- @weixin_45515807
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
5.如需使用nginx反向代理访问此服务,可参考https://github.com/LeetJoe/lawyer-llama/blob/main/demo/nginx_proxy.md (Credit to。4.server.py代码这样的,模型路径手动更改。1.建议使用Python 3.8及以上版本。下载 **Lawyer LLaMA 2 (启动法条检索服务,默认挂在9098端口。(需要
5.如需使用nginx反向代理访问此服务,可参考https://github.com/LeetJoe/lawyer-llama/blob/main/demo/nginx_proxy.md (Credit to。4.server.py代码这样的,模型路径手动更改。1.建议使用Python 3.8及以上版本。下载 **Lawyer LLaMA 2 (启动法条检索服务,默认挂在9098端口。(需要
4.去魔搭社区下载模型https://modelscope.cn/studios/ZhipuAI/chatglm3-6b-demo/summary。2.然后根据https://blog.csdn.net/weixin_45597212/article/details/135553151安装。1.cuda官网https://developer.nvidia.com/cuda-toolkit-arc

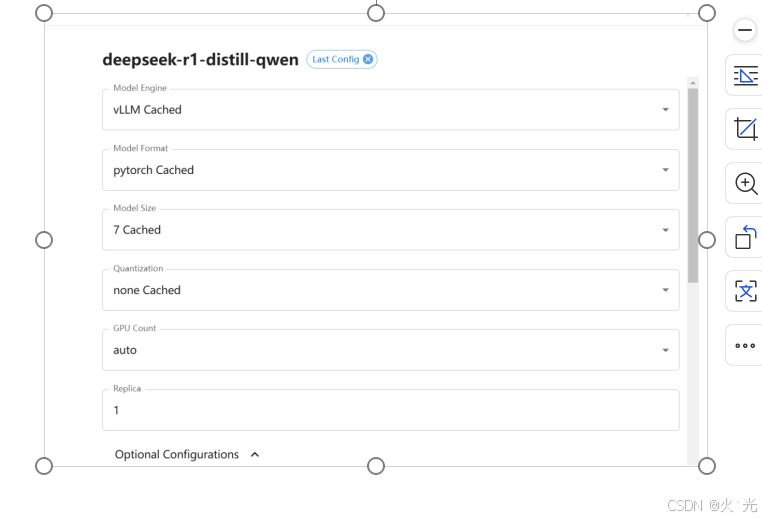
3.这里如果你一张显卡就CUDA_VISIBLE_DEVICES=0 xinference-local --host 0.0.0.0 --port 9997这样启动,多张显卡还跟以前一样xinference-local --host 0.0.0.0 --port 9997启动。AWG(Adaptive Weight Granularity):一种量化方法,通过自适应地调整权重的量化精度,以优化模型

5.如需使用nginx反向代理访问此服务,可参考https://github.com/LeetJoe/lawyer-llama/blob/main/demo/nginx_proxy.md (Credit to。4.server.py代码这样的,模型路径手动更改。1.建议使用Python 3.8及以上版本。下载 **Lawyer LLaMA 2 (启动法条检索服务,默认挂在9098端口。(需要
4.去魔搭社区下载模型https://modelscope.cn/studios/ZhipuAI/chatglm3-6b-demo/summary。2.然后根据https://blog.csdn.net/weixin_45597212/article/details/135553151安装。1.cuda官网https://developer.nvidia.com/cuda-toolkit-arc
人均瑞数的年代,加油吧,5.5都这么难了,后面的路太难了
然后最后我们xfc需要这个版本才有r1,需要大家下载一下* Pip:pip install ‘xinference==1.2.1’最后如果没有搞搞清楚v3,r1状况的,先看一下论文文档,扔碎片一个AI里让它们翻译,不要跟着短视频跑。然后你用14B的可以init8,token设置个11000,具体根据自己显卡设置。目前试过的3090也能跑起来,目前我用的是4090d.然后r1是推理模型。token这