- @sujiangming
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文详细记录了在HarmonyOS NEXT开发过程中遇到的三个关键问题及解决方案:1) 真机签名验证失败(错误码1008231001),需配置手动签名并绑定设备UDID;2) Cloud DB的Integer类型限制导致Date.now()时间戳溢出(错误401),改用随机数生成32位安全ID;3) 双bindSheet弹窗冲突与云数据库延迟导致UI不同步,通过统一Sheet管理和增加数据

摘要:HarmonyOS 6.1.0 API 23 强化了 ArkTS 的类型安全特性,彻底禁用 any 类型并引入严格类型检查。文章通过《灵犀厨房》案例,详解 ArkTS 如何继承 TypeScript 核心功能(接口、枚举、泛型)并优化为鸿蒙原生开发语言,同时介绍 API 23 新规如动态特性禁用、装饰器严格规则等。实战部分展示如何用类型安全重构项目,包括定义数据模型、应用枚举替代魔法值,最终
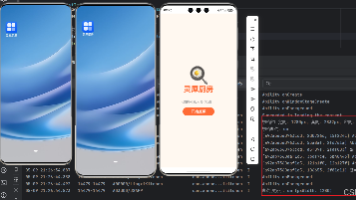
摘要:本文分享了在某政务服务中心落地3D数字人咨询系统的实战经验。项目目标是通过现有屏幕实现语音交互,分流窗口压力。团队先后尝试2D数字人(效果差)和自研3D方案(成本高),最终选用魔珐星云SDK的端云协同方案,支持离线部署和低延迟交互。文章详细解析了技术架构设计(端侧渲染+云端语义理解+本地知识库),并提供了Android集成代码示例及性能优化技巧(如预加载、本地检索优化)。项目上线后窗口咨询量

文章摘要:本文深入分析了HarmonyOS 6.1中元服务卡片"灵犀厨房"遇到的闪烁渲染问题。通过案例展示了模块级代码执行时机与卡片实例化时间的差异如何导致数据不一致,形成100ms的视觉闪烁。文章系统剖析了三个技术陷阱:模块级代码作为安装时刻快照、LocalStorage初始值污染、以及Form应用不支持定时器的限制。最终提出"空占位+dataReady标记"的双重守护方案,实现从"拍快照"到"

【摘要】 本文以 HarmonyOS 6.1 服务卡片开发中的日期动态化问题为案例,揭示了 Form Kit 数据绑定的典型陷阱。当《灵犀厨房》卡片始终显示硬编码日期"1月1日 周一"时,排查发现:尽管 EntryFormAbility 正确生成了动态日期并通过 formProvider.updateForm() 推送,但 WidgetCard 端的 readonly 属性阻断了数据流动。根本原因

HarmonyOS 日历提醒功能开发实践 文章摘要 在HarmonyOS元服务中开发饭点提醒功能时,使用Calendar Kit遇到了提醒不稳定的问题。本文深入分析了Calendar Kit的权限模型和提醒触发机制,揭示了秒级精度校验的关键细节:创建日程时必须确保秒和毫秒值为零,否则提醒可能失效。针对这一痛点,作者提出了双模架构解决方案: 天级重复提醒:用于正式饭点提醒 即时测试提醒:作为验证手段
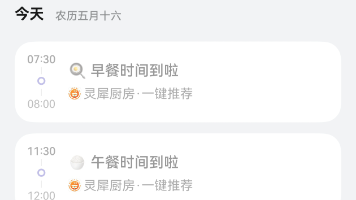
本文记录了《灵犀厨房一键推荐》元服务在开发调试阶段遇到的四个关键性Bug及其修复过程: Bug 1:CloudDB启动崩溃(错误码1008230001),根因为异步生命周期竞态问题。修复方案采用懒初始化+幂等检查+降级兜底策略,通过防御性编程确保稳定性。 Bug 2:UI界面刷新失效,原因是ArkUI状态追踪机制未被正确触发。通过重构状态管理逻辑,确保数据变化能正确驱动UI更新。 Bug 3/4:
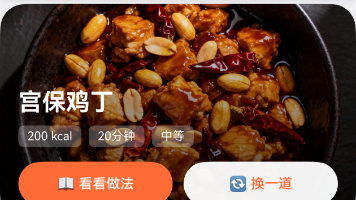
《灵犀厨房一键推荐》元服务通过"三段式数据流"架构解决复杂状态管理问题:隐私协议检查 → CloudDB数据查询 → 推荐引擎计算 → UI渲染。针对隐私未同意、查询超时、数据为空等5种异常状态,采用分层降级策略(默认偏好、空数据兜底、强制刷新key)。核心模块包括毛玻璃隐私弹窗(合规启动)、CloudDB异步查询(错误隔离)和智能推荐引擎(偏好适配)。该架构在HarmonyOS 6.1上实现全链

现象真相解决方案重构后编译报忘记 import 常量类了在文件头部加改成普通staticArkTS 编译器警告"非常量表达式"必须用readonly修饰符,确保编译时常量语义把也放进 AppConstants是系统内置枚举,放常量里反而绕路系统内置颜色/枚举直接使用,只常量化自定义设计令牌常数0放进 AppDimensions毫无意义零值是默认值,不需要语义化常量按钮宽度 140 硬要常量化140
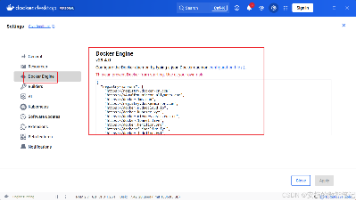
摘要:Windows本地部署Dify平台全流程指南 本文详细记录了在Windows笔记本上部署Dify社区版的完整过程及常见问题解决方案。硬件配置方面,4核CPU+32GB内存+SSD即可流畅运行。关键步骤包括:安装Docker Desktop(需启用WSL2)、克隆Dify仓库、通过docker-compose启动服务。针对镜像拉取超时、容器卡死、前端白屏等问题,提供了配置国内镜像源、单独拉取镜