




- @prike
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
其实去年就已经把Android上OpenCL的demo做出来了,但是由于种种原因一直没有开源–嗯现在就不吝啬了~奉献给大家~后面在Android上还实现了很多种并行化的算法,比如SHA-1、HDR、K-means、NL-means、SRAD等等,会在近期整理好之后开源的。原文发表在了异构开发技术社区整理成教程是队友做的,十分感谢~原博文地址队友的博客项目gith
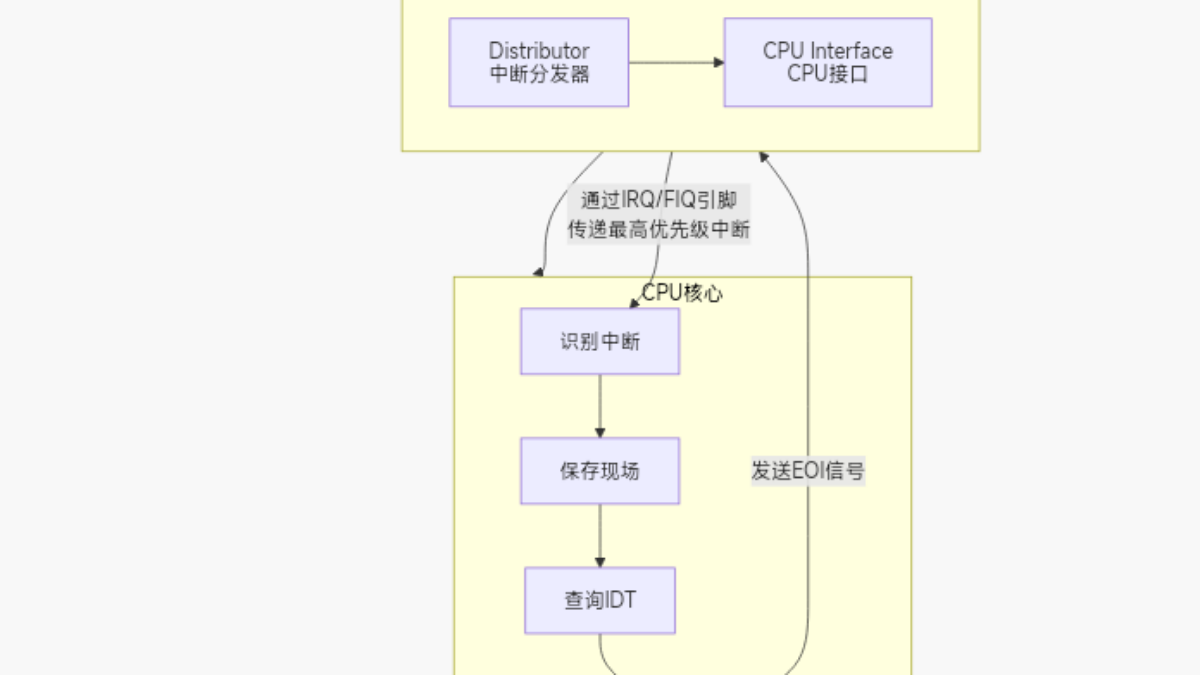
驱动开发者需要理解“上半部紧急处理,下半部实际工作”的哲学,根据需求选择合适的下半部机制(对于简单任务,Tasklet;对于复杂或可能阻塞的任务,工作队列或线程化中断),并严格遵守中断上下文的编程约束,才能编写出高效、稳定的设备驱动程序。CPU会暂停当前执行的任务,转去执行一个预先定义好的函数(中断处理程序),处理完毕后再恢复原任务。中断系统一个非常核心的Linux内核主题,本文将梳理内核中断系统
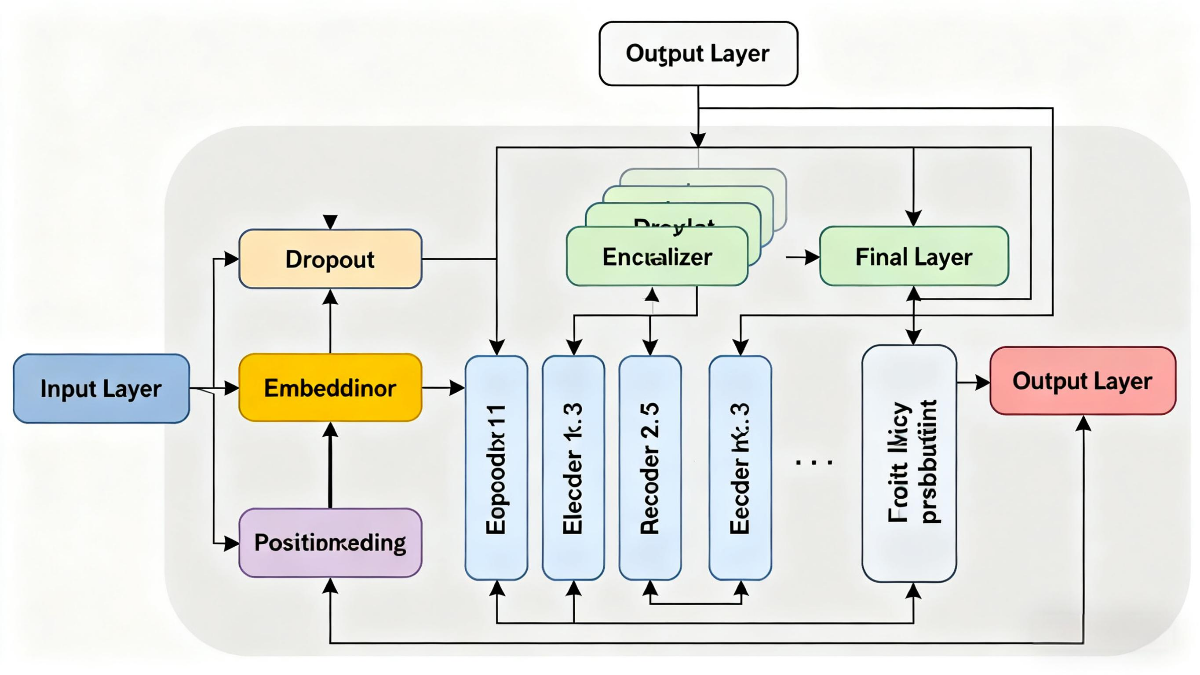
一、千万参数大模型核心源码(PyTorch实现) 基于Transformer解码器架构,实现1200万参数大模型(可通过调整维度/层数扩展至千万级),支持文本自回归生成,代码精简且易理解: python。
1.SEAndroid app分类SELinux(或SEAndroid)将app划分为主要三种类型(根据user不同,也有其他的domain类型):1)untrusted_app 第三方app,没有android平台签名,没有system权限2)platform_app 有android平台签名,没有system权限3)system_app 有andr
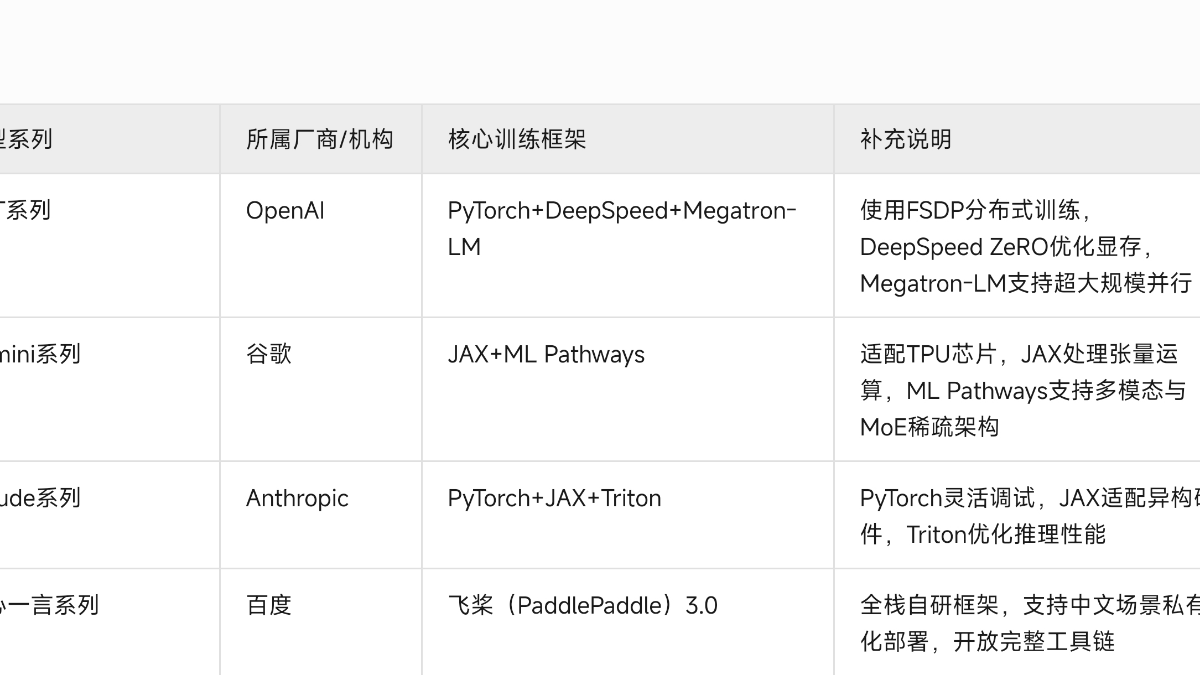
TPU难以全面取代GPGPU,而OpenAI并非转向GPGPU,反而已开始租用谷歌TPU,呈现算力多元化布局的态势,具体分析如下: 1. TPU难以取代GPGPU,二者将长期共存- TPU的局限性明显:它的生态根基远不如GPGPU,英伟达CUDA开发者社区规模是谷歌TPU生态的4倍,众多专业算法库、调试工具都围绕GPGPU优化,且TPU仅能通过谷歌云获取,绑定其云服务,多云部署时数据迁移成本高。请
}}(3)提交软件绘制结果 cpp// Surface.cpp:软件绘制后的 Buffer 提交status_t Surface::unlockAndPostSoftwareBuffer(SkBitmap* bitmap) {// 1. 将 Skia 绘制后的像素数据拷贝到 Surface 的 Buffermemcpy(mCurrentBuffer->bits(), bitmap->getPixe

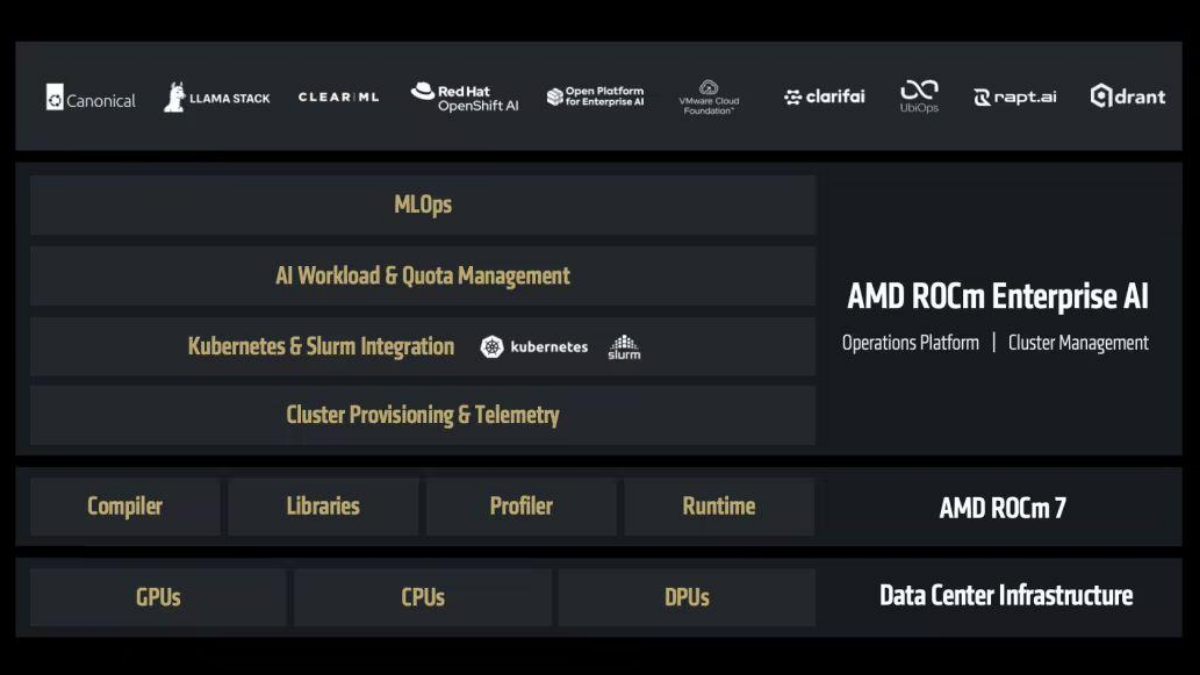
ROCm(Radeon Open Compute)是 AMD 开源的 GPU 计算平台,与 CUDA 兼容性极高,移植核心是替换 CUDA 专属 API 为 ROCm 等价接口(多数可直接替换头文件/宏定义),无需大幅改写业务逻辑。头文件替换: cuda.h / cuda_runtime.h→hip/hip_runtime.h (HIP 是 ROCm 核心接口,语法与 CUDA 几乎一致);二、完
TPU难以全面取代GPGPU,而OpenAI并非转向GPGPU,反而已开始租用谷歌TPU,呈现算力多元化布局的态势,具体分析如下: 1. TPU难以取代GPGPU,二者将长期共存- TPU的局限性明显:它的生态根基远不如GPGPU,英伟达CUDA开发者社区规模是谷歌TPU生态的4倍,众多专业算法库、调试工具都围绕GPGPU优化,且TPU仅能通过谷歌云获取,绑定其云服务,多云部署时数据迁移成本高。请
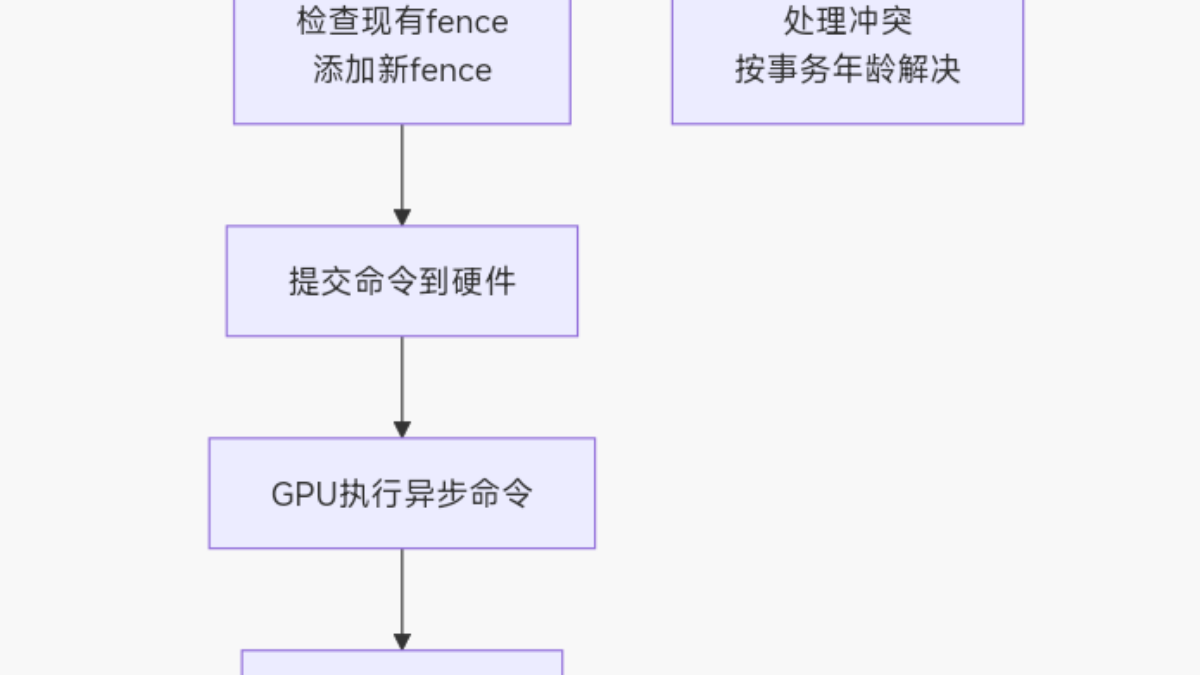
当多个进程(或事务)需要同时锁定一组缓冲区,但请求锁的顺序可能形成循环等待时(例如进程A锁了缓冲区1想锁缓冲区2,进程B锁了缓冲区2想锁缓冲区1), ww_mutex会根据事务的“年龄”(启动顺序)决定回滚(wound)较年轻的事务,让其释放已获得的锁,从而打破死锁局面,让较年长的事务先完成。在获取锁的过程中如果发生冲突,会根据事务的先后顺序(年龄)来解决:较年轻的事务(后发起者)会回退(释放已获
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained(“google/gemma-3-4b”)model = AutoModelForCausalLM.from_pretrained(“google/gemma-3-4b”, device_map=“
