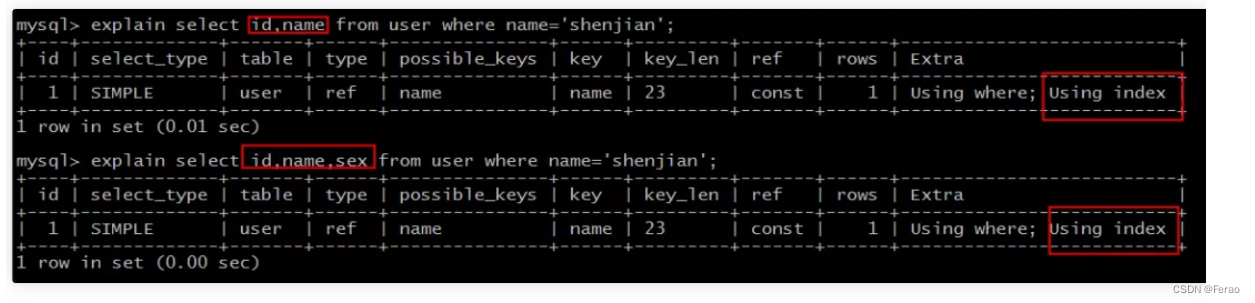
select id,name ... where name='shenjian'; select id,name,sex ... where name='shenjian';都能够命中索引覆盖,无需回表。
哪些场景可以利用索引覆盖优化sql?
-
场景1:全表count查询优化
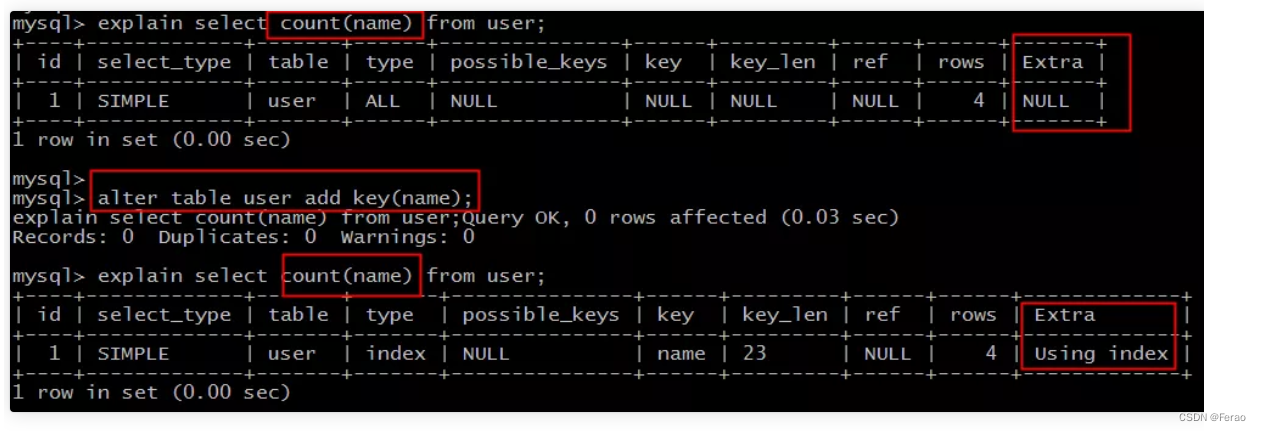
原表为:user(PK id, name, sex);
直接count(name)不能利用索引覆盖。添加索引后就能够利用索引覆盖提效。
-
列查询回表优化
select id,name,sex ... where name='shenjian';这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
-
分页查询
select id,name,sex ... order by name limit 500,100;将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
-
-
大批量数据的更新,插入,删除优化
场景:在执行load into语句的SQL将一个很大的文件导入到MySQL数据库中,执行了一段时间后报错“The total number of locks exceeds the lock table size”。
首先使用命令
show variables like '%storage_engine%'查看MySQL的存储引擎:mysql> show variables like '%storage_engine%'; +----------------------------------+--------+ | Variable_name | Value | +----------------------------------+--------+ | default_storage_engine | InnoDB | | default_tmp_storage_engine | InnoDB | | disabled_storage_engines | | | internal_tmp_disk_storage_engine | InnoDB | +----------------------------------+--------+ 4 rows in set, 1 warning (0.00 sec)可以看到InnoDB是MySQL的默认引擎。
报错“The total number of locks exceeds the lock table size”说明MySQL的默认配置已经无法满足你的需求了,
InnoDB表执行大批量数据的更新,插入,删除操作时会出现这个问题,
需要调整InnoDB全局的innodb_buffer_pool_size的值来解决这个问题,并且重启mysql服务。首先我们通过命令 show variables like “%_buffer_pool_size%” 查看MySQL缓存池的大小:
mysql> show variables like "%_buffer_pool_size%"; +-------------------------+---------+ | Variable_name | Value | +-------------------------+---------+ | innodb_buffer_pool_size | 8388608 | +-------------------------+---------+ 1 row in set, 1 warning (0.00 sec)可以看到,默认的缓存池大小是 8388608 = 8 * 1024 * 1024 = 8 MB。我们需要把它改大一点。
那么到底是多少呢,就是说你剩多少内存,用多少内存咯,我估计我有个3个G的内存可以用,
那么我可以将innodb_buffer_pool_size的值设成310241024*1024=3221225472。
然后我们配置一下``文件(MySQL Installer安装的话,这个是配置文件的默认位置),将innodb_buffer_pool_size=8M修改为:
innodb_buffer_pool_size=3G对于这个值的配置,其实在配置文件中也给了说明:
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and # row data. The bigger you set this the less disk I/O is needed to # access data in tables. On a dedicated database server you may set this # parameter up to 80% of the machine physical memory size. Do not set it # too large, though, because competition of the physical memory may # cause paging in the operating system. Note that on 32bit systems you # might be limited to 2-3.5G of user level memory per process, so do not # set it too high.然后重启mysqld服务。(可通过命令行执行services.msc进入服务窗口)
然后在命令行执行命令查看此时的缓存池大小:mysql> show variables like "%_buffer_pool_size%"; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 3221225472 | +-------------------------+------------+ 1 row in set, 1 warning (0.00 sec)可以看到这个值已经修改成了我们想要的大小 —— 3GB。再次运行我的导入文件的SQL,发现可以了,而且还很快呢。
但是内存也是有些吃紧的。
索引优化
-
where情况优化
-
基础SQL(无索引)
explain select * from t3 t where id = '111'观察到type为all(全表扫描)

-
初步优化(添加唯一索引)
alter table t3 add unique key uniqueID(id);explain select * from t3 t where id = '111'观察到type为const,表示通过索引一次就可以找到

-
再次优化(覆盖索引)
explain select id from t3 t where id = '111'改为具体字段后,Extra 显示 Using index,表示该查询使用了覆盖索引,这是一个非常好的消息,说明该sql语句的性能很好

-
-
order by情况优化
-
基础SQL(有id唯一索引)
explain select id from t3 t order by id,name
观察到使用type为all(全表扫描),并且Using temporary(使用临时表),表明该sql需要立即优化了 -
初步优化(添加复合索引)
alter table t3 add index multipleIndex(id,name);explain select id from t3 t order by id,name
将查询字段修改为具体字段:explain select id from t3 t order by id,name
但实际业务需要返回全部字段,可使用force index 强制指定索引explain select * from t3 t force index(multipleIndex) order by id,name
-
sql慢查询分析
如果在数据库查询流程比较慢的话,我们可以通过开启profiling看到流程慢在哪。
mysql> set profiling=ON;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show variables like 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | ON |
+---------------+-------+
1 row in set (0.00 sec)
然后正常执行sql语句。
这些SQL语句的执行时间都会被记录下来,此时你想查看有哪些语句被记录下来了,可以执行 show profiles;
mysql> show profiles;
+----------+------------+---------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------+
| 1 | 0.06811025 | select * from user where age>=60 |
| 2 | 0.00151375 | select * from user where gender = 2 and age = 80 |
| 3 | 0.00230425 | select * from user where gender = 2 and age = 60 |
| 4 | 0.00070400 | select * from user where gender = 2 and age = 100 |
| 5 | 0.07797650 | select * from user where age!=60 |
+----------+------------+---------------------------------------------------+
5 rows in set, 1 warning (0.00 sec)
关注下上面的query_id,比如select * from user where age>=60对应的query_id是1,如果你想查看这条SQL语句的具体耗时,那么可以执行以下的命令。
mysql> show profile for query 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000074 |
| checking permissions | 0.000010 |
| Opening tables | 0.000034 |
| init | 0.000032 |
| System lock | 0.000027 |
| optimizing | 0.000020 |
| statistics | 0.000058 |
| preparing | 0.000018 |
| executing | 0.000013 |
| Sending data | 0.067701 |
| end | 0.000021 |
| query end | 0.000015 |
| closing tables | 0.000014 |
| freeing items | 0.000047 |
| cleaning up | 0.000027 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)
通过上面的各个项,大家就可以看到具体耗时在哪。比如从上面可以看出Sending data的耗时最大,这个是指执行器开始查询数据并将数据发送给客户端的耗时,因为我的这张表符合条件的数据有好几万条,所以这块耗时最大,也符合预期。
一般情况下,我们开发过程中,耗时大部分时候都在Sending data阶段,而这一阶段里如果慢的话,最容易想到的还是索引相关的原因。
sql行列互转
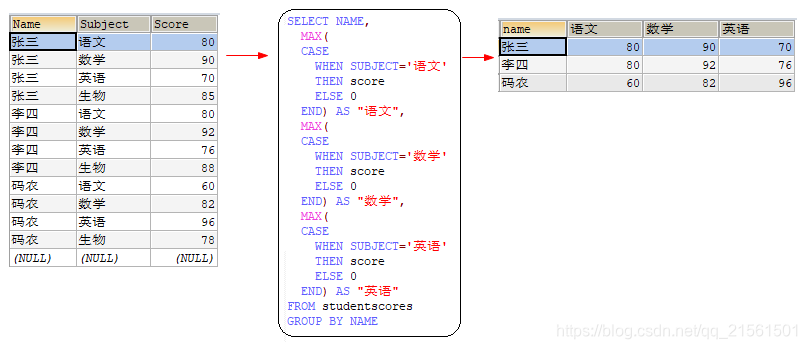
行列转换在做报表分析时还是经常会遇到的,形式下图两种展示形式的互相转换
首先准备测试SQL:
CREATE TABLE StudentScores
(
UserName NVARCHAR(20) COMMENT '学生姓名',
SUBJECT NVARCHAR(30) COMMENT '科目',
Score FLOAT COMMENT '成绩'
)
INSERT INTO StudentScores SELECT '张三', '语文', 80;
INSERT INTO StudentScores SELECT '张三', '数学', 90;
INSERT INTO StudentScores SELECT '张三', '英语', 70;
INSERT INTO StudentScores SELECT '张三', '生物', 85;
INSERT INTO StudentScores SELECT '李四', '语文', 80;
INSERT INTO StudentScores SELECT '李四', '数学', 92;
INSERT INTO StudentScores SELECT '李四', '英语', 76;
INSERT INTO StudentScores SELECT '李四', '生物', 88;
INSERT INTO StudentScores SELECT '码农', '语文', 60;
INSERT INTO StudentScores SELECT '码农', '数学', 82;
INSERT INTO StudentScores SELECT '码农', '英语', 96;
INSERT INTO StudentScores SELECT '码农', '生物', 78;
明确需要转变成的最终结果

编写SQL:
SELECT NAME,
MAX(
CASE
WHEN SUBJECT='语文'
THEN score
ELSE 0
END) AS "语文",
MAX(
CASE
WHEN SUBJECT='数学'
THEN score
ELSE 0
END) AS "数学",
MAX(
CASE
WHEN SUBJECT='英语'
THEN score
ELSE 0
END) AS "英语"
FROM studentscores
GROUP BY NAME
现在进行列转行:
SELECT
NAME,
'语文' AS subject ,
MAX("语文") AS score
FROM student1 GROUP BY NAME
UNION
SELECT
NAME,
'数学' AS subject ,
MAX("数学") AS score
FROM student1 GROUP BY NAME
UNION
SELECT
NAME,
'英语' AS subject ,
MAX("英语") AS score
FROM student1 GROUP BY NAME

数据库的设计
数据库设计前须知的基础内容>>
多表之间的关系
-
分类
- 一对一 (了解)
如:人和身份证
分析:一个人只有一个身份证,一个身份证只能对应一个人 - 一对多(多对一)
如:部门和员工
分析:一个部门有多个员工,一个员工只能对应一个部门 - 多对多:
如: 学生和课程
分析:一个学生可以选择很多课程,一个课程也可以被很多学生选择
- 一对一 (了解)
-
实现
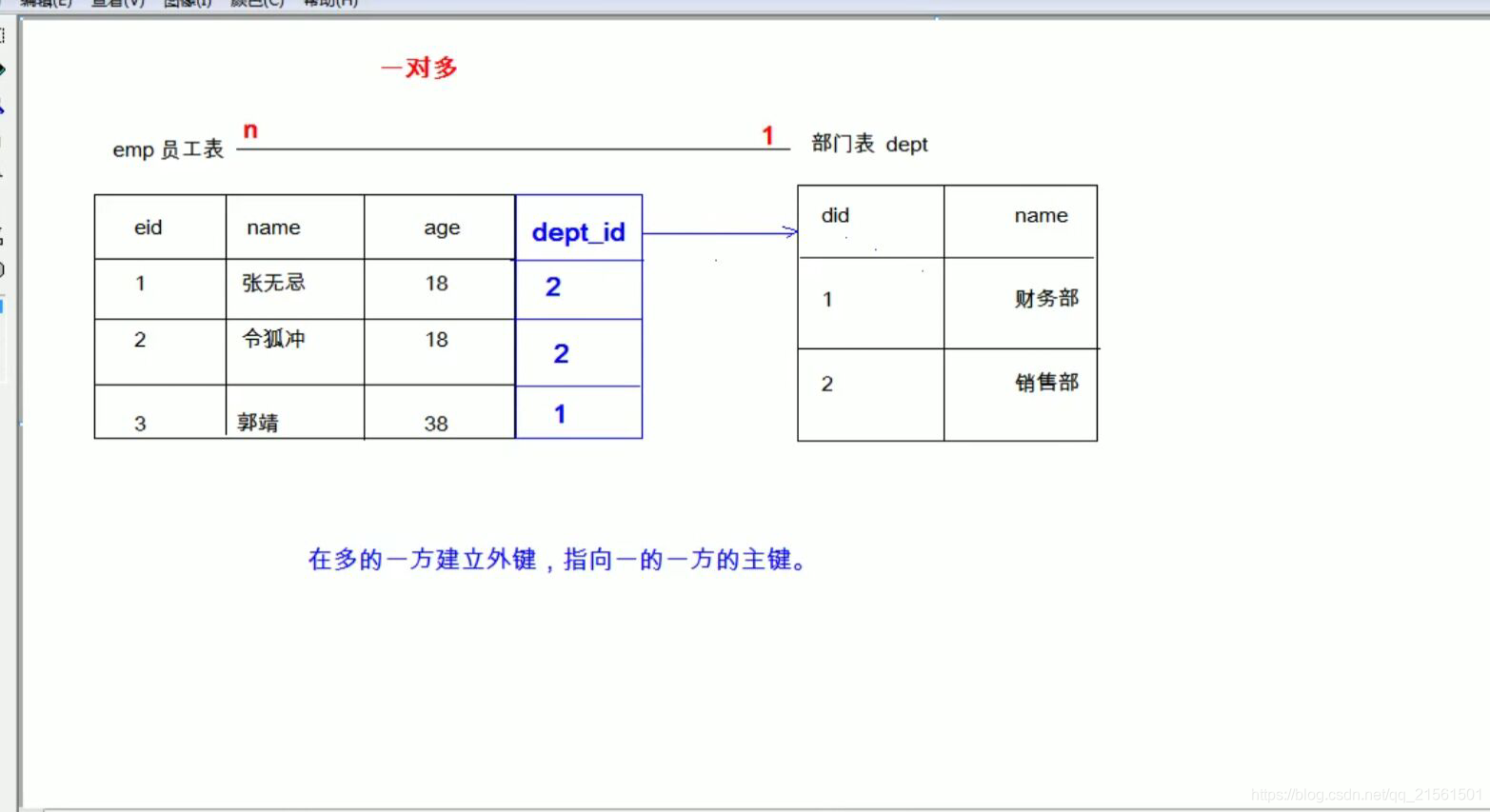
- 一对多(多对一):
* 如:部门和员工
* 实现方式:在多的一方建立外键,指向一的一方的主键 - 多对多:
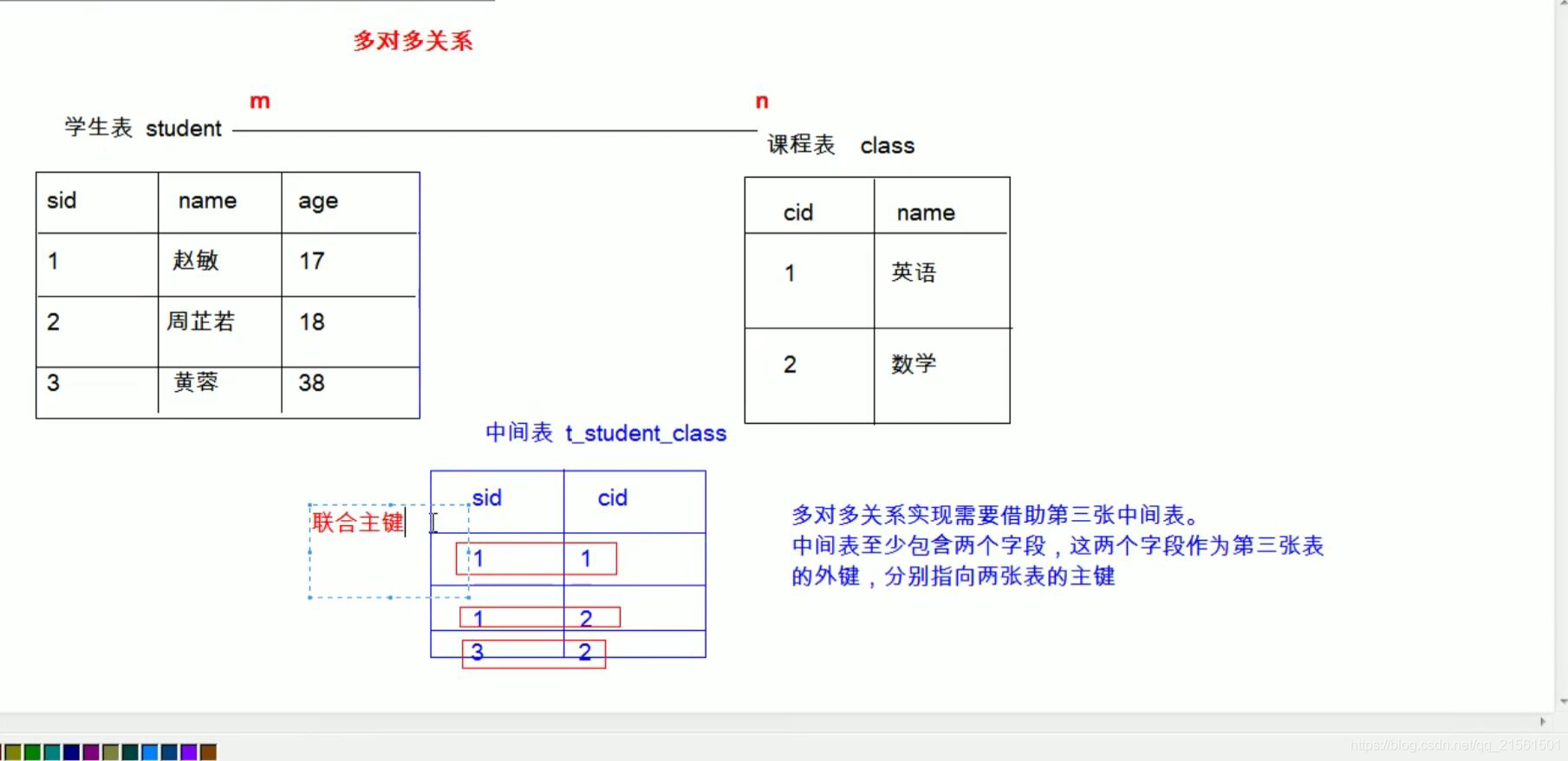
* 学生和课程
* 实现方式:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键 - 一对一(了解):
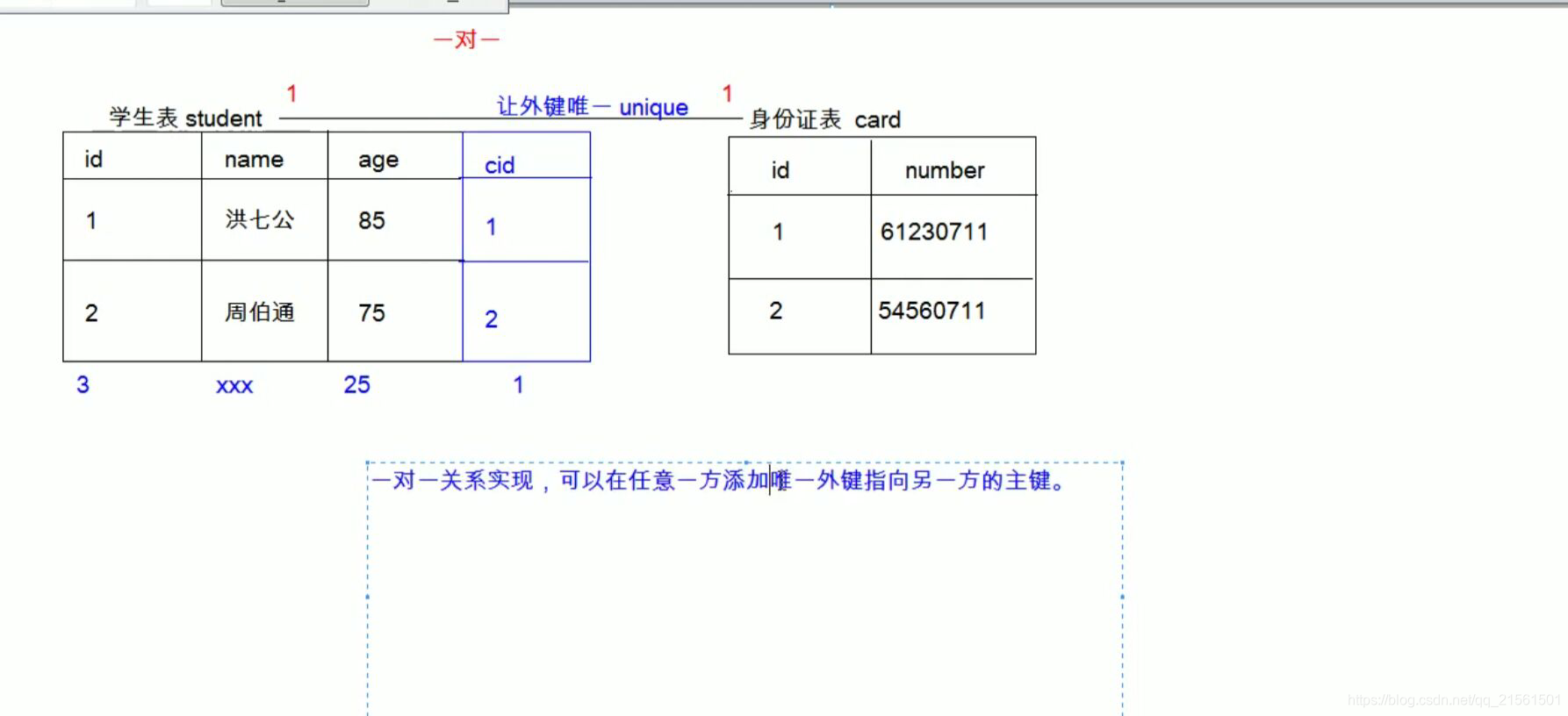
* 如:人和身份证
* 实现方式:一对一关系实现,可以在任意一方添加唯一外键指向另一方的主键
- 一对多(多对一):
2. 数据库设计的范式
设计数据库时,需要遵循的一些规则,要遵循后边的范式要求,必须先遵循前边的所有范式要求
分类
-
第一范式:(1NF):每一列都是不可分割的院子数据项
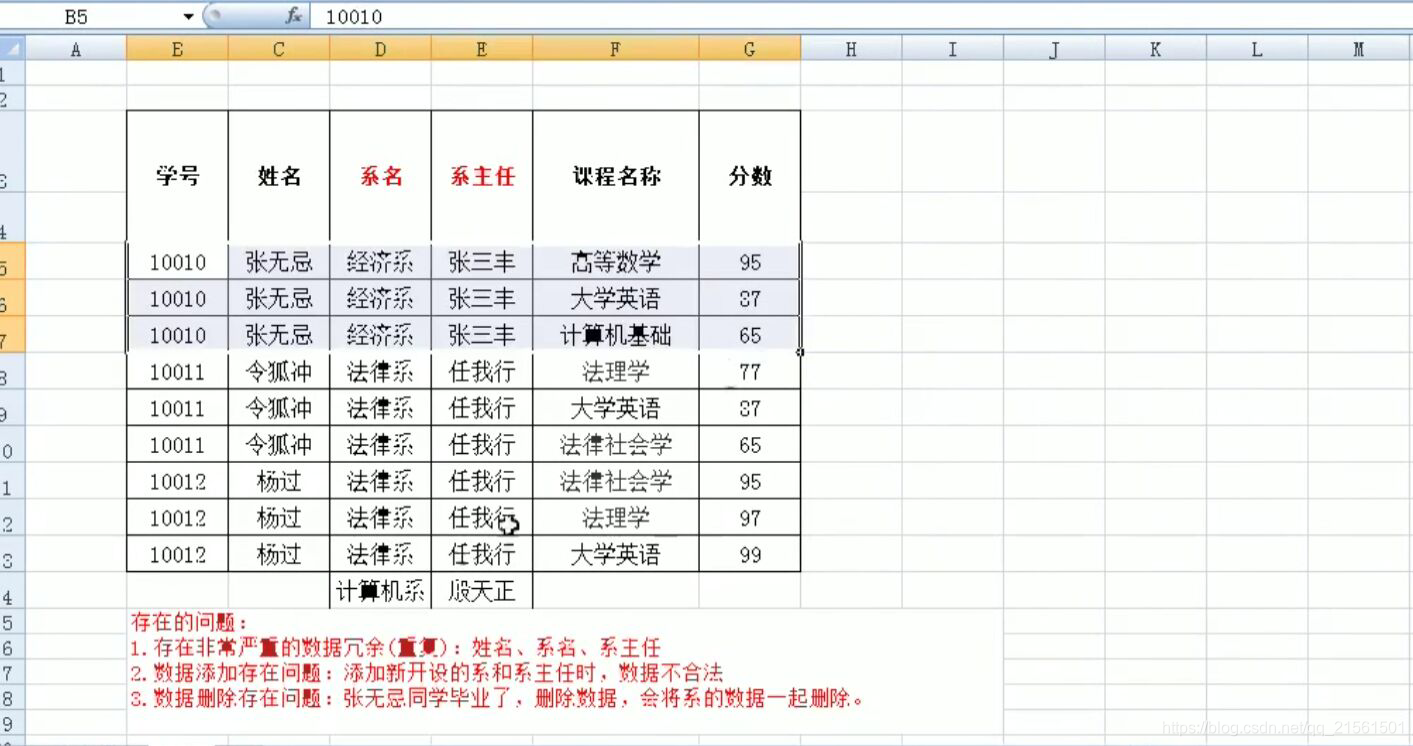
-
第二范式:(2NF):在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
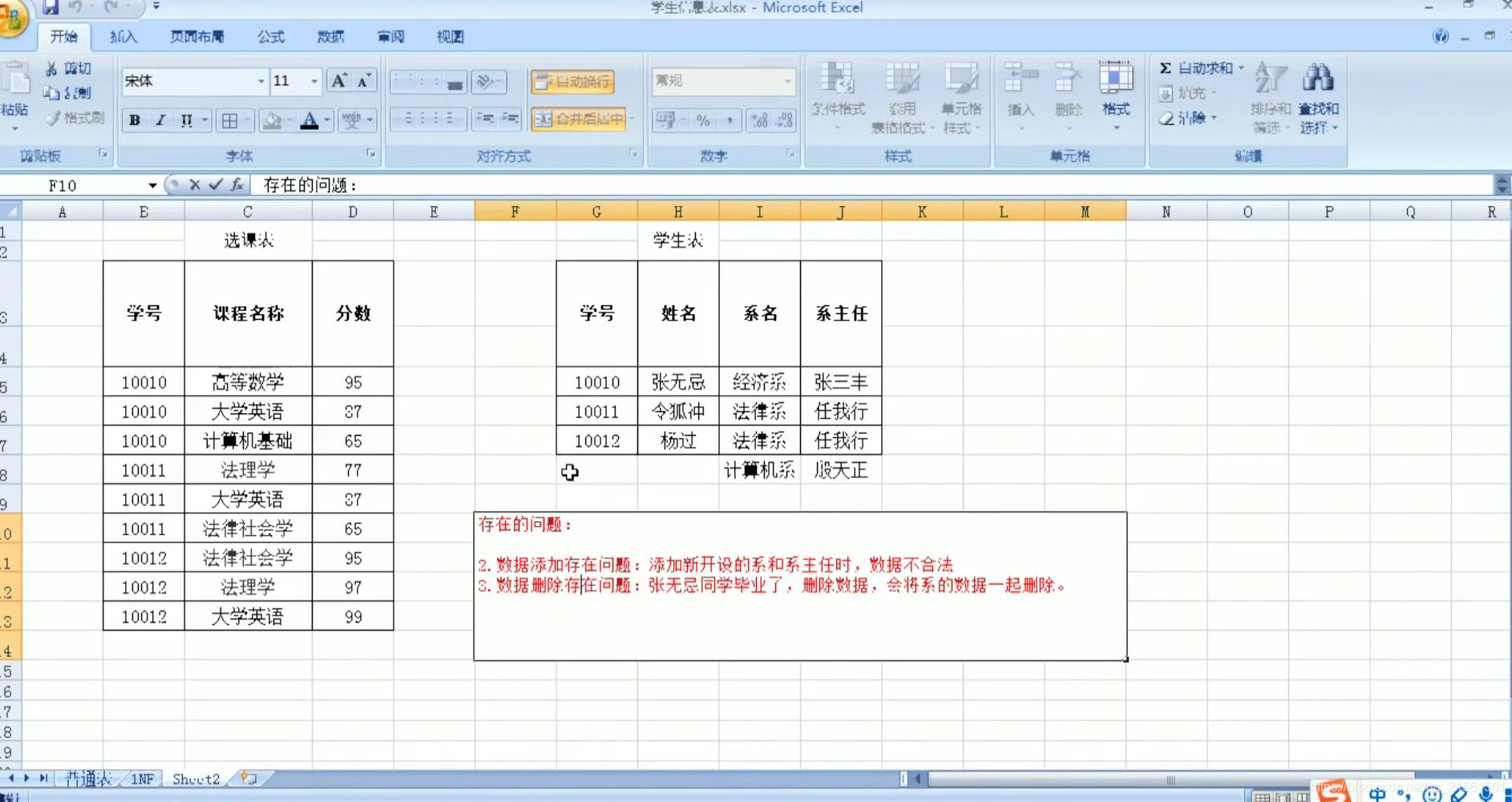 几个概念:
几个概念:- 函数依赖:A-- >B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
例如:学号-->姓名 (学号,课程名称)--> 分数 - 完全函数依赖:A–>B,如果A是一个属性组,则B属性值的确定需要依赖于A属性组中所有的属性值
例如:(学号,课程名称)-->分数 - 部分函数依赖:A–>B,如果A是一个属性组,则B属性值的确定只需要依赖于A属性组的某一些值即可
例如:(学号,课程名称)-->姓名 - 传递属性依赖:A–>B , B–>C,如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称C传递函数依赖于A
例如:学号-->系名 ,系名-->系主任 - 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
主属性:码属性组中的所有属性
非主属性:除过码属性组的属性
- 函数依赖:A-- >B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
-
第三范式:(3NF):在2NF基础上,任何主属性不依赖于其他非主属性(在2NF基础上消除传递依赖)

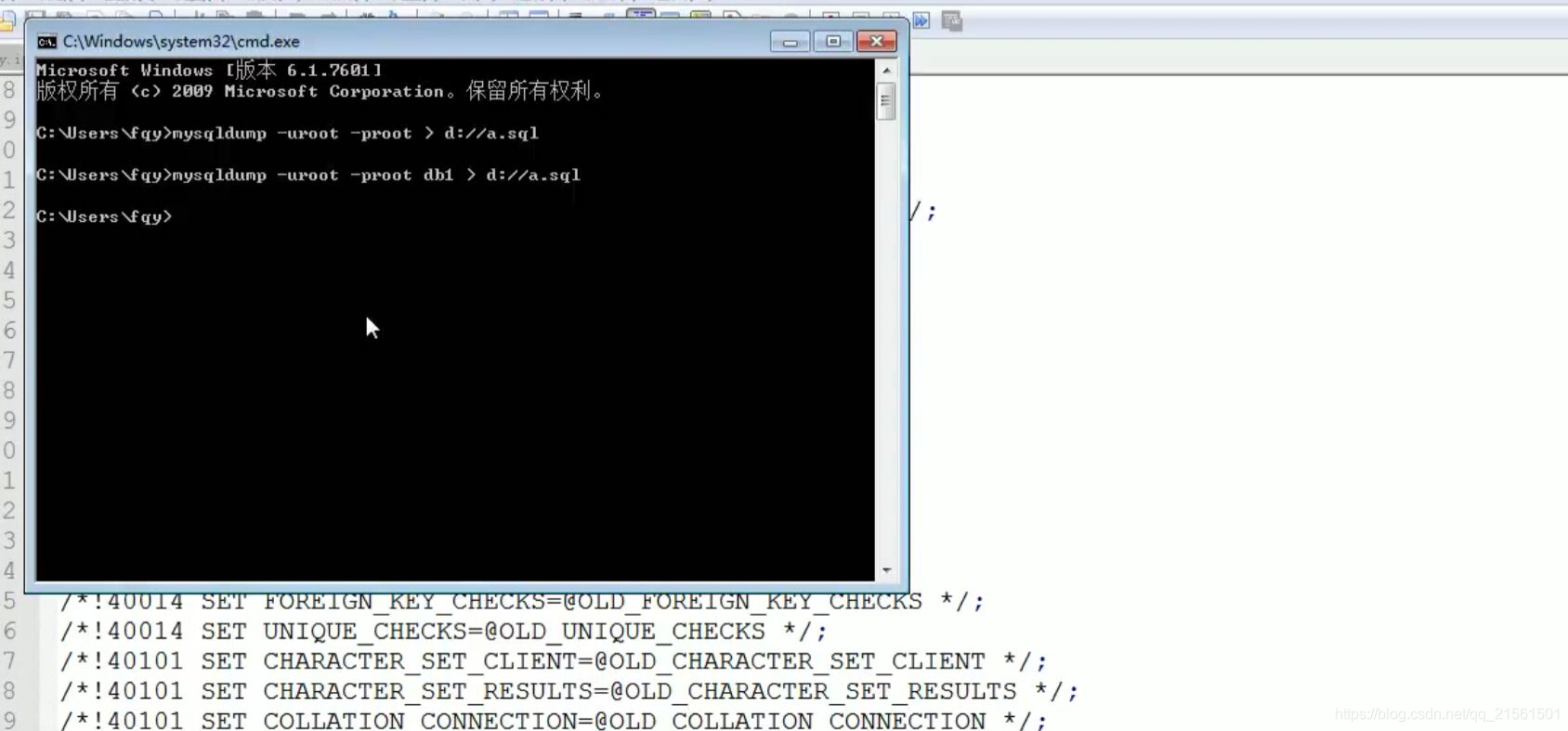
拓展数据库的备份与还原:
*命令行:
语法:
备份:Mysqldump -u用户名 -p密码 数据库名称 >保存的路径
还原:
*登录数据库
*创建数据库
*使用数据库
*执行文件。source 文件路径
mysql锁定机制
-
定义
简单来说,就是数据库为了保证数据的一致性,而使各种共享资源在被并发访问变得有序所设计的一种规则。
mysql每种存储引擎的锁定机制都是为各自所面对的特定场景而优化设计,所以各存储引擎的锁定机制也有较大区别.
-
锁定机制类型
• 表级锁定
• 行级锁定
• 页级锁定 -
锁机制演变
MySQL的存储引擎是从MyISAM到InnoDB,锁从表锁到行锁。
后者的出现从某种程度上是弥补前者的不足。比如:MyISAM不支持事务,InnoDB支持事务。表锁虽然开销小,锁表快,但高并发下性能低。行锁虽然开销大,锁表慢,但高并发下相比之下性能更高。
事务和行锁都是在确保数据准确的基础上提高并发的处理能力。
表级锁定
-
定义
一次会将整个表锁定。使用表级锁定的主要是一些非事务性存储引擎:
• MyISAM
• MEMORY
• CSV -
场景
InnoDB默认采用行锁,在未使用索引字段查询时升级为表锁。
MySQL这样设计并不是给你挖坑。它有自己的设计目的。
即便你在条件中使用了索引字段,MySQL会根据自身的执行计划,考虑是否使用索引(所以explain命令中会有possible_key 和 key)。如果MySQL认为全表扫描效率更高,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
行级锁定
-
定义
使用行级锁定的存储引擎主要是InnoDB。
行级锁定也最容易发生死锁。 -
InnoDB行锁
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁
页级锁定
-
定义
开销和加锁时间介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发处理能力一般。
分库分表
先抛几个问题:
a. 为什么要分库分表?什么时候才需要分库分表呢?我们的评判标准是什么?
b. 一张表存储了多少数据的时候,才需要考虑分库分表?
c. 数据增长速度很快,每天产生多少数据,才需要考虑做分库分表?
首先回答一下为什么要分库分表,答案很简单:数据库出现性能瓶颈。用大白话来说就是数据库快扛不住了。数据库出现性能瓶颈,对外表现有几个方面:
1.大量请求阻塞
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。
2.SQL 操作变慢
如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。
3.存储出现问题
业务量剧增,单库数据量越来越大,给存储造成巨大压力。
数据库出现性能瓶颈,对外表现有几个方面:
数据库相关优化方案
数据库优化方案很多,主要分为两大类:软件层面、硬件层面。
软件层面包括:数据库集群、分库分表等;
-
SQL 调优
SQL 调优往往是解决数据库问题的第一步,往往投入少部分精力就能获得较大的收益。
SQL 调优主要目的是尽可能的让那些慢 SQL 变快,手段其实也很简单就是让 SQL 执行尽量命中索引。
那么怎么找到慢SQL呢,方法如下:
1)开启慢 SQL 记录,如果你使用的是 Mysql,需要在 Mysql 配置文件中配置几个参数即可。
slow_query_log=on long_query_time=1 slow_query_log_file=/path/to/log2)使用调优的工具,常常会用到 explain 这个命令来查看 SQL 语句的执行计划,通过观察执行结果很容易就知道该 SQL 语句是不是全表扫描、有没有命中索引。
返回有一列叫“type”,常见取值有:
ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)ALL 代表这条 SQL 语句全表扫描了,需要优化。一般来说需要达到range 级别及以上。
-
表结构优化
以一个场景举例说明:
“user”表中有 user_id、nickname 等字段,“order”表中有order_id、user_id等字段,如果想拿到用户昵称怎么办?一般情况是通过 join 关联表操作,在查询订单表时关联查询用户表,从而获取导用户昵称。
但是随着业务量增加,订单表和用户表肯定也是暴增,这时候通过两个表关联数据就比较费力了,为了取一个昵称字段而不得不关联查询几十上百万的用户表,其速度可想而知。
这个时候可以尝试将 nickname 这个字段加到 order 表中(order_id、user_id、nickname),这种做法通常叫做数据库表冗余字段。这样做的好处展示订单列表时不需要再关联查询用户表了。
冗余字段的做法也有一个弊端,如果这个字段更新会同时涉及到多个表的更新,因此在选择冗余字段时要尽量选择不经常更新的字段。
-
读写分离
-
数据库集群
当单台数据库实例扛不住,我们可以增加实例组成集群对外服务。
当发现读请求明显多于写请求时,我们可以让主实例负责写,从实例对外提供读的能力;如果读实例压力依然很大,可以在数据库前面加入缓存如 redis,让请求优先从缓存取数据减少数据库访问。
缓存分担了部分压力后,数据库依然是瓶颈,这个时候就可以考虑分库分表的方案了,后面会详细介绍。
-
分库分表(下面详解)
…
硬件层面主要是增加机器性能。
[注]从机器的角度看,性能瓶颈无非就是CPU、内存、磁盘、网络这些,要解决性能瓶颈最简单粗暴的办法就是提升机器性能,但是通过这种方法成本和收益投入比往往又太高了,不划算,所以重点还是要从软件角度入手。
现在对分库分表进行重点详解
下面我们以一个商城系统为例逐步讲解数据库是如何一步步演进。
-
单应用单数据库
在早期创业阶段想做一个商城系统,基本就是一个系统包含多个基础功能模块,最后打包成一个 war 包部署,这就是典型的单体架构应用。
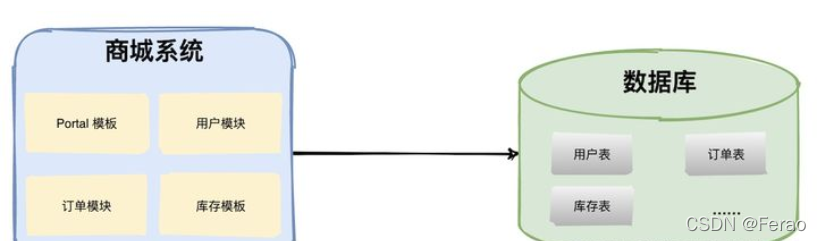
如上图,商城系统包括主页 Portal 模板、用户模块、订单模块、库存模块等,所有的模块都共有一个数据库,通常数据库中有非常多的表。因为用户量不大,这样的架构在早期完全适用,开发者可以拿着 demo到处找(骗)投资人。
一旦拿到投资人的钱,业务就要开始大规模推广,同时系统架构也要匹配业务的快速发展。
-
多应用单数据库
在前期为了抢占市场,这一套系统不停地迭代更新,代码量越来越大,架构也变得越来越臃肿,现在随着系统访问压力逐渐增加,系统拆分就势在必行了。
为了保证业务平滑,系统架构重构也是分了几个阶段进行。
第一个阶段将商城系统单体架构按照功能模块拆分为子服务,比如:Portal 服务、用户服务、订单服务、库存服务等。
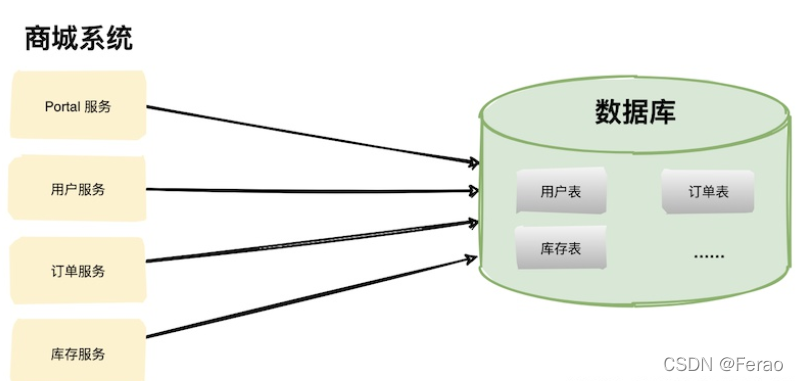
如上图,多个服务共享一个数据库,这样做的目的是底层数据库访问逻辑可以不用动,将影响降到最低。
-
多应用多数据库
随着业务推广力度加大,数据库终于成为了瓶颈,这个时候多个服务共享一个数据库基本不可行了。我们需要将每个服务相关的表拆出来单独建立一个数据库,这其实就是“分库”了。
单数据库的能够支撑的并发量是有限的,拆成多个库可以使服务间不用竞争,提升服务的性能。
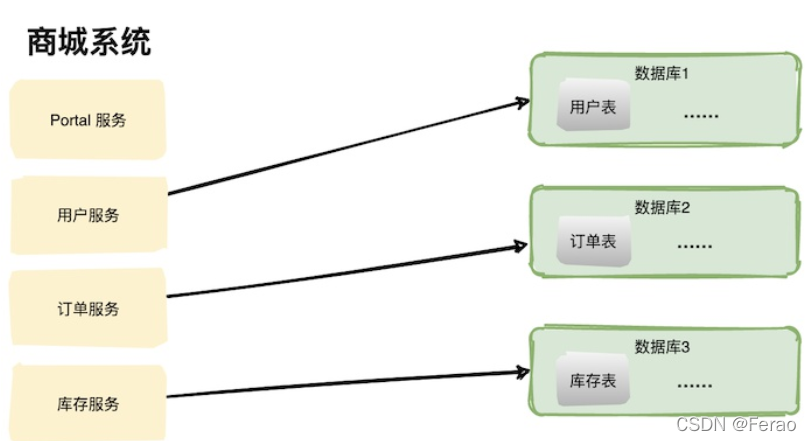
如上图,从一个大的数据中分出多个小的数据库,每个服务都对应一个数据库,这就是系统发展到一定阶段必要要做的“分库”操作。现在非常火的微服务架构也是一样的,如果只拆分应用不拆分数据库,不能解决根本问题,整个系统也很容易达到瓶颈。
-
分表
单表迁移分布式表思路
1. 统计该表总数据量 select count(1) from test_a //500000000 (5亿)
2. 统计该表占用内存(GB)情况
3. 统计迁移各节点服务器内存是否充足
4. 根据业务删除无用数据 //400000000(4亿)
5. 根据分区分批次插入insert into,防止超时 //20000000(2千万) 20000000(2千万) 20000000(2千万) …
锁表以及解除方式
排查死锁的一般步骤是这样的:
(1)查看死锁日志 show engine innodb status;
(2)找出死锁 sql
(3)分析 sql 加锁情况
(4)模拟死锁案发
(5)分析死锁日志
(6)分析死锁结果
当然,这只是一个简单的流程说明,实际上生产中的死锁千奇百怪,排查和解决起来没那么简单。
解除锁表的步骤如下:
1)锁表查询代码:
select * from v$locked_object;
2)查看哪个表被锁
SELECT
b.OWNER,
b.object_name,
a.session_id,
a.locked_mode
FROM
v$locked_object a,
dba_objects b
WHERE
b.object_id = a.object_id;
3)查看是哪个session引起的
SELECT
b.username,
b.sid,
b.serial#,
logon_time
FROM
v$locked_object a,
v$ SESSION b
WHERE
a.session_id = b.sid
ORDER BY
b.logon_time;
4)查看是哪个sql引起的
SELECT
b.username,
b.sid,
b.serial#,
c.*
FROM
v$locked_object a,
v$ SESSION b,
v$ SQL c
WHERE
a.session_id = b.sidand b.SQL_ID = c.sql_id
ORDER BY
b.logon_time;
5)杀掉对应进程
执行命令:alter system kill session ‘1025,41’;
其中1025为sid,41为serial#.
mysql中间件
MySQL Router
-
定义
MySQL官方提供的一个轻量级MySQL中间件,用于实现MySQL读写分离,对MySQL请求进行负载均衡。
-
前提
后端实现了MySQL的主从复制
快速导航
索引
-
普通索引(创建)
create table t1 ( years year not null, index (years) )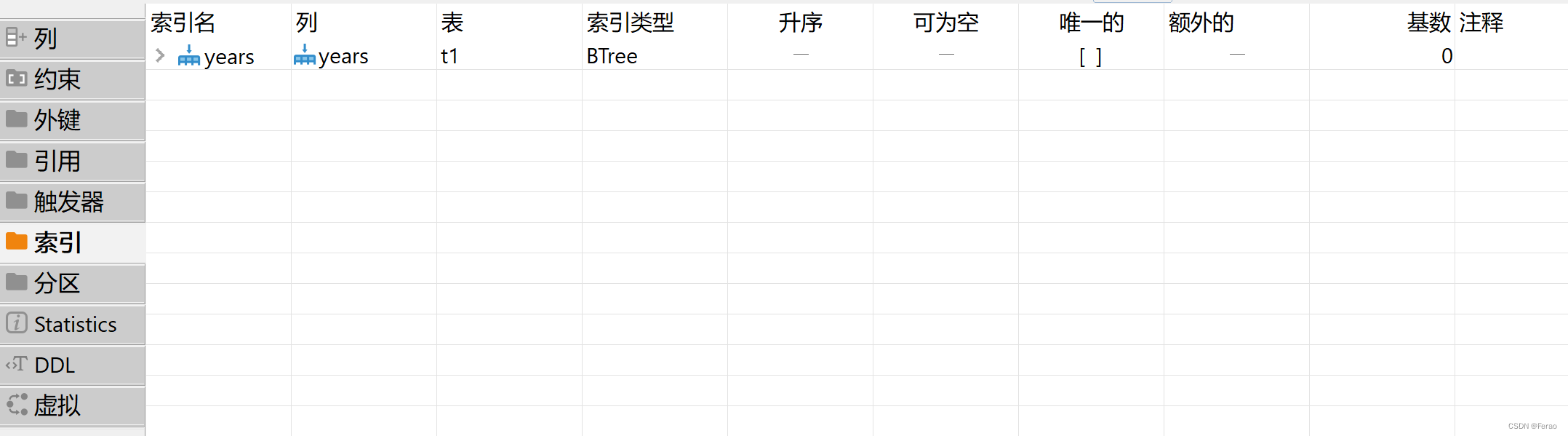
-
唯一索引(创建)
create table t3 ( id int not null, unique index uniqueID(id) )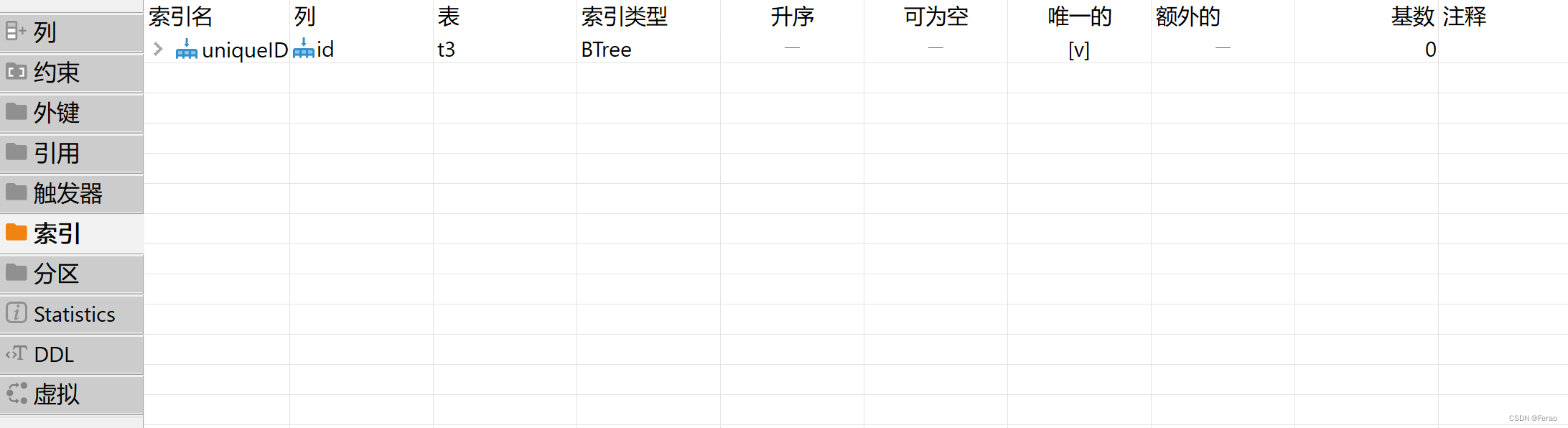
-
唯一索引(删除)
alter table t3 drop index uniqueID; -
唯一索引(添加)
alter table t3 add unique key uniqueID(id);

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 26
26 1
1- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)