
写文章




- @qq_62924144
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
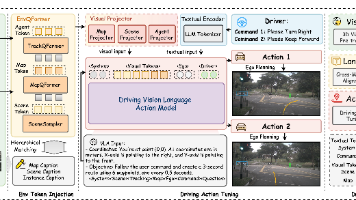
【2025nuScenes新SOTA】OpenDriveVLA:采用大视觉语言动作模型实现端到端自主驾驶
本文提出了OpenDriveVLA,一种为端到端自动驾驶而设计的视觉-语言动作(VLA)模型。OpenDriveVLA建立在开源的预先训练的大型视觉语言模型(VLM)的基础上,以3D环境感知、自我车辆状态和驾驶员命令为条件生成可靠的驾驶动作。为了弥合驱动视觉表征和语言嵌入之间的通道鸿沟,我们提出了一种层次化视觉语言对齐过程,将2D和3D结构化视觉标记投影到统一的语义空间中。
到底了