
写文章




- @weixin_66679058
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Macaron 加速 RL 应用探索的三种场景(下篇)
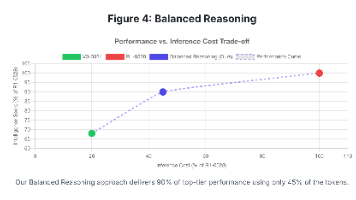
Macaron团队基于强化学习平台,探索了三个关键应用场景:Balanced Reasoning强调在保证正确性的前提下缩短推理过程,提高用户体验与资源效率;Agentic Memory利用多轮对话机制与记忆向量,实现跨长对话的精确记忆,提升长期任务的连贯性;Human-Agent Interaction则通过情感反馈与动态奖励机制,使模型具备更人性化的沟通方式和高效工具调用能力。这些应用体现了大
Macaron 加速 RL 应用探索的三种场景(下篇)
Macaron团队基于强化学习平台,探索了三个关键应用场景:Balanced Reasoning强调在保证正确性的前提下缩短推理过程,提高用户体验与资源效率;Agentic Memory利用多轮对话机制与记忆向量,实现跨长对话的精确记忆,提升长期任务的连贯性;Human-Agent Interaction则通过情感反馈与动态奖励机制,使模型具备更人性化的沟通方式和高效工具调用能力。这些应用体现了大
最近大火的 Macaron 背后的强化学习技术解析(上篇)
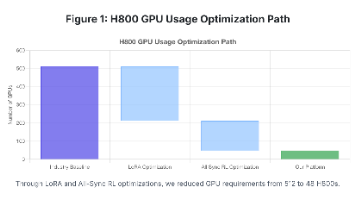
摘要:Macaron团队通过All-Sync RL架构实现大模型强化学习的高效训练,该架构同步进行推理和训练以提高GPU利用率,相比传统方法将训练时间从9小时缩短至1.5小时。同时采用LoRA低秩微调技术减少通信开销,并结合DAPO算法增强训练稳定性。这些创新使671B参数模型的RL训练GPU需求从512张降至48张。系统还引入截断重要性采样处理训练与推理的分布差异,通过Coati训练框架和SGL
到底了