




- @qq_36104364
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出一种利用交叉注意力机制实现文本驱动的图像编辑方法,可以对生成图像中的对象进行替换,整体改变图像的风格,或改变某个词对生成图像的影响程度,如下图所示。之前的文本驱动的图像生成方法很难对图像的内容进行精细地编辑,哪怕只改变了一点文本提示的内容都可能让生成的结果发生非常大的改变,而无法保留原有的内容和结构。为了保留图像整体的结构,只对特定目标进行修改,有些方法通过让使用者给出要修改对象的掩码,引

此外,由于很多扩散模型是直接对图像进行扩散和去噪的,这就导致模型的维度很大,计算量很高,这也导致很多扩散模型不能处理高分辨率的图像,且生成速度很慢。作者采用类似LDM的思想,不对图像直接进行扩散和生成,而是对压缩过的特征信息IPR进行扩散和生成,这就极大的提升了图像转换的效率。关于DA模块和DFFN模块的输出是怎么进行融合的,原文中我没看到,但是图中可以看出来动态Transformer块的输入和输
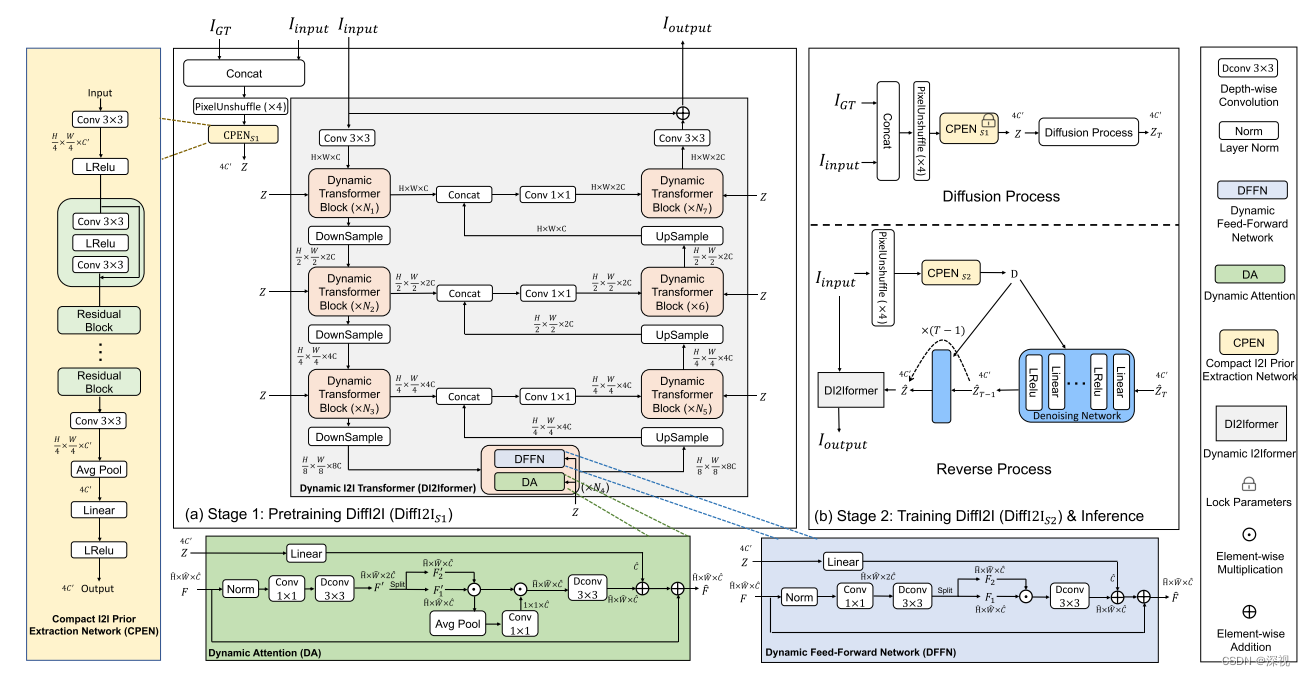
该文提出一种基于语义引导扩散模型的的图像生成算法,SDG,可使用文本或图像作为引导来指引图像的生成,也可以二者同时使用,实现多模态的引导。增加引导信息无需对扩散模型进行微调训练,可以直接作用在生成阶段。相对于现有的文本引导图像生成方法StyleCLIP或图像引导生成方法ILVR,SDG不仅能够适应更多模态的输入,且生成样本也具备更大的多样性。
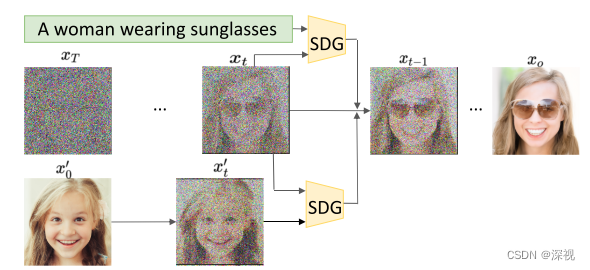
至此,我们已经完整的介绍了DDPM、NCSN和SDE三个基于扩散模型的图像生成工作,这三个工作也是整个扩散生成领域的理论基础,后续的众多工作都是在此基础上进行改进和应用。后面,我们将介绍两个基于DDPM的改进工作:DDIM和IDDPM。
该文通过对扩散模型中添加噪声的时刻$t_k$和噪声$N$进行优化,提升SD等文生图模型的图像编辑效果。作者指出现有的方法为了提升文生图模型的图像编辑质量,通常是引入更多的条件信息,如编辑指令(InstructPix2Pix)、边缘图、分割图(ControlNet)等。而较少有人关注扩散模型中的两个关键超参数,时刻$t_k$和噪声$N$,对于编辑效果的影响。因此,作者专门探索了这两个参数对于编辑效果

该文提出一种无需训练,即可对图像进行文本驱动编辑的方法。在准确修改目标对象的同时,保证原图的背景和布局等内容不受太多的影响。下图展示了几种文本驱动图像编辑的效果,如将猫变成狗,将马变成斑马等。该文主要做了以下几点工作,首先将输入的图像x利用Stable Diffusion编码到潜在空间得到x0,并按照DDIM中的确定性过程将其扩散为噪声编码xinv。然后,利用BLIP模型得到输入图像对应的文本

该文提出一种精细的由文本指令驱动的图像编辑技术,与InstructPix2Pix类似,给定一段文字修改指令就能对图像进行准确精细的修改。

开发环境:Unbuntu 18.04 LTS + ROS Melodic + ViSP 3.3.1 本文主要介绍了如何实现Pionner3dx移动机器人视觉伺服仿真,仿真环境是ROS+Gazebo,控制对象是Pioneer3dx(先锋)移动机器人,控制算法借助visp_ros工具实现。视觉伺服控制部分主要参考了visp_ros中的例程tutorial-ros-pioneer-visual-ser
开发环境:Ubuntu 18.04 LTS + ROS Melodic + ViSP 3.3.1文章内容主要参考ViSP官方教学文档:https://visp-doc.inria.fr/doxygen/visp-daily/tutorial_mainpage.html 本文主要介绍了如何使用ViSP实现目标检测和定位,实现过程分为两步,第一步在参考图像中检测并提取目标物体表面的关键点,并保存其对
深度学习入门指南0. 前言 各位同学大家好!大家本科可能来自于机械类、自动化类等专业,具备一定的数学理论基础(如概率与统计,线性代数等)和C语言的编程基础,现在希望向深度学习领域发展,可又感觉无从下手,不知道应该怎样开始。因为本文的作者也是在硕士阶段完成了这一痛苦的转型,因此对于大家的困惑,我是感同身受的。在回顾了过去两年多以来的学习经历之后,我们整理了这份深度学习的入门指南,希望能够为大家梳理