
写文章




- @yaoyaolin______g
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
既有奖励又有约束:在腿式机器人运动中的应用
这使得问题总是可行的,因为零-对成本优势函数Aπ Ck进行平均归一化,通过用dk对扩大范围进行参数化,带来与规模归一化类似的效果。2)多头成本值函数:对于每个约束,参数化成本值函数(在我们的情况下,神经网络)需要使用GAE [50]计算成本优势函数。在这种设置中,所有成本值函数共享相同的神经网络主干,并且当引入更多约束时,仅输出层维度增加。首先,自适应约束阈值方法被用来适当地设置基于当前策略的性能

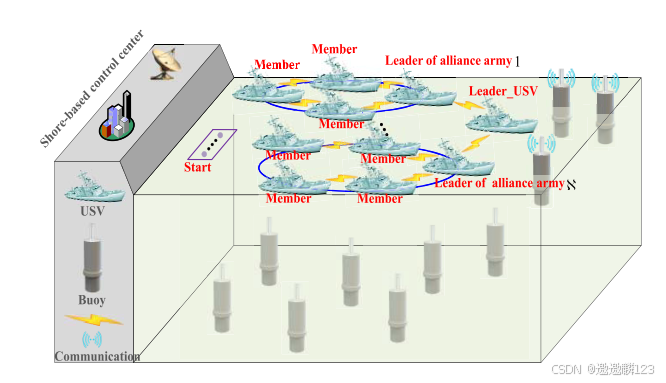
论文阅读——基于改进深度强化学习的多无人艇任务规划方法(IF=8.2)
上述方法将复杂问题分解为若干子问题,基于子问题的目标和约束设计奖励函数,然后相应地分解Q函数,不仅允许每个sub-Q函数基于其对应的子问题的奖励函数进行优化,以更准确地评估策略的性能,而且还有助于提高Critic网络的训练效率,从而加速收敛过程。其中,Own_Critic iσ网络用于逼近Qπθiσ函数,Local_Critic σ网络用于逼近Qπθσ函数。其中,<oσ,t,aσ,t,oσ,t+1
论文阅读——MO-MIX:基于深度强化学习的多目标多智能体协作决策(IF=20.8)
为了提高最终解的一致性,对一个包含迄今为止找到的所有非支配解非支配集,在训练阶段,每一集采样一个ω,作为网络的输入。如果某一个子空间中的解比较稀疏,则其中偏好的采样概率会增加,这允许对性能较差的子空间中的权重进行更多次的采样和训练。MOMN将CAN的输出作为输入,首先基于目标对n个智能体的Q向量进行重组,组合对应于某个目标的所有Q值合并馈送到某个MOMN并行轨道中,然后将多个轨迹输出连接为整个网络

到底了