




- @m0_37559973
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通义千问为阿里云研发的大语言系列模型。千问模型基于Transformer架构,在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在预训练模型的基础之上,使用对齐机制打造了模型的chat版本。

通义千问是由阿里云自主研发的大语言模型,用于理解和分析用户输入的自然语言,在不同领域、任务内为用户提供服务和帮助。您可以通过提供尽可能清晰详细的指令,来获取符合您预期的结果。

协议是计算机网络通信实体之间在数据交换过程中需要遵循的规则或约定,是计算机网络有序运行的重要保证。任何一个协议都会显式或隐式地定义三个基本的要素:语法、语义和时序,称为协议三要素。1)语法:语法定义实体之间交换信息的格式与结构,或者定义实体之间传输信号的电平等。2)语义:语义定义实体之间交换信息中需要包含哪些控制信息,这些信息的具体含义,以及针对不同含义的控制信息,接收信息端应如何相应。还需要定义

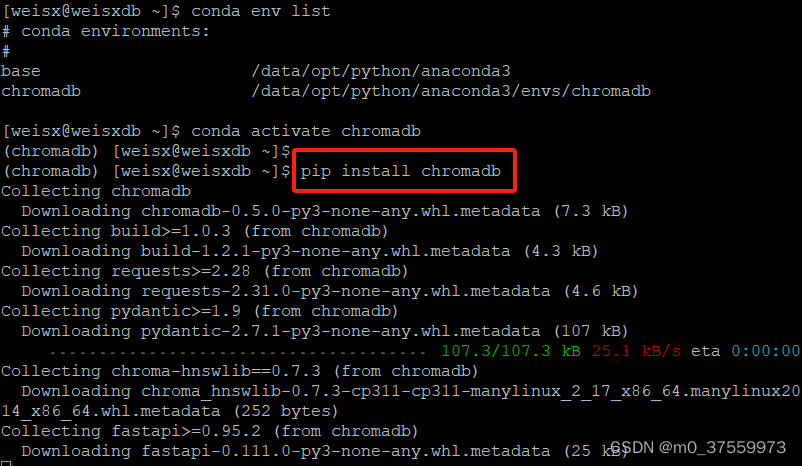
Chroma是一个开源的嵌入式数据库。Chroma通过使知识(knowledge)、事实(facts)和技能(skills)可插拔,从而简化了大型语言模型(LLM)应用程序的构建。
Doris 数据表模型上目前分为三类:DUPLICATE KEY, UNIQUE KEY, AGGREGATE KEY。因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。

pg_stat_statements是 PostgreSQL 的一个扩展,它用于收集关于执行的 SQL 语句的统计信息。这可以帮助你分析查询性能,识别慢查询,并优化数据库。

Qwen3 是 Qwen 系列最新一代的大型语言模型,提供了一套全面的密集型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面实现了突破性的进展。
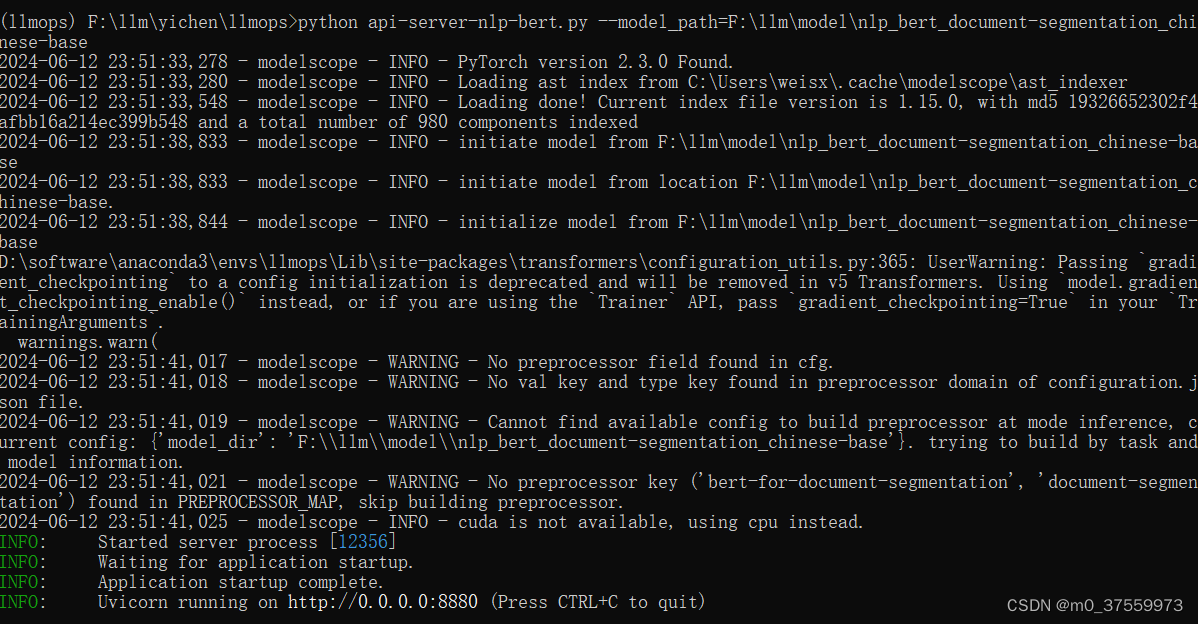
BERT文本分割-中文-通用领域(nlp_bert_document-segmentation_chinese-base),该模型基于wiki-zh公开语料训练,对未分割的长文本进行段落分割。提升未分割文本的可读性以及下游NLP任务的性能。
LLaMA-Factory 是一个开源的大语言模型(LLM)微调框架,旨在简化大规模模型的训练、微调和部署流程。它支持多种主流模型(如 LLaMA、Qwen、ChatGLM 等),提供命令行和可视化 WebUI 两种交互方式,并集成了 LoRA、QLoRA 等高效微调技术,显著降低了模型定制化的技术门槛。
LLaMA-Factory 是一个开源的大语言模型(LLM)微调框架,旨在简化大规模模型的训练、微调和部署流程。它支持多种主流模型(如 LLaMA、Qwen、ChatGLM 等),提供命令行和可视化 WebUI 两种交互方式,并集成了 LoRA、QLoRA 等高效微调技术,显著降低了模型定制化的技术门槛。