




- @qsmx666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1 基本概念熵描述信息的不确定度。熵越大,信息的不确定度越大。信息量I(x)=−log(p(x)) I(x)=-log(p(x))I(x)=−log(p(x))信息是用来消除随机不确定性的东西。衡量信息量大小就看这个信息消除不确定性的程度。事件发生的概率越低,信息量越大。举个例子,“一个人是女性”和“一个人是大学老师”哪个信息量大呢?显然是后者。前者的概率是1/2,后者的概率远小于1/2。信息熵可
端到端的深度学习就是用单个神经网络代替多阶段的处理过程。以语音识别为例,传统方法的步骤是首先提取一些特征,然后应用机器学习算法在音频片段中找到音位,再把这音位提取出来构成独立的词,最后将词串起来构成音频片段的听写文本。而端到端的方法不需要这些步骤,只要把音频作为神经网络的输入,输出就是听写文本。我们不需要知道神经网络是如何拟合数据的,只要得到最后的输出。端到端深度学习的优点让数据说话只要有...
同样是吴恩达深度学习课程的作业,我把它改成pytorch版本了。有了上次的经验,这次就没花多少时间了。1 packagesimport numpy as npimport torchfrom torch import nnimport matplotlib.pyplot as pltimport torch.utils.data as Datafrom torch.nn import...
端到端的深度学习就是用单个神经网络代替多阶段的处理过程。以语音识别为例,传统方法的步骤是首先提取一些特征,然后应用机器学习算法在音频片段中找到音位,再把这音位提取出来构成独立的词,最后将词串起来构成音频片段的听写文本。而端到端的方法不需要这些步骤,只要把音频作为神经网络的输入,输出就是听写文本。我们不需要知道神经网络是如何拟合数据的,只要得到最后的输出。端到端深度学习的优点让数据说话只要有...
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)num_features –特征维度eps – 为数值稳定性而加到分母上的值。momentum – 移动平均默认的动量值。affine – 一个布尔值,当设置为真时,此模块具有可学习的仿射参数。这里其他几
x = torch.tensor([[0, 2],[3,4],[9,8]])print(x.shape)x = torch.tensor([0,1,2,4,5,6,2])print(x.shape)
同样是吴恩达深度学习课程的作业,我把它改成pytorch版本了。有了上次的经验,这次就没花多少时间了。1 packagesimport numpy as npimport torchfrom torch import nnimport matplotlib.pyplot as pltimport torch.utils.data as Datafrom torch.nn import...
首先,导入包。import numpy as npimport pandas as pdimport matplotlib.pyplot as plt导入数据并查看。data= pd.read_csv("../data/score.csv")data.head()可以看到,数据即不同分数段不同班级的学生人数。先来看一下绘制效果。横坐标是分数段,纵坐标是人数,柱形中不同颜色的块表示各个班级人数占比,
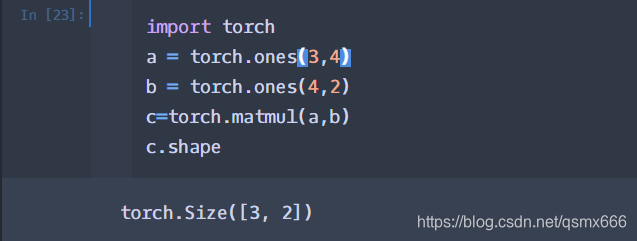
torch.mm()
端到端的深度学习就是用单个神经网络代替多阶段的处理过程。以语音识别为例,传统方法的步骤是首先提取一些特征,然后应用机器学习算法在音频片段中找到音位,再把这音位提取出来构成独立的词,最后将词串起来构成音频片段的听写文本。而端到端的方法不需要这些步骤,只要把音频作为神经网络的输入,输出就是听写文本。我们不需要知道神经网络是如何拟合数据的,只要得到最后的输出。端到端深度学习的优点让数据说话只要有...