




- @liu_xue_xue
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了Claude Code的安装配置指南。系统要求包括macOS10.15+/Ubuntu18.04+/Windows10+操作系统,Node.js 18.0.0+和npm 8.0.0+。安装步骤包括全局安装@anthropic-ai/claude-code包,并提供了解决网络问题的镜像源设置方法。配置部分指导用户创建settings.json文件,设置API密钥、基础URL和模型参数
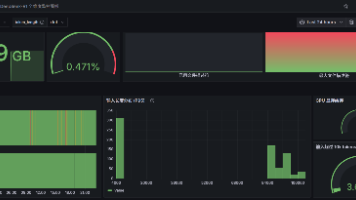
本文详细介绍了如何部署和监控deepseekr1模型。首先,通过下载模型、安装vllm并使用vllm部署deepseekr1,完成模型的安装和启动。接着,通过Prometheus进行监控配置,并利用Grafana进行可视化展示。此外,还设置了Prometheus的告警规则,包括文件描述符告警和GPU缓存压力告警,以确保系统稳定运行。最后,通过alertmanager和PrometheusAlert
摘要:本文介绍了Claude Code的安装配置指南。系统要求包括macOS10.15+/Ubuntu18.04+/Windows10+操作系统,Node.js 18.0.0+和npm 8.0.0+。安装步骤包括全局安装@anthropic-ai/claude-code包,并提供了解决网络问题的镜像源设置方法。配置部分指导用户创建settings.json文件,设置API密钥、基础URL和模型参数
摘要:工作区和对话区布局变化导致操作不习惯,可通过以下步骤还原:进入layout设置,选择Editor选项即可恢复原界面。操作简单快捷,帮助用户快速适应界面调整。(50字)
摘要:本文介绍了Claude Code的安装配置指南。系统要求包括macOS10.15+/Ubuntu18.04+/Windows10+操作系统,Node.js 18.0.0+和npm 8.0.0+。安装步骤包括全局安装@anthropic-ai/claude-code包,并提供了解决网络问题的镜像源设置方法。配置部分指导用户创建settings.json文件,设置API密钥、基础URL和模型参数
Spark Shell是一个交互式的命令行,提供了一种学习API的简单方式,以及一个能够进行交互式分析数据的强大工具,他也是一个客户端,可以使用scala编写(scala运行与Java虚拟机可以使用现有的Java库)或使用Python编写。方便学习和测试,用于提交spark应用程序。spark-shell的本质是在后台调用了spark-submit脚本来启动应用程序的。启动spark-shell,
摘要: 本文对比了6款主流Embedding模型的核心特点与适用场景: 1️⃣ BGE-M3:多语言/长文本RAG首选,支持100+语言; 2️⃣ text-embedding-3-large:英文场景精度顶尖,向量维度可调; 3️⃣ Jina-embeddings-v2:轻量化实时推理,RT<50ms; 4️⃣ xiaobu-embedding-v2:通用中文优化,适配日常检索; 5️⃣
《OpenClaw必装10大插件指南》精选10款新手必备插件:1️⃣安全检测skill-vetter;2️⃣联网搜索tavily-search;3️⃣记忆增强self-improving-agent;4️⃣办公神器gog;5️⃣开发工具github;6️⃣速读助手summarize;7️⃣知识管理ontology;8️⃣主动执行proactive-agent;9️⃣插件推荐find-skills;
《OpenClaw必装10大插件指南》精选10款新手必备插件:1️⃣安全检测skill-vetter;2️⃣联网搜索tavily-search;3️⃣记忆增强self-improving-agent;4️⃣办公神器gog;5️⃣开发工具github;6️⃣速读助手summarize;7️⃣知识管理ontology;8️⃣主动执行proactive-agent;9️⃣插件推荐find-skills;
需要客户端先退出,然后再退出认证服务中心