




- @weixin_40972073
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
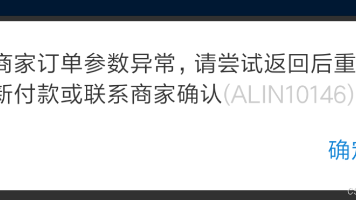
摘要 本文介绍使用uniapp调试支付宝沙箱支付的步骤:1)申请支付宝沙箱账号;2)下载uniapp官方demo;3)修改订单接口为服务端接口;4)关键配置沙箱环境(避免参数异常);5)使用沙箱版支付宝APP测试支付功能。重点提醒必须通过代码设置SANDBOX环境,并提供了错误排查方法(支付宝诊断工具查看调用记录)。完整流程可实现沙箱环境下的APP支付调试。
openclaw 养龙虾一体机,个人 AI 助手,自动化,爬虫等等超低功耗,超小巧,比手掌还小养龙虾一个月电费不到 2 块钱到手上电,配网,简单配置即可使用。

本文分享了作者备考NVIDIA生成式AI认证(NCA-GENM)的经验和建议。主要内容包括:1)备考路线建议先了解考试目标,按主题拆解学习内容并做实践笔记;2)认证分为Associate和Professional两个级别,开发者方向侧重AI模型开发,IT方向侧重基础设施;3)报名需提前购买考试券并预约考位,注意改期政策;4)考前需确认证件和环境准备;5)考试结果24小时内通知,未通过需间隔14天重

本文分享了作者备考NVIDIA生成式AI认证(NCA-GENM)的经验和建议。主要内容包括:1)备考路线建议先了解考试目标,按主题拆解学习内容并做实践笔记;2)认证分为Associate和Professional两个级别,开发者方向侧重AI模型开发,IT方向侧重基础设施;3)报名需提前购买考试券并预约考位,注意改期政策;4)考前需确认证件和环境准备;5)考试结果24小时内通知,未通过需间隔14天重
本文介绍了一个结合AI助手与桌面宠物概念的开源项目。作者观察到传统桌面宠物缺乏持久吸引力,而AI助手又过于工具化,因此开发了一个基于Tauri 2+Vue 3+TypeScript+Rust的智能桌面宠物助手。该项目通过养成系统实现从"宠物"到"助手"的渐进式转变,初期表现为需要互动的虚拟宠物,随着成长逐步解锁实用功能(如语音聊天、系统工具调用等)。项目采用
本文介绍了Kubernetes中Namespace、Pod、Deployment和Service的核心概念及常用命令。Namespace用于资源隔离,提供创建、查看、删除等操作命令;Pod作为最小部署单元,支持日志查看、容器交互等操作;Deployment管理Pod副本集,支持滚动更新、扩缩容和回滚;Service为Pod提供访问策略,包含ClusterIP、NodePort等类型。每个部分都提供

购买低价ESP32C3开发板踩坑实录:收到板子后出现串口识别问题,尝试安装CP2102驱动无效,最终通过安装CH343驱动解决。但随后发现GPIO口无法控制RGB灯,程序调试失败。作者建议新手避免购买非官方开发板,虽然价格便宜但问题频出,反而浪费时间和精力。官方开发板虽然贵但更稳定可靠,适合初学者入门嵌入式开发。

LMDeploy 是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。核心功能-量化核心功能-推理引擎TurboMind核心功能-推理服务。

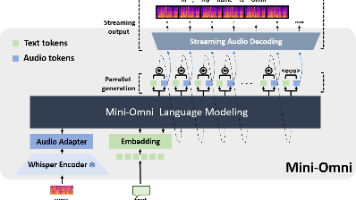
本文介绍了mini-omni项目的安装和启动过程。首先需要创建conda环境并安装依赖项,然后下载模型文件并启动服务端。在服务端启动过程中遇到两个问题:1) Config类初始化参数错误,需修改litgpt/config.py文件;2) state_dict中存在意外键值,需修改inference.py文件。客户端启动时遇到ASGI应用异常。整个流程包括环境配置、服务端部署和客户端连接,但存在一些
LMDeploy 是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。核心功能-量化核心功能-推理引擎TurboMind核心功能-推理服务。