




- @zhanyuanlin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文就对Linux操作系统诊断的相关知识进行系统梳理,CPU的原理(Interuption, IO Wait, User time, System time...), Memory的组成和工作原理(Free/Available, Slab, Page Cache/Buffer, Swap, mmap, Page Table),Disk(mmap), 同时,结合我们遇到的欣赏系统问题,进行极其详尽的
我们通过DROP TABLE .. ON CLUSTER,意外导致ClickHouse集群的Kafka表hang住,并且Kafka表的表级别锁无法释放,所有其他对Kafka表进行的任何操作都无法进行。本文对这个事故进行了描述,同时对我们的整个诊断、分析过程进行了记录,并且提出了解决方案。同时,我们还对ClickHouse + librdkafka的底层代码和原理进行解析。
这篇文章主要介绍了我们一次Spark Job失败的诊断、分析到最后解决问题的过程。虽然出问题的是我们的Spark Job而不是一个通用的基础设施,但是其在分布式环境下收集纷繁复杂的日志、在互为因果的异常信息中梳理线性因果关系,查找日志、分析堆栈、破除矛盾点、总结原因、解决问题的过程是我们解决所有其他问题的基本方法论。
本文总结一次 ClickHouse 在执行加列的DDL操作后出现的后台合并(merge)持续失败与阻塞问题的排查与修复思路。本文详细记录了我们从发现线上问题,到先行解决线上问题,以及在问题解决以后再次收集现场、猜测和分析原因、添加日志并重现问题、最终定位到根本原因的整个过程。这此事故是由于我们为表添加列、ClickHouse Part中部分列缺失、Merge阶段为缺失列进行默认值补齐、复合列处理过
前一段时间数据挖掘组的同学向我返回说自己的一段pyspark代码执行非常缓慢,而代码本身非常简单,就是查询hive 一个视图中的数据,而且通过limit 10限制了数据量。不说别的,先贴我的代码吧:from pyspark.sql import HiveContextfrom pyspark.sql.functions import *import jsonhc = HiveContext
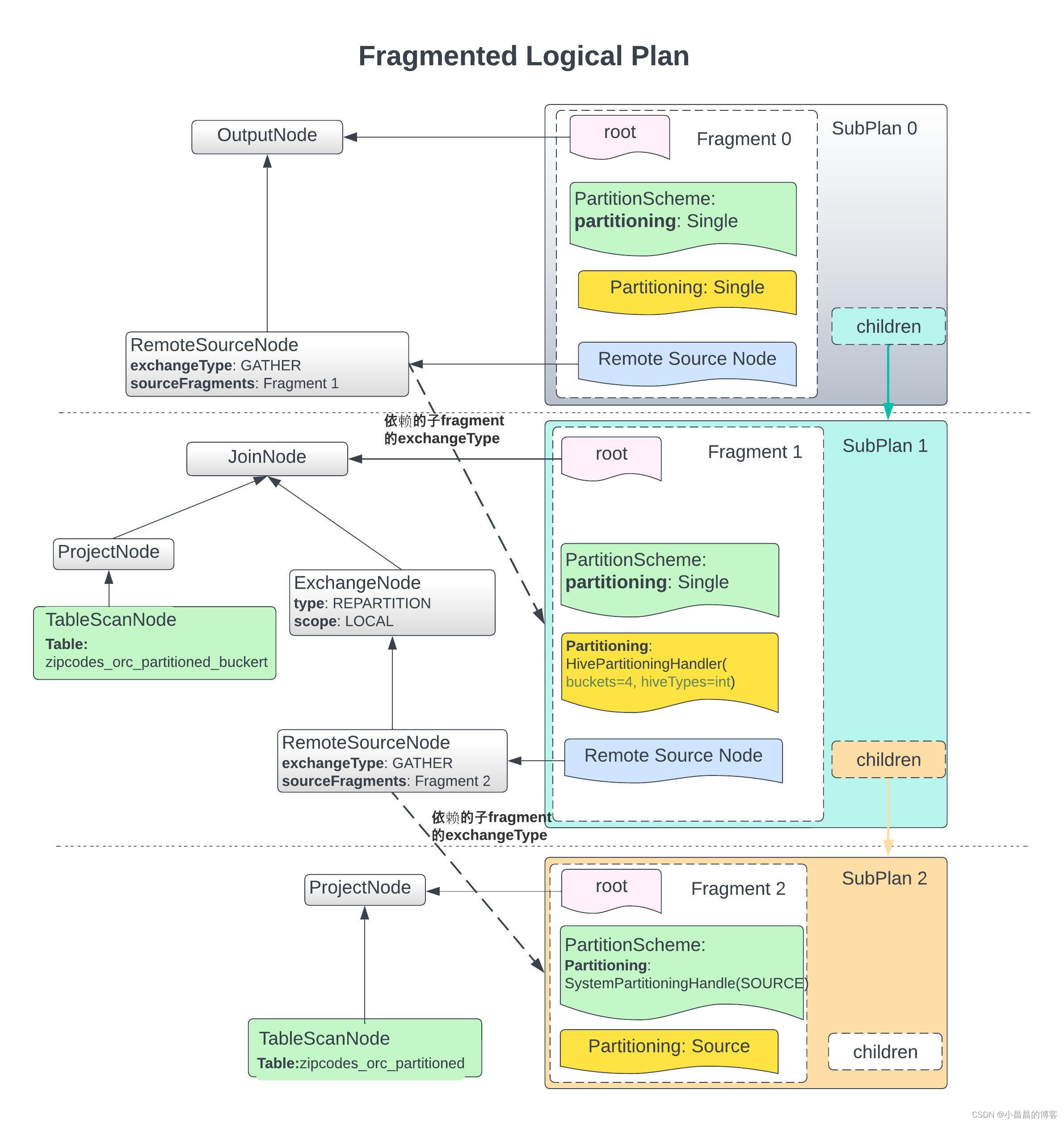
讲解物理执行计划的生成,以及基于物理执行计划的task 和 split 的调度过程。
目录序言1. Kafka MirrorMaker基本特性2. 新旧Consumer API的使用问题3. 负载不均衡原因诊断以及问题解决4. 本身网络带宽限制问题5. 适当配置单次poll的消息总量和单次poll()的消息大小6. 恶劣网络环境下增加超时时间配置序言Kakfa MirrorMaker是Kafka 官方提供的跨数据中心的流数据同步方案。其实现原...