
写文章




- @qq_45708407
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【论文精读】Video LLaMA:给语言大模型加上综合视听能力
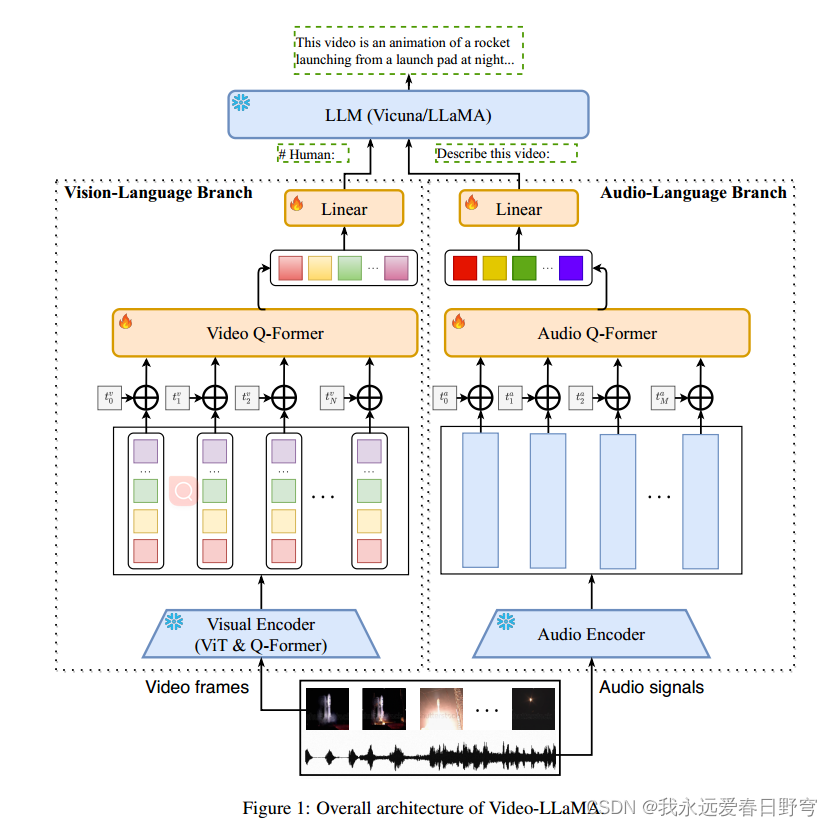
文章为解决冻结的LLM与冻结的encoder之间的连接问题,基于Blip-2的风格,提出了一种多分支跨模态训练模型,并进一步提出了一个多模态大语言模型Video-LLaMA。该模型可以很好的完成连接任务,并且明确地捕捉了视频中的场景变化并对齐了音频与视频模态。但是该模型仍有一些缺点:(1)受到当前数据集的限制,模型的感知能力仍然较弱,需要构建更高质量的音频-视频-文本对齐数据集;(2)视频对于长视
【论文精读】Video LLaMA:给语言大模型加上综合视听能力
文章为解决冻结的LLM与冻结的encoder之间的连接问题,基于Blip-2的风格,提出了一种多分支跨模态训练模型,并进一步提出了一个多模态大语言模型Video-LLaMA。该模型可以很好的完成连接任务,并且明确地捕捉了视频中的场景变化并对齐了音频与视频模态。但是该模型仍有一些缺点:(1)受到当前数据集的限制,模型的感知能力仍然较弱,需要构建更高质量的音频-视频-文本对齐数据集;(2)视频对于长视
【论文精读】Video LLaMA:给语言大模型加上综合视听能力
文章为解决冻结的LLM与冻结的encoder之间的连接问题,基于Blip-2的风格,提出了一种多分支跨模态训练模型,并进一步提出了一个多模态大语言模型Video-LLaMA。该模型可以很好的完成连接任务,并且明确地捕捉了视频中的场景变化并对齐了音频与视频模态。但是该模型仍有一些缺点:(1)受到当前数据集的限制,模型的感知能力仍然较弱,需要构建更高质量的音频-视频-文本对齐数据集;(2)视频对于长视
到底了