- @qq_16792139
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】gitlab提交代码冲突You have divergent branches and need to specify how to reconcile them。

到java目录下再运行。
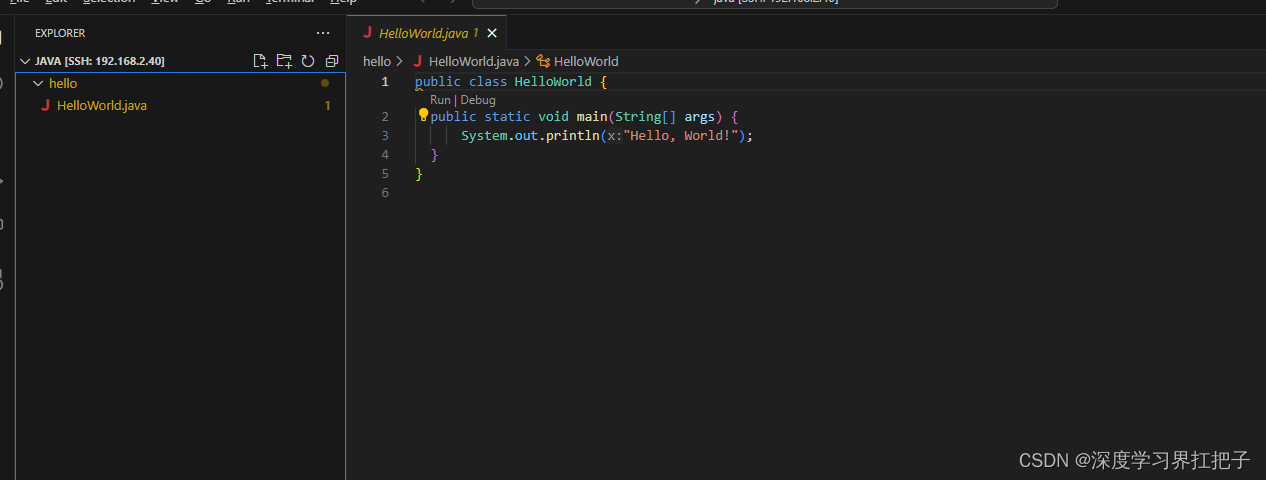
右键maven新建项目
openvino安装
pip install pyspark
进到页面https://www.apache.org/dyn/closer.lua/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz下载spark
第一步:标注数据集使用到的工具是labelimg,可以直接下载exe文件,我这边就不做演示了因为博主之前做过TensorFlow objection detection 识别,就用了原来的标注的数据集,这样可以省下很多时间,而我们只需要将xml文件改为txt格式格式如下因为xml文件里面的格式是下面的这里我会提供py代码(将网上的代码进行了更改)import xml.etree.ElementTr
CV算法工程师负责设计、开发和优化各种算法,以处理和分析图像和视频数据。CV算法工程师负责设计、开发和优化各种算法,以处理和分析图像和视频数据。目标检测:R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN)、YOLO系列、SSD等。选择一个感兴趣的CV领域(如人脸识别、自动驾驶、医疗影像分析等),自主设计并实现一个项目。根据自己的兴趣和特长,选择适合的职业发展方向(如算法研

Jpype是一个能够让python代码方便调用java代码的工具。

如TensorFlow、PyTorch等深度学习框架,以及SpeechRecognition、gTTS(Google Text-to-Speech)等库,为智能语音与对话系统提供了强大的支持。传感器融合:将来自不同传感器(如激光雷达、摄像头、雷达等)的数据进行融合,以提高感知的准确性和鲁棒性。语义分割:使用深度学习模型将图像中的每个像素分类到不同的类别中,如道路、车辆、行人等,以实现对场景的深入理