




- @seinfduke
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GPT-5.5不是一次渐进式升级。在46项基准测试中,它在编程、知识工作、数学推理、长上下文推理等多个维度建立了领先,部分领域是代际差距。但"基准测试领先"和"真实世界价值"之间仍有距离。AI能力的评估是多维度的,没有单一模型能在所有场景中称王。GPT-5.5的意义在于:它重新定义了"能力边界"的基准线。竞品必须追赶这个新基准,而整个行业的能力天花板也随之抬升。对从业者而言,现在的问题不是"AI能

如果全部用 DeepSeek V4 Pro(medium 推理 + 优惠价)每日:200 × 5,000 = 1,000,000 Token输出占比约 40%(含推理)= 400,000 输出 Token每日成本:600,000 × 3 + 400,000 × 6 = 180 万 + 240 万 =¥4.2/天每月约¥126如果改用分层策略60% → V4 Flash:600,000 × 1 +

记忆系统不是「越多越好」,是「越准越好」。一个好的记忆系统,应该让 Agent 像一个跟了你三年的老员工——知道你的脾气、你的规矩、你的雷区,不用你每次都重复。但它也不该是一个「全知全能的神」——什么都记、什么都存、什么都往里塞,最后连自己都搞不清哪条是纪律、哪条是建议。记住这三个字:分层、精简、验证。这就是 AI Agent 记忆系统的全部秘密。
我敢打一个赌。你现在打开手机上的飞书,跟你的AI Agent聊半小时,它温文尔雅、有问必答、逻辑清晰。然后你打开终端,输入同样的指令,同一个AI,同一家公司,同一个模型——它突然就像换了个人。不是比喻,是字面意思上的"换了个人"。飞书端的Agent记得你昨天聊了什么,CLI端的Agent对你一脸茫然。飞书端的Agent乖乖执行你的规则,CLI端的Agent把你的规则当废纸。飞书端的Agent给你真
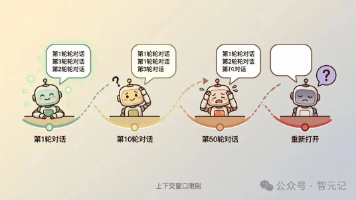
记忆系统不是「越多越好」,是「越准越好」。一个好的记忆系统,应该让 Agent 像一个跟了你三年的老员工——知道你的脾气、你的规矩、你的雷区,不用你每次都重复。但它也不该是一个「全知全能的神」——什么都记、什么都存、什么都往里塞,最后连自己都搞不清哪条是纪律、哪条是建议。记住这三个字:分层、精简、验证。这就是 AI Agent 记忆系统的全部秘密。
我敢打一个赌。你现在打开手机上的飞书,跟你的AI Agent聊半小时,它温文尔雅、有问必答、逻辑清晰。然后你打开终端,输入同样的指令,同一个AI,同一家公司,同一个模型——它突然就像换了个人。不是比喻,是字面意思上的"换了个人"。飞书端的Agent记得你昨天聊了什么,CLI端的Agent对你一脸茫然。飞书端的Agent乖乖执行你的规则,CLI端的Agent把你的规则当废纸。飞书端的Agent给你真
GPT-5.5不是一次渐进式升级。在46项基准测试中,它在编程、知识工作、数学推理、长上下文推理等多个维度建立了领先,部分领域是代际差距。但"基准测试领先"和"真实世界价值"之间仍有距离。AI能力的评估是多维度的,没有单一模型能在所有场景中称王。GPT-5.5的意义在于:它重新定义了"能力边界"的基准线。竞品必须追赶这个新基准,而整个行业的能力天花板也随之抬升。对从业者而言,现在的问题不是"AI能
腾讯推出TencentDB Agent Memory解决方案,解决AI Agent"失忆"问题。该方案采用四层记忆金字塔结构(L0原始对话、L1结构化事实、L2场景块、L3用户画像),通过符号化记忆和Mermaid图谱降低Token消耗61%,提升任务成功率52%。部署过程需五步安装配置,并针对常见故障提供解决方案。TencentDB与Hindsight形成互补双引擎,分别管理对话记忆和技术知识库
国家超算互联网正式上线,将重塑AI产业格局。这一覆盖全国的超算网络整合了十余个国家级超算中心,提供E级算力服务,使AI算力获取成本降低30-50%。这将打破大厂的算力垄断,降低中小企业进入门槛,但也将加剧算法、数据和场景的竞争。超算互联网不仅影响AI行业,还将改变生物医药、自动驾驶等多个依赖高性能计算的领域。这场算力资源的重新洗牌,既是机遇也是挑战,企业必须快速适应这一变革,否则将面临被淘汰的风险

Hermes Kanban解决的不是"AI不够聪明"的问题。它解决的是"AI不可靠"的问题。当你的AI助手可以在关键时刻停下来问你,可以在失败后不丢失进度,可以让多个专业Agent协同完成一个复杂任务——你就拥有了一个真正可用的AI工作流,而不只是一个人工智障。你用Kanban做过什么复杂任务?有什么坑或经验?欢迎来聊。「智元记」
