




- @zyx_bx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
其中**-Xms表示最小内存,-Xmx表示最大内存,-Xmx1024m**表示最大内存为1024M,这里可以根据自己的机器进行合适的配置。但使用的mysql超过1G了,所以会报这个错。找到Dbeaver的安装目录,目录下有。
在写论文的过程中,我们经常遇到在写算法框架时,由于算法太长,常常占据一个页面,这样导致后续排版时候不美观同时与前文没有很好的衔接的情况,为此搜索了一下解决方法,比较有效的方法如下:\documentclass{article}\usepackage{algorithm,algpseudocode,float}\usepackage{lipsum}\makeatletter\newenvironme
初始状态如下第一步:set names gbk;发现乱码的问题解决了 但还是没有对齐第二步:charset gbk;此时发现表格对齐需要注意的是,刚刚的字符集不对应有两种可能第一种是在安装mysql(默认utf-8)的过程中修改了第二种是创建表格的时候...
开始节点:用户上传文件,支持txt、doc、docx、pdf、ppt、md等常见文档格式。文档提取器:文档提取器节点的作用是将用户上传的文档解析并读取其中的信息,然后将这些信息转化为文本格式传递给LLM大模型进行处理。LLM处理:LLM大模型根据输入的文本内容提取指定的信息。结束节点:输出提取结果。

在HTTP节点前添加代码执行节点,将参数强制编码为UTF-8格式。在Java后端代码中进行解码操作,以确保参数的正确性。Dify智能体将含有中文的JSON参数传递到Java后端时出现乱码。

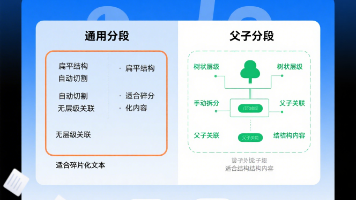
摘要:Dify知识库提供通用分段和父子分段两种策略,前者适合扁平化文本(如评论/新闻),后者适合结构化文档(如手册/论文)。通用分段按长度切割(500 tokens/段),父子分段则建立层级关系(父块500-10k tokens,子块200 tokens)。关键差异在于上下文保留能力,结构化内容优先选择父子分段。选型需考虑文本特征、检索需求和上下文完整性,技术文档推荐父子分段,碎片化内容适用通用分
本文介绍了参数提取、变量赋值与聚合三大核心功能。参数提取器将自然语言转化为结构化数据,为API请求提供标准输入;变量赋值分为会话变量(跨对话共享数据)和循环变量(1.2.0版本简化迭代管理);变量聚合整合多分支输出,提供统一接口。三者共同构建了高效的工作流处理体系,覆盖从输入解析、数据处理到结果输出的全流程,显著提升了系统对复杂业务场景的适应能力。

摘要:变量聚合节点通过整合多路分支的变量,简化下游节点配置,支持字符串、数字等多种数据类型(需同类型聚合)。适用于条件分支或分类场景,可避免重复定义。模板转换节点基于Jinja2实现文本拼接、结构化输出(如Markdown/JSON)及HTML渲染,提升工作流灵活性。二者结合可优化数据流管理,减少冗余节点。参考Dify官方文档获取详细用法。

M/M/1 排队论模型1.M/M/1 模型简单介绍到达时间是泊松过程(Poisson process);服务时间是指数分布(exponentially distributed);只有一部服务器(server)队列长度无限制可加入队列的人数为无限这种模型是一种出生-死亡过程,此随机过程中的每一个状态代表模型中人数的数目。因为模型的队列长度无限且参与人数亦无限,故此状态数目亦为无限。例如状态0表示模型
代码如下:%导言区\documentclass[10pt]{article} %确定normalsize大小,为可选参数,在中括号内,此为10磅,只有10,11,12磅三个选项。\usepackage{ctex}%自定义字体\newcommand{\myfont}{\textit{\textbf{\textsf{Fancy Text}}}}%文稿区\begin{document}%字体族设置(罗马