- @wish_to_top
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关于机器学习特征顺序是否影响分类效能写作目的尝试最后结果写作目的环境:jupyter notebook,python 3.6.3 ,scikit-learn0.22.2.post1大致经过是这样的,先通过生信分析找到差异基因,然后再使用python的sk-learn模型训练随机森林时,发现即便设置了随机种子,但每次对训练测试集的预测性能都不一样,而且最为诡异的是当我重启内核再运行时,这个结果才会改
写在前面说来惭愧,感觉读到研究生,说来说去张口闭口也就是TCGA、GEO、ARRAYEXPRESS、GTEX数据库,感觉还不如一些临床医生自学生物信息学的,平常都没去探索一些新的数据库,这边做个记录.黑色部分代表我查到的简介,而红色部分则表示我的个人看法GEO数据库GEO数据库全称GENE EXPRESSION OMNIBUS,是由美国国立生物技术信息中心NCBI创建并维护的基因表达数据库。它收录
开此贴做GDSC的数据分析记录。

开此贴做GDSC的数据分析记录。
香农多样性写在前面首先是香农多样性的计算根据count根据频率示例写在前面本人新手哈,写的不好或若有些许错误,请自行判断或于评论区留言写这篇博文的原因在于首先我通过qiime搞出的香农多样性的数值,看了一下多是3点多4点多的样子,看了一些中文教程,让我有了香农多样性就是应该在0-1的错觉,后面去检索了一下首先是香农多样性的计算参考链接如下:https://www.itl.nist.gov/div8
关于机器学习特征顺序是否影响分类效能写作目的尝试最后结果写作目的环境:jupyter notebook,python 3.6.3 ,scikit-learn0.22.2.post1大致经过是这样的,先通过生信分析找到差异基因,然后再使用python的sk-learn模型训练随机森林时,发现即便设置了随机种子,但每次对训练测试集的预测性能都不一样,而且最为诡异的是当我重启内核再运行时,这个结果才会改
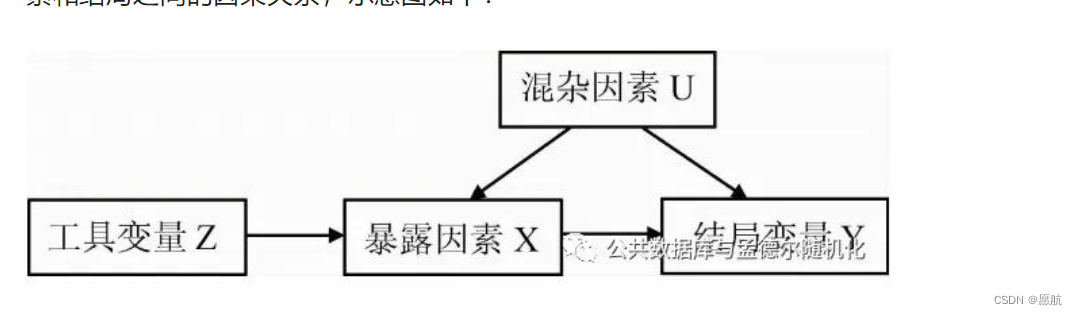
看了一些孟德尔随机化内容,大概整理一下步骤参考博文:https://mp.weixin.qq.com/s?