




- @qq_41204464
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AMP 算法与代码分析技术博客摘要 本文深入解析AMP(Adversarial Motion Priors)算法在本项目中的实现细节,重点关注其核心思想、特征定义、训练流程和关键配置。AMP通过判别器学习专家动作的状态转移分布(而非逐帧复刻),将其转化为风格奖励与任务奖励融合,最终由PPO更新策略。文章详细阐述了AMP的390维特征向量(包含13个身体部位的位置、姿态和速度信息)、训练数据流设计(

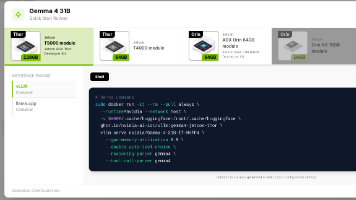
🚀 JetsonvLLM 实践 ,实现 `LLM / VLM`推理:从 `Qwen`、`Gemma`、`Llama`,到 `Nemotron`、`Cosmos`、`GPT OSS`;从 `0.8B`、`4B` 的轻量模型,到 `31B`、`70B`、`120B` 的大模型;从纯文本推理,到图像、视频、音频和 `Physical AI reasoning`。
本文综合整理单目3D目标检测的方法模型,包括:基于几何约束的直接回归方法,基于深度信息的方法,基于点云信息的方法。万字长文,慢慢阅读~ 直接回归方法涉及到模型包括:MonoCon、MonoDLE、MonoFlex、CUPNet、SMOKE等。基于深度信息的方法涉及到模型包括:MF3D、MonoGRNet、D4LCN、MonoPSR等。基于点云信息的方法涉及到模型包括:Pseudolidar、DD3

学习了一个学期机器学习算法,从什么都不懂到对十个机器学习算法有一定的了解,下面总结一下十大机器学习算法,从算法的概念、原理、优点、缺点、应用等方面来总结,如果有错误的地方,欢迎指出。目录1.决策树2.线性回归3.逻辑回归4.支持向量机SVM5.朴素贝叶斯1.决策树这个监督式学习算法通常被用于分类问题。它同时适用于分类变量和连续因变量。在这个算法中...
本文分享SMOKE最新的版本的环境搭建,以及模型训练;环境关键库版本:pytorch 1.12.0、CUDA 11.3、cudnn 8.3.2、python 3.7、DCNv2。

HumDex 是一个面向人形机器人 全身灵巧操作的便携式遥操作系统。

Ψ₀是面向“人形机器人” 移动+操作 的VLA模型,🚀支持全身控制的,实现 上肢操作+下肢移动。Ψ₀采用层级化三系统架构。Ψ₀的设计不仅关注“训练性能”,更关注**真实世界的部署落地**——机器人模型的核心价值是在真实世界中稳定执行任务,因此本章还提出了三大关键技术,解决**推理抖动、遥操作数据质量低、动作生成效率差**的实际问题,让模型从“实验室训练”走到“真实机器人执行”。

本文分享 MonoDLE 的模型训练、模型推理、可视化3D检测结果。

DD3D是一种端到端单阶段的单目3D目标检测方法,它在训练时用到了点云数据,监督深度图的生成,共享预测深度的特征提取层;推理时不用点云数据了,只需图像数据和相机内参,即可完成3D框的信息预测。这是预训练和共享权重的思路。

本文分享国内场景3D目标检测,公开数据集 DAIR-V2X-V(也称为DAIR-V2X车端)。DAIR-V2X车端3D检测数据集是一个大规模车端多模态数据集,包括:22325帧图像数据、22325帧点云数据、2D&3D标注。基于该数据集,可以进行车端3D目标检测任务研究,例如单目3D检测、点云3D检测和多模态3D检测。
