




- @qq_39006282
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
llm总要给一个token做开头。但是也好解决,给所有话的前面加一个固定的token,就叫bos,那这就等于是初始状态了,就可以看做是生成式了。再考虑现在所有llm都要一个bos,所以现在的llm都是生成式。你想啊,生成式模型一开始可以啥都不给,就从初始状态(无)加一个转移矩阵获得第一个token。而判别式模型必须给一个x才能输出y。两者最主要的区别是提不提供x,也因此,二者的学习目标有差别,前者
zero是一个实验,它不足以作为商业化模型进行应用。
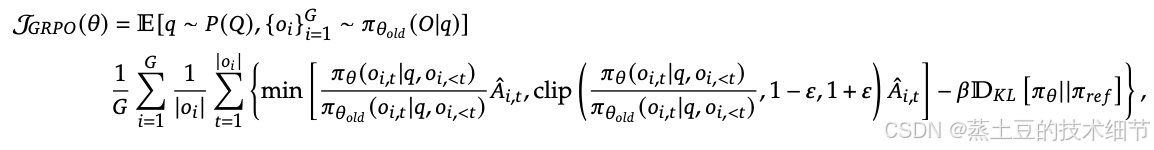
直接从第二章Architecture开始。
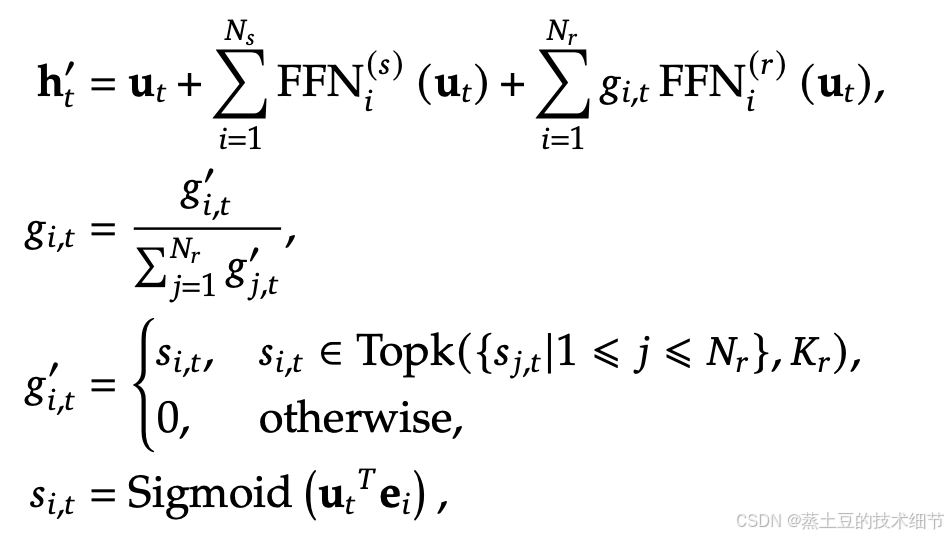
vllm从orca那抄到的连续批处理有缺点,它期望“在batch里动态卸载、加载序列”,也确实做到了,但是prefill和decoder俩阶段的计算方法不一样,前者一次性算出来,后者一个一个吐出来,两个的操作方法不同导致消耗的时间不同。显然,花费的时间仍然要看最长prefill token数,还是浪费算力。回看orca,它没有分prefill和decode,当前batch所有序列该推哪步推哪步,第
现在大模型训练数据的主力都是LLM自己贡献的了。但是也不是说你让它输出什么,然后它就一劳永逸地不停地输出你想要的东西。受限于LLM本身的能力、上下文规定的长度、训练方式导致的有限变化,你需要不断变更你的prompt,以让输出更多样。接下来介绍的数据生成方法。

我没找到好的解决办法,issue里说的情况都是在用源码安装后遇到的,我直接在干净环境ubuntu20.24 cuda12.2下面pip安装,仍然遇到了问题。而且问题指向是torch里的class缺少属性,因此我猜测是torch的问题,vllm的每个版本又强制要求某个torch版本,因此我只能选择之前的vllm版本。vllm0.5.2最近一周出了个不好搞的新issue,会遇到torch.ops._C
现在大模型训练数据的主力都是LLM自己贡献的了。但是也不是说你让它输出什么,然后它就一劳永逸地不停地输出你想要的东西。受限于LLM本身的能力、上下文规定的长度、训练方式导致的有限变化,你需要不断变更你的prompt,以让输出更多样。接下来介绍的数据生成方法。
zero是一个实验,它不足以作为商业化模型进行应用。
直接从第二章Architecture开始。