




- @weixin_42028608
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
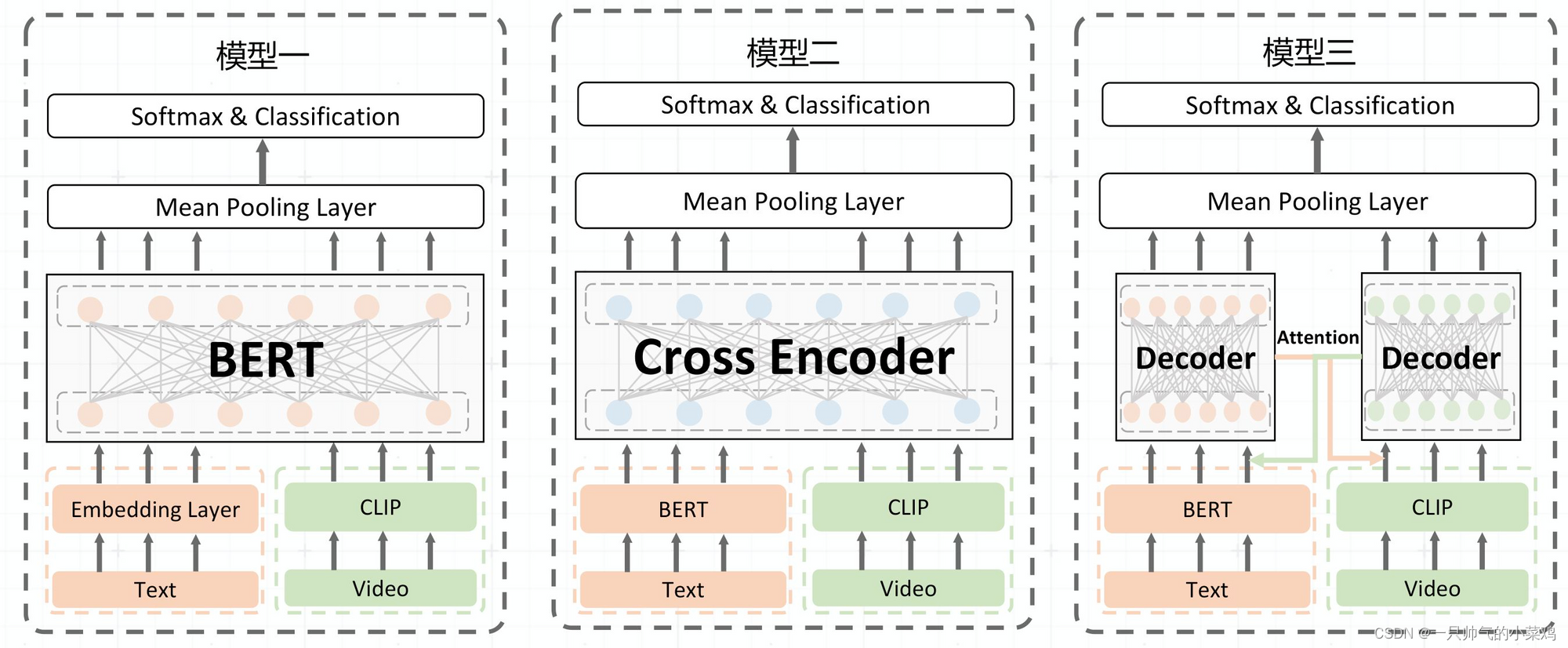
写在前面,最近一阵在做视频分类相关的工作,趁有时间来记录一下。本文更注重项目实战与落地,而非重点探讨多模/视频模型结构的魔改。
写在前面,最近两天在做ocr识别相关内容,趁有时间来记录一下。本文的代码是基于Pytorch框架mobilenetv3基础网络的CRNN+CTC网络实现文字检测与识别介绍文字识别也是图像领域一个常见问题。然而,对于自然场景图像,首先要定位图像中的文字位置,然后才能进行识别。所以一般来说,从自然场景图片中进行文字识别,需要包括2个步骤:文字检测:解决的问题是哪里有文字,文字的范围有多少文字识别:对定
人脸检索主要分为3个部分介绍:mtcnn、facenet、faiss首先,使用opencv读取视频,每25帧检测一次(1秒25帧,1秒取1次);使用mtcnn处理视频的帧 返回若干个人脸框、置信分及关键点,将图片按人脸框切割并resize成指定大小(160x160),然后利用关键点将人脸对齐,后送入faceNet提取人脸特征(128维),然后l2归一化后存储。最后用faiss对提取的人脸特征进行.
Train & Test Losstrain loss 不断下降,test loss不断下降,说明网络仍在学习;train loss 不断下降,test loss趋于不变,说明网络过拟合;train loss 趋于不变,test loss不断下降,说明数据集100%有问题;train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;t...
写在前面:本文不详细介绍SSD,只记录一些大体流程,具体细节可见参考1,换用数据集训练SSD可见参考2参考1:SSD代码细节讲解参考2:SSD换数据集训练给定图片如何得到对应的GTSSD网络若指定了先验框的minsize和maxsize,则整个图片的所有先验框位置均固定。拿300SSD来说,可以得到8372个位置确定的先验框(存于model_data/prior_boxes_ssd300...
BLEU参考:https://www.cnblogs.com/by-dream/p/7679284.htmlBLEU 采用一种N-gram的匹配规则+召回率+惩罚因子组合方式。N-gram当N=1时,一般用来判断文字生成的准确性,234用来判断生成文本的流畅性。原文:今天天气不错机器译文:It is a nice day today人工译文:Today is a nice day如...
常用激活函数(激励函数)理解与总结激活函数的区别与优点梯度消失与爆炸1. 激活函数是什么?在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。2. 激活函数的用途如果不用激活函数,每一层的输入都是上一层输出的线性函数,而多层线性函数与一层线性函数的功能是等价的,网络的逼近能力就相当有限,因此引入非线性函数作为激励函数,使得深层神经...
四种权重初始化方法:把w初始化为0对w随机初始化Xavier initializationHe initialization把w初始化为0:缺点:因为如果把w初始化为0,那么每一层的神经元学到的东西都是一样的(输出是一样的)。在梯度回传阶段,同一层内的所有神经元都是相同的,这样的话神经网络就没有意义了,相当于每一层只有一个神经元。因为在前项传播时,同层的所有神经元都相同,w也相同,在回传计算的梯度
Tutorials1. Generaldata loading:讲自定义数据加载操作iteratorpipeline构建DALI expressions and arithmetic operations:: 讲可以在tensor上自定义一些+ - * /操作Multiple GPU support:主要讲多GPU(shard_id:显卡id, num_shards:将数...
写在前面,最近两天在做ocr识别相关内容,趁有时间来记录一下。本文的代码是基于Pytorch框架mobilenetv3基础网络的CRNN+CTC网络实现文字检测与识别介绍文字识别也是图像领域一个常见问题。然而,对于自然场景图像,首先要定位图像中的文字位置,然后才能进行识别。所以一般来说,从自然场景图片中进行文字识别,需要包括2个步骤:文字检测:解决的问题是哪里有文字,文字的范围有多少文字识别:对定