
写文章




- @weixin_37005037
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
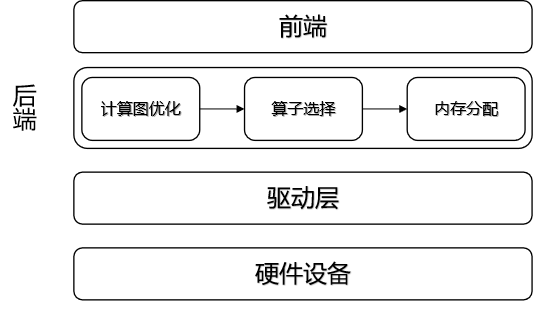
深度学习编译器后端和运行时
前言编译器前端将用户代码解析得到计算图 IR,并且做了一些和计算设备无关的通用优化。编译器后端做的优化就和具体的设备有关了(不同设备有不同的 allocator,不同的编程模型,比如英伟达的 CUDA),后端优化更加贴合硬件,会针对硬件特点为 IR 中的计算节点选择在硬件上的算子,然后为每个算子的输入输出分配硬件内存,最终...
到底了