




- @u012443641
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们可以在IDEA中直接运行spark程序,来连接服务器上的HDFS或者是spark集群来跑spark任务。提前工作我们需要先解决idea直接运行程序远程访问HDFS的问题。首先下载 hadoop-common-2.6.0-bin-master.rar压缩包(需要和服务器上的Hadoop版本对应),解压到任意目录,然后在环境变量中添加 HADOOP_HOME ,变量值为解压的位置。...
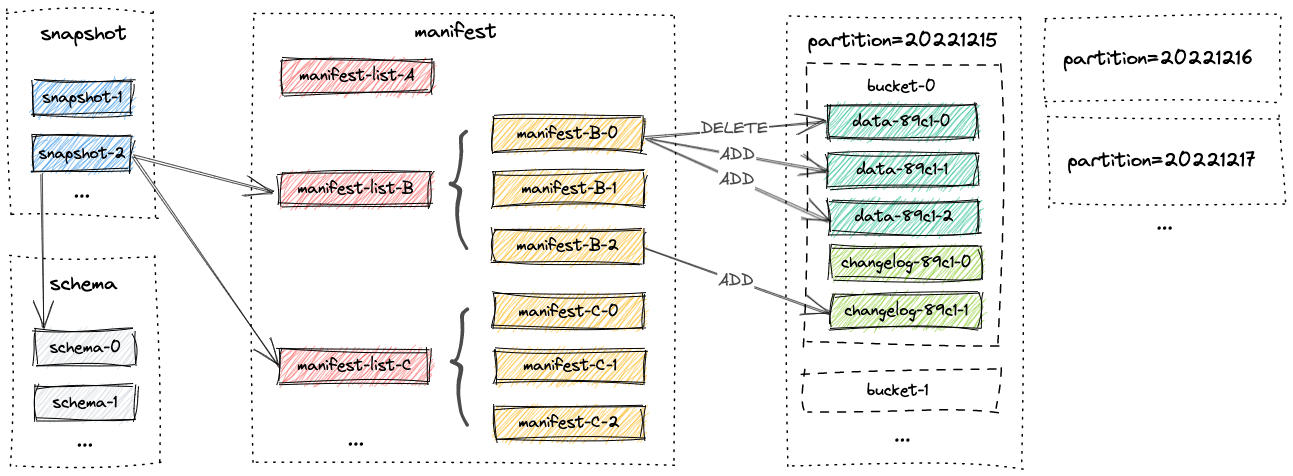
Apache Paimon 学习笔记,流式数据湖平台。
CDH-6.3.2内置spark-2.4.0的BUG
1.业务需求接收实时数据流数据,实时更新状态,并且每隔一定的时间,将所有状态数据输出。实时数据类型:("张", 1)状态更新:第一个元素为key,将第二个元素全部缓存起来,放到list中,最后将key和其对应的list全部输出。2. 实现方案使用processFunction算子,在processElement函数中仅注册一次定时器,然后在onTimer函数中处理定时器任务,...
本文按照 flink 1.13 官网中的读写 hive 内容翻译整理,内容十分全面。
python学习笔记,比较全面。
修改谷歌浏览器标签页名字
IEDA中的bashsupport插件支持在IDEA中编写shell脚本文件,有友好的代码格式,支持自动补全,检查错误,并且配置完之后,还可以在IEDA中直接运行shell脚本。下面将一步一步演示插件的安装和配置。打开IEDA,安装bashsupport插件安装完之后,保持插件选中并切实enable的状态,如下图所示,然后重启IDEA。...
本文是 flink sql 的一些使用案例,同时也包括了一些特殊用法展示。
本文基于 flink 官网翻译整理,基于1.13版本,内容十分全面