




- @weixin_50909869
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
同时引出了随着深度学习的发展,研究者尝试用各种线索来进行抑郁症的诊断,抑郁症检测的方法,提取患者的视觉语音线索,从音频、视觉、文本到多模态。Research context:文章是一篇关于基于音视觉线索来检测抑郁症的综述,文章分别介绍了抑郁症目前的现状、数据集的研究发展、研究方法历程:1.基于音频的抑郁症评估 2.基于视觉的抑郁症评估 3.基于音视频的抑郁症评估(多模态)、以及总结问题、提出展望。
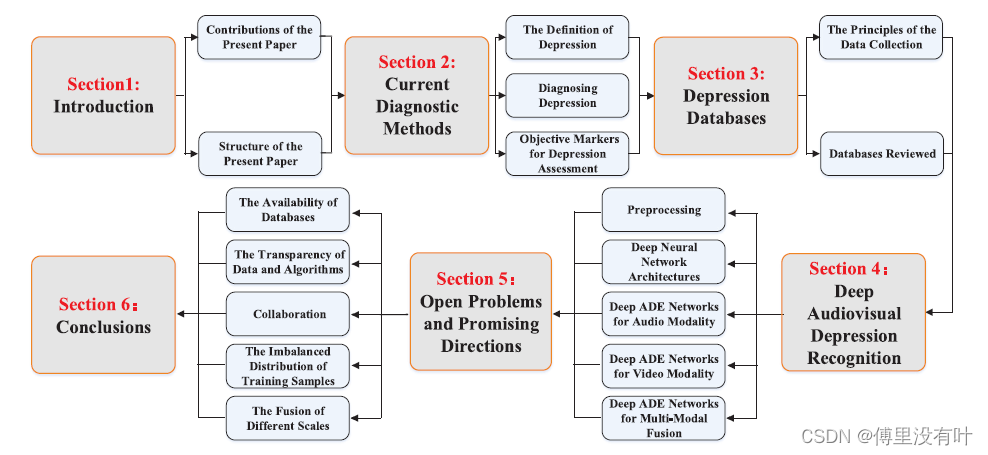
(1)目前抑郁症的现状(WHO),传统研究方法的缺陷,总结之前研究的方法,以及不足,提出自己的研究,研究意义。(2)介绍研究方法:建立数据集(包括社交网络文本数据、步长数据)、模型(Bert、3D卷积、LSTM)、训练。使用多元数据结合集成模型训练来进行抑郁倾向的检测,主要内容:数据集的获取,模型的建立,训练和测试效果。3.数据源较少,社交文本数据比较难以收集,仅仅依靠步态数据进行预测准确度不够,

(1)目前抑郁症的现状(WHO),传统研究方法的缺陷,总结之前研究的方法,以及不足,提出自己的研究,研究意义。(2)介绍研究方法:建立数据集(包括社交网络文本数据、步长数据)、模型(Bert、3D卷积、LSTM)、训练。使用多元数据结合集成模型训练来进行抑郁倾向的检测,主要内容:数据集的获取,模型的建立,训练和测试效果。3.数据源较少,社交文本数据比较难以收集,仅仅依靠步态数据进行预测准确度不够,
(1)目前抑郁症的现状(WHO),传统研究方法的缺陷,总结之前研究的方法,以及不足,提出自己的研究,研究意义。(2)介绍研究方法:建立数据集(包括社交网络文本数据、步长数据)、模型(Bert、3D卷积、LSTM)、训练。使用多元数据结合集成模型训练来进行抑郁倾向的检测,主要内容:数据集的获取,模型的建立,训练和测试效果。3.数据源较少,社交文本数据比较难以收集,仅仅依靠步态数据进行预测准确度不够,
作者验证了三者的各项指标,accuracy、F1 score、loss and so on,发现audio CNN在抑郁症检测方面上能获得良好的效果,准确率达到98%,损失为0.1%,而text CNN的准确度为92%,损失为0.2%,混合LSTM模型的准确率为0.80%,损失为0.4。提出了一个基于语音和文本的抑郁症倾向检测的混合模型(混合Bi-LSTM和混合LSTM),文章对比研究了语音数据集