




- @weixin_60223645
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
提供人工智能及强化学习基础网络设计及知识传递服务
6.10凌晨1点,Claude发布了Fable 5,号称是Claude向大众发布过的能力最强的模型。Fable 5属于Mythos系列,只是为了大众使用,在安全上做了一些限制。

**从 2024 年底到 2026 年春天,不到一年半的时间,科研,尤其是对于独立研究工作者,这件事已经跟过去完全不是一回事了。****如果要在整个科研史上画一条分界线,2024 年底可能算一条。那之前,AI 是"辅助":是 Copilot 帮着补全一行代码,是 ChatGPT 帮着润色一段英文。那之后,AI 开始变成"主角":它写代码,复现论文,跑实验,一次性读完整个代码仓库,然后指出里面某个算

6.10凌晨1点,Claude发布了Fable 5,号称是Claude向大众发布过的能力最强的模型。Fable 5属于Mythos系列,只是为了大众使用,在安全上做了一些限制。
6.10凌晨1点,Claude发布了Fable 5,号称是Claude向大众发布过的能力最强的模型。Fable 5属于Mythos系列,只是为了大众使用,在安全上做了一些限制。
如果你第一次听到“训练大模型”,脑海里可能会自动浮现一排显卡、嗡嗡作响的机房、以及一张看起来不太友好的云账单。好消息是:我们今天不训练一个真正能上生产的 ChatGPT,也不挑战算力预算的物理极限。我们要做的是把大模型训练流程缩小成一个可以亲手跑通的“训练沙盘”。
如果你第一次听到“训练大模型”,脑海里可能会自动浮现一排显卡、嗡嗡作响的机房、以及一张看起来不太友好的云账单。好消息是:我们今天不训练一个真正能上生产的 ChatGPT,也不挑战算力预算的物理极限。我们要做的是把大模型训练流程缩小成一个可以亲手跑通的“训练沙盘”。
如果你第一次听到“训练大模型”,脑海里可能会自动浮现一排显卡、嗡嗡作响的机房、以及一张看起来不太友好的云账单。好消息是:我们今天不训练一个真正能上生产的 ChatGPT,也不挑战算力预算的物理极限。我们要做的是把大模型训练流程缩小成一个可以亲手跑通的“训练沙盘”。
2025年6月4日,是我在CSDN写下第一篇技术博客的第1024天。1024,这个数字对于程序员来说意义非凡,它不仅是内存单位的基础,更是我们这群“码农”的节日符号。而对我来说,它更像是一段旅程的里程碑:从一个曾想过本科毕业直接就业的本科生,到现在人工智能方向博士生,我在这条创作与探索的路上,已经走了整整1024天。这1024天里,我写过Matlab命令整理、Python算法实现、深度学习模型搭建

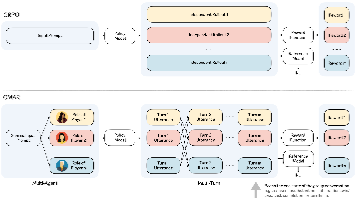
摘要: 两项研究突破多智能体系统瓶颈:① Q-CMAPO框架创新融合量子计算与经典强化学习,通过量子电路编码策略(QAOA算法)提升高维动作空间探索效率,经典评价器保障执行稳定性,在无人机协同等场景实现高效收敛;② 自博弈对话模型揭示团队协作"平庸化"机制,单一模型通过自博弈训练同时扮演多角色,低成本涌现社交智能(如同理心),为多智能体交互提供新范式。两项工作分别从量子计算底层
**从 2024 年底到 2026 年春天,不到一年半的时间,科研,尤其是对于独立研究工作者,这件事已经跟过去完全不是一回事了。****如果要在整个科研史上画一条分界线,2024 年底可能算一条。那之前,AI 是"辅助":是 Copilot 帮着补全一行代码,是 ChatGPT 帮着润色一段英文。那之后,AI 开始变成"主角":它写代码,复现论文,跑实验,一次性读完整个代码仓库,然后指出里面某个算