
算法导论学习笔记(一)
1.算法在计算中的作用一个算法学习项目:https://github.com/algorithm-visualizer/algorithm-visualizer1,什么是算法?算法是一系列的计算步骤,用来将输入数据转换成输出结果。2,为什么要对算法进行研究?对算法的研究,对软件来说,有助于优化程序执行效率,满足用户需求,提升用户体验度。3,相对于计算机中使用的其他技术来说,算法的作用...
1.算法在计算中的作用
一个算法学习项目:
https://github.com/algorithm-visualizer/algorithm-visualizer
1,什么是算法?
算法是一系列的计算步骤,用来将输入数据转换成输出结果。
2,为什么要对算法进行研究?
对算法的研究,对软件来说,有助于优化程序执行效率,满足用户需求,提升用户体验度。
3,相对于计算机中使用的其他技术来说,算法的作用是什么?
在时间空间的有限上,提升解决问题的效率。其他的一些计算机技术(硬件设计、网络路由)
是否拥有扎实的算法知识和技术基础,是区分真正熟练的程序员与新手的一项重要特征。利用当代的计算技术,无需了解很多算法的东西,也可以完成一些任务。但是,有了良好的算法基础和背景的话,可以做的事就要多得多了。
2.算法入门
2.1 插入排序
伪代码:
A = [1...n]
INSERTION-SORT(A)
for j <-- 2 to length[A]
do key <-- A[j]
// 把A[j]插入到已经排好序的A[1...j-1]的序列中。
i <-- j-1
while i > 0 and A[i] > key
do A[i+1] <-- A[i]
i <-- i-1
A[i+1] <-- key
用java语言实现:
/**
* 插入排序算法
* @param a
* @return
*/
public static int[] insertionSort(int[] a){
int i;
for(i=1;i<a.length;i++){
int tmp = a[i];
int j = i-1 ;
for(;j>=0 && a[j] > tmp;){
a[j+1] = a[j];
--j;
}
a[j+1] = tmp;
}
return a;
}
循环不变式主要用来帮助我们理解算法的正确性。对于循环不变式,必须证明它的三个性质:
- 初始化:它在循环的第一轮迭代开始之前,应该是正确的。
- 保持:如果在循环的某一次迭代开始之前它是正确的,那么,在下一次迭代开始之前,它也应该保持正确。
- 终止:当循环结束时,不变式给了我们一个有用的性质,它有助于表明算法是正确的。
循环不变式类似于数学归纳法,其不同之处在于循环不变式的步骤是有限的。
下面用循环不变式,证明插入算法的正确性:
- 初始化:在第一次循环开始前,j = 2,对序列A[1…j-1]仅有个一个值A[1],显然是有序的。
- 保持:在假设内层循环是有循环不变式成立的,内层循环将A[j]插入到已经排好序的A[1…j-1]的序列中,这样,对于后续步骤j+1,j+2可以满足A[1…j+1]、A[1…j+2]都是有序的。
- 终止:在变量j = n+1时,循环可以终止,此时,A[1…j-1] = A[1…n]是有序的,即A[1…n]整个数组有序。说明算法是正确的。
练习
2.1-1 以图2-2为模型,说明INSERTION-SORT在数组A=<31,41,59,26,41,58>上的执行过程。

2.1-2 重写过程INSERTION-SORT,使之按非升序排序。
INSERTION-SORT(A)
for j <-- 2 to length[A]
key <-- A[j]
i <-- j-1
while i>0 and A[i] < key
do A[i+1] = A[i]
i <-- i-1
A[i+1] = key
2.1-3 
SEARCH-EQUAL(A,Vo)
for i <-- 1 to length[A]
if A[i] == Vo
return i
return NIL
循环不变式证明:
- 初始化:在循环开始前,i = 1,对于循环体,A[i] = Vo时则能返回i
- 保持:对于任意循环开始前,满足A[i] = Vo将返回i
- 终止:i = n+1时,循环结束,返回NIL。算法正确。
2.1-4
BINARY-ADD(A,B,C)
for i <-- 1 to n
do
key <-- A[i]+B[i]+C[i]
C[i] <-- key mod 2
if key > 1
C[i+1] <-- 1
2.2 算法分析
算法分析即指对一个算法所需的资源进行预测。资源是指我们希望测度的计算时间,偶尔也会包括内存、计算机硬件、带宽。
输入规模:与具体问题有关。如对(排序、计算离散傅里叶变换),一般为输入元素个数,对于输入图,则一般由图顶点数、边数两个数作为度量标准。
运行时间:指在特定操作输入时,所执行的基本操作数(步数)。
练习

2.2-1
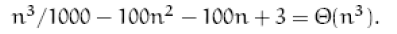
2.2-2
伪代码:
SELECTION-SORT(A)
Input: A = <a1,a2,...an>
output:Sorted A
for i <-- 1 to n-1 do
j <-- Find Min (A,i,n)
A[j]<-->A[i]
end for
java语言实现
/**
* 选择排序
* @param a
* @return
*/
public static int[] selectionSort(int[] a){
int len = a.length;
for(int i=0;i<len-1;i++){
int minIndex = i;
for(int j=i;j<len;j++){
if(a[j] < a[minIndex]){
minIndex = j;
}
}
int tmp = a[i];
a[i] = a[minIndex];
a[minIndex] = tmp;
}
return a;
}
循环不变式:
- 初始化:第一次循环开始前,i =1,内存循环找到A[1…n]即整个数组中的最小值下标,将A[1]与找到的最小值交换,则A[1]为数组的最小值。
- 保持:在下一次循环开始前,有A[1…i-1]为数组最小的i-1个值的排序,循环时,内层循环找到A[i…n]中的最小值,与A[i]交换,则有A[1…i]为数组最小i个值的排序。
- 终止:在i = n时,循环退出,此时有A[1…n-1]为最小值排序,A[n] 一定大于A[n-1],则整个数组已经排序。算法正确。
在将A[1…n-1]个最小值排序后,A[n]>A[n-1]则,整个数组是有序的。
最好与最坏情况一样,时间复杂度都为:
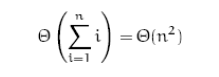
2.2-3
在平均情况下,需要检查输入序列中一半元素(n/2)个,在最坏情况需要检查n个元素。线性查找的时间复杂度为:
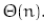
2.2-4
修改算法的输入为最好情况,则算法有较好的最佳情况运行时间。
算法设计
分治策略:将原问题划分成n个规模较小而结构与原问题相似的子问题;递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治模式在每一层递归都有三个步骤:
1. 分解:将原问题分解成一系列的子问题;
2. 解决:递归地解各个子问题。若子问题足够小,则直接求解。
3. 合并:将子问题的结果合并成原问题的解。
合并过程伪代码:
MERGE(A,p,q,r)
n1 <-- q - p +1
n2 <-- r - q
create array L[1,n1 +1] and R[1,n2+1]
for i 1 to n1
do L[i] <-- A[p + i -1]
for j 1 to n2
do R[j] <-- A[q + j]
L[n1 +1] <-- oo
R[n2+1] <-- oo
i <-- 1
j <-- 1
for k <-- p to r
do if L[i] <= R[j]
then A[k] <-- L[i]
i <-- i+1
else A[k] <-- R[j]
j <-- j+1
合并过程的循环不变式:
1. 初始化:循环开始时,k =p , i = 1,j =1,A[p…k-1]中元素为0个,L[1]和R[1]都是为其未复制的数组中最小值。
2. 保持:在循环k之前,A[p…k-1]为,L与R中最小元素的排序。循环时,会将L[i] 与 R[j]中较小的元素复制到A[k]中,同时更新L或R中下标值,使得L,R中都是剩余的未被复制的有序元素。
3. 终止:在k = r+1时,循环终止,此时,A[p…r]是有序的,即整个数组有序,算法正确。
合并排序的伪代码:
MERGE-SORT(A,p,r)
if p < r
then q <-- (p+r)/2
MERGE-SORT(A,p,q)
MERGE-SORT(A,q+1,r)
MERGE(A,p,q,r)
java语言实现
/**
* 合并排序
* @param a
* @param p
* @param r
* @return
*/
public static int[] mergeSort(int[] a,int p,int r){
if(p < r){
int q = (p+r)/2;
mergeSort(a,p,q);
mergeSort(a,q+1,r);
merge(a,p,q,r);
}
return a;
}
/**
* 合并
* @param a
* @param p
* @param q
* @param r
*/
public static void merge(int[] a,int p,int q,int r){
int n1 = q-p+1;
int n2 = r - q;
int[] f = new int[n1+1];
int[] s = new int[n2+1];
for(int i=0;i<n1;i++){
f[i] = a[p+i];
}
for(int j=0;j<n2;j++){
s[j] = a[q+j+1];
}
f[n1] = -1;
s[n2] = -2;
int i = 0;
int j = 0;
for(int k = p;k<=r;k++){
if(f[i] == -1){
a[k] = s[j];
j = j + 1;
}else if(s[j] == -2){
a[k] = f[i];
i = i + 1;
}else if(f[i] <= s[j]){
a[k] = f[i];
i = i + 1;
}else {
a[k] = s[j];
j = j + 1;
}
}
}
练习

2.3-1

2.3-2
java 语言实现:
/**
* 合并(无哨兵)
* @param a
* @param p
* @param q
* @param r
*/
public static void merge2(int[] a,int p,int q,int r){
int n1 = q-p+1;
int n2 = r - q;
int[] f = new int[n1];
int[] s = new int[n2];
for(int i=0;i<n1;i++){
f[i] = a[p+i];
}
for(int j=0;j<n2;j++){
s[j] = a[q+j+1];
}
int i = 0;
int j = 0;
for(int k = p;k<=r;k++){
if(i == n1){
a[k] = s[j];
j = j + 1;
}else if(j == n2){
a[k] = f[i];
i = i + 1;
}else if(f[i] <= s[j]){
a[k] = f[i];
i = i + 1;
}else {
a[k] = s[j];
j = j + 1;
}
}
}
2.3-3

2.3-4
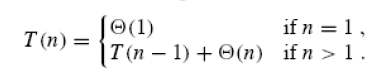
2.3-5
伪代码:
BINARY-SEARCH(A,p,r,Vo)
if(p >= r) and Vo != A[p]
then return NIL
end if
q <-- (p + r)/2
if(Vo = A[q])
then return q
else if(Vo > A[q])
return BINARY-SEARCH(A,q,r,Vo)
else
return BINARY-SEARCH(A,p,q,Vo)
java语言实现二分查找
/**
* 二分查找(递归)
* @param a 要查找的已经排序的升序序列
* @param p 查找起始位置
* @param r 查找结束位置
* @param v 要查找匹配的值
* @return
*/
public static int binarySearch(int[] a,int p,int r,int v){
if(p >= r && a[p] != v){
// -1表示未匹配到
return -1;
}else {
int q = (p+r) / 2;
if(a[q] == v){
return q;
}else if(a[q] > v){
return binarySearch(a,p,q,v);
}else {
return binarySearch(a,q,r,v);
}
}
}
最坏情况为查找不到v,此时需要递归二分n,查找次数为n的二分树深度,则时间复杂度为:
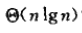
2.3-6
二分法-插入排序伪代码:
BINARY-INSERTION-SORT(A)
for j <-- 2 to length[A]
do key <-- A[j]
△ 将A[j]插入的已经排序的A[1...j-1]中
high <-- j-1
low <-- 1
while high > low
mid = (high + low )/2
if key == A[mid]
break
else if key < A[mid]
high <-- mid -1
else if key > A[mid]
low <-- mid +1
for i <-- mid to j-1
A[i+1] <-- A[i]
A[mid] <-- A[j]
用java语言实现
/**
* 二分-插入排序
* @param a
* @return
*/
public static int[] binaryInsertionSort(int[] a){
int len = a.length;
for(int i = 1;i<len;i++){
int tmp = a[i];
int high = i-1;
int low = 0;
int mid = (high + low) / 2;
while (low < high){
if(tmp == a[mid]){
break;
}else if(tmp < a[mid]){
high = mid - 1;
}else if(tmp > a[mid]) {
low = mid + 1;
}
mid = (high + low) / 2;
}
for(int j = (i-1); j>=mid;j--){
a[j+1] = a[j];
}
a[mid] = tmp;
}
return a;
}
在最坏情况下,二分查找的时间复杂度为 nlgn,但插入时数组移动时间复杂度任为 n^2。故总时间复杂度不能为: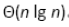
(若排序中采用链表的数据结构,则可改善。)
2.3-7
伪代码:


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)