




- @qq_22764813
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
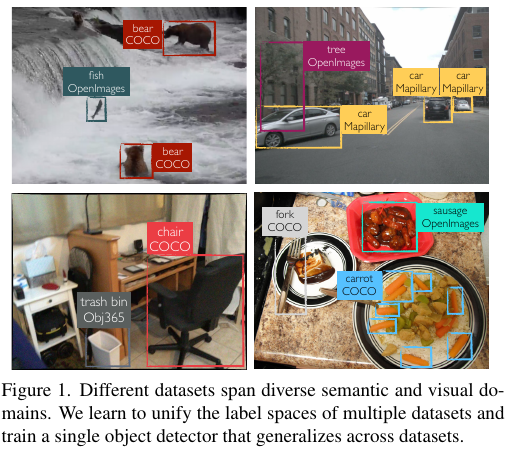
作者使用了一个简单的方法在大批量的数据集上用于训练一个统一的检测器。
yolov5的数据增强代码来自两个地方:1.albumentations源码在utils/augmentations.py中,使用了albumentations这个库来处理数据增强,其中处理的细节可以自行搜索使用细节,要是环境中没有安装albumentations库,那么执行时就会跳过这块的数据增强,附源码查看:class Albumentations:# YOLOv5 Albumentation
首次使用yolov8训练检测,踩坑记录;

yolov5的数据增强代码来自两个地方:1.albumentations源码在utils/augmentations.py中,使用了albumentations这个库来处理数据增强,其中处理的细节可以自行搜索使用细节,要是环境中没有安装albumentations库,那么执行时就会跳过这块的数据增强,附源码查看:class Albumentations:# YOLOv5 Albumentation
1.统一图片尺寸实际使用案例:在训练yolov5过程中,收集到的图片尺寸有两种1920*1080和640*480;实际使用的场景是640*480,可以将所有图片尺寸缩放到640*480,同时要注意缩放过程中,目标尺寸不要失真;具体操作过程中,可以先观察真实场景数据,然后在对大尺寸图片进行处理;本案例中,就发现1920*1080的图片内容在宽方向图内背景内容更多,而高方向图像内容和640*480的图
1.统一图片尺寸实际使用案例:在训练yolov5过程中,收集到的图片尺寸有两种1920*1080和640*480;实际使用的场景是640*480,可以将所有图片尺寸缩放到640*480,同时要注意缩放过程中,目标尺寸不要失真;具体操作过程中,可以先观察真实场景数据,然后在对大尺寸图片进行处理;本案例中,就发现1920*1080的图片内容在宽方向图内背景内容更多,而高方向图像内容和640*480的图
最近训练了一个人脸识别模型,在测试集上的效果较之前的模型相比(lfw,cfp_fp,agedb_30),accucay都有所提升,但是在自己的测试集效果上却特别差。然后仔细的研读了相应的测试代码,先把训练工程中的代码贴出来:diff = np.subtract(embeddings1, embeddings2)#做减法dist = np.sum(np.square(diff), 1)#计算...
最近在查看论文《Towards Flops-constrained Face Recognition》时,发现作者使用了AdaBN的技巧,我很好奇AdaBN是什么操作,为甚么没有看见相应的博文介绍,下面是我自己整理的资料。论文链接:原文中的算法:通俗理解:把model设成训练模式,然后是做前向计算,不做反向更新,相当于只更新global mean和global variance;将所有测试样本跑一
1.统一图片尺寸实际使用案例:在训练yolov5过程中,收集到的图片尺寸有两种1920*1080和640*480;实际使用的场景是640*480,可以将所有图片尺寸缩放到640*480,同时要注意缩放过程中,目标尺寸不要失真;具体操作过程中,可以先观察真实场景数据,然后在对大尺寸图片进行处理;本案例中,就发现1920*1080的图片内容在宽方向图内背景内容更多,而高方向图像内容和640*480的图
WierwiIIe驾驶模拟器上的实验结果证明,眼睛的闭合时间一定程度地反映疲劳, 如图 所示。在此基础上, 卡内基梅隆研究所经过反复实验和论证,提出了度量疲劳/瞌睡的物理量 PERCLOS (Percentage ofEyeIid CIosure over the PupiI, over Time, 简称PERCLOS) 其定义为单位时间内 (一般取1 分钟或者 30 秒) 眼睛闭合一定...