




- @weixin_41636030
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
import numpy as npimport osimport xlrdimport datetimeimport matplotlib.pyplot as pltimport pandas as pdplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']...
在很多情况下,可能由于当前数据的限制或者数据的敏感性,导致所获得的数据很少,针对训练数据过少的情况,可以考虑以下办法迁移学习通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到现在的问题上。而之前这个经过预训练的模型,可能使用的不是同一类型的数据。这被称作“迁移学习”, 即将预训练的模型“迁移”到我们的问题中,举例,我们学会了打篮球,现在想学打排球,...
reward:指agent才去了某一action之后,能得到的即时反馈,比如围棋中,某一选手落子后,能够吃掉对手棋子,那么吃掉棋子就是对玩家的即时奖励,则agent采取行动会更倾向于吃子所获得的奖励;state-action value:状态行动价值函数,指特定状态下采取某种行动所获得的价值,如游戏中,在一个特定状态下,玩家根据状态价值函数,应该选择价值最大的的一个行动。state valu
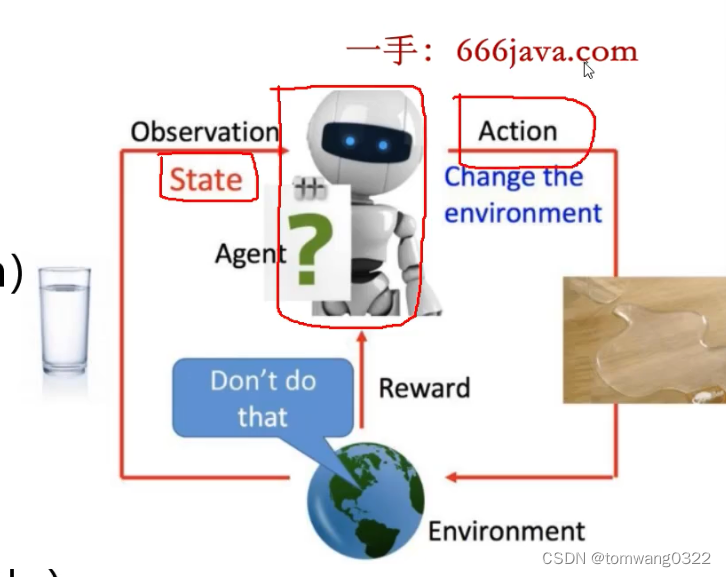
reward:指agent才去了某一action之后,能得到的即时反馈,比如围棋中,某一选手落子后,能够吃掉对手棋子,那么吃掉棋子就是对玩家的即时奖励,则agent采取行动会更倾向于吃子所获得的奖励;state-action value:状态行动价值函数,指特定状态下采取某种行动所获得的价值,如游戏中,在一个特定状态下,玩家根据状态价值函数,应该选择价值最大的的一个行动。state valu
安全库存的计算决定于需求的不确定性,供应的不确定性和服务水平,它和需求预测的区别在于需求预测对付的是平均需求,而安全库存对付的是库存里不确定性的需求。量化需求不确定性正态分布的假设前提:需求相对比较稳定,且相对比较频繁泊松分布的假设前提:需求很不稳定,或需求很低的情况(需要找到类似于标准差的参数)计算安全库存时,一般用13周(一个季度)的数据,即13个数据点模拟一个正态分布曲线。注:...
在很多情况下,可能由于当前数据的限制或者数据的敏感性,导致所获得的数据很少,针对训练数据过少的情况,可以考虑以下办法迁移学习通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到现在的问题上。而之前这个经过预训练的模型,可能使用的不是同一类型的数据。这被称作“迁移学习”, 即将预训练的模型“迁移”到我们的问题中,举例,我们学会了打篮球,现在想学打排球,...
需求预测(demand forecast)我们在构建模型时,主要分三步:查看input data构建metrics选取模型在这里模型的选取应放在最后一步,第一步通过查看input data,结合业务场景,洞悉影响业务的核心特征;第二步针对input data,我们需要根据需求确定合适的metrics,比如针对需求预测准确度的accuracy指标我们有MAPE, APE, AE, RM...
决策树的理解:1.2 分类树信息熵:用来衡量不确定性的指标,不确定性是一个事件出现不同结果的可能性,计算公式如下条件熵:在给定随记变量Y的条件下,随机变量X的不确定性信息增益:熵-条件熵,代表了在一个条件下,信息不确定性减少的程度1.2.2 基尼指数基尼指数:在样本集合中一个随机选中的样本被分错的概率注意:Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越
1)分析过程(共计7653个字),包含需求理解和需求补全惊喜部分以及实施步骤拆解和代码解析2)一个包含简单样例的代码框架测试后能在python上跑出结果3)代码简单说明【这部分比较粗】1) ds对用户提出的需求有更深层次的理解且比较精准,逻辑思维缜密2) ds在解释部分相比其他生成式大模型,能逐步拆解其思考逻辑和框架,解释也比较完善和清晰,对阅读者实现了其思考逻辑透明化3) 基于其思考逻辑,能对细

假设检验:两类错误:弃真存伪;阿尔法表示犯第一类错误(弃真)概率P值:如果原假设为真,则这个样本值发生的概率最大为多少对于匹配样本的检验,可以用匹配样本的差值来进行检验他们的显著水平匹配样本:同一个样本在不同时间点的状态F分布:两个分布的方差之比;检验两个分布方差的差异程度曲线相关:只存在数据挖掘;统计学只研究直线相关相关系数大于0.8:高度相关相关系数大于等于0.5,小于0.8...