
写文章




- @peterk1212
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
RTX5090 VS RTX 5080 Laptop 做大模型训练比较
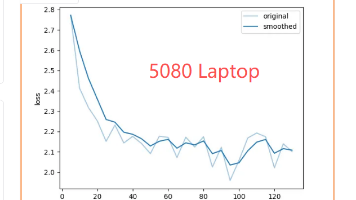
摘要:作者分享了RTX 5080笔记本(16G显存/64G内存/U9 CPU)的大模型开发使用体验。测试显示,使用lmdeploy加载7B模型时需CUDA 12.8编译包,相比vllm可节省1/3显存,但16G显存限制上下文token约5000。微调测试中,在未突破硬件上限时,5080笔记本比云端5090慢3-4倍;突破上限后预计差距达6-8倍。同时发现相同参数下,不同GPU训练效果存在差异。本文
到底了