- @lhxcc_fly
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们将使⽤ LangChain 的来实现向量的内存存储。
tooldef add (a:int, b:int)->int: #加法工具"""两数相加Args:a : 一个整数b : 另一个整数"""# 方式二class AddInput(BaseModel): #类中定义函数描述和参数描述"""两数相加"""a: int = Field(..., description="第一个整数")#...表示必填字段b: int = Field(..., desc
传统的LLM调用返回的信息一般为字符串的文本形式,当我们想要让LLM仅返回我们想看到的信息我们就要自己设置结构化格式给LLM,让其返回我们所需的内容。在 LangChain 中,聊天模型提供了额外的功能:结构化输出。⼀种使聊天模型以结构化格式(例如 JSON)进⾏响应的技术。例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这种需求激发了结构化输出的概念,其中可以指⽰模型使⽤特定的
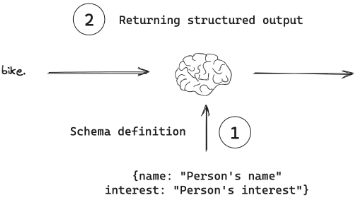
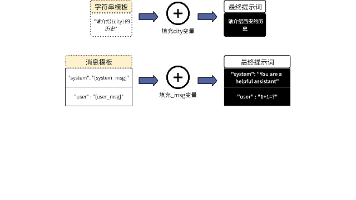
少样本提⽰是⼀种通过向 LLM 提供少量具体⽰例或样本,来教会它如何执⾏某项特定任务的技术。提⾼模型性能的最有效⽅法之⼀是给出⼀个【模型⽰例】指导⼤模型你想做什么、怎么做。
前面LangChain系列中我们或多或少都在代码中体现过输出解析结构化,今天我们系统总结其中比较常见的。
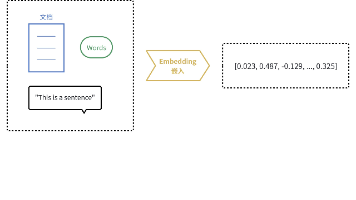
model="text-embedding-3-large", # 是 OpenAI 2024年发布的最新嵌⼊模型,⽣成3072维的⾼质量向量。
前面我们知道LangChain可以将多个组件链起来进行封装使用,当时我们提到过一个输出解析器组件StrOutputParser,它能自动从 AIMessageChunk中提取内容字段,为 我们提供模型返回的令牌。我们可以在此基础上自定义输出格式,使流式输出更符合我们的要求。sream返回的是一个迭代器,我们可以操作该迭代器进行自定义的消息块处理并输出。比如前面的案例的流式输出是一个字token输出

本文介绍了LangChain中的消息处理机制,主要包括原生LLM消息结构、LangChain统一消息格式、历史消息缓存管理以及消息的裁剪、筛选和合并操作。LangChain通过BaseMessage子类提供跨模型统一消息格式,支持多模态内容。文章详细讲解了如何使用RunnableWithMessageHistory管理对话历史,并演示了trim_messages()进行token/消息数裁剪、fi

当前对于大部分人来说我们利用LLM都是进行AI搜索来帮助我们进行知识的获取与总结。对于【AI ⼤模型】来说,它最擅⻓的是语义理解和⽂本总结,最不擅⻓的就是获取实时的信息。因为⼤模型的训练数据是有截⽌⽇期的!对于【搜索引擎】来说,它最擅⻓的就是获取实时的信息,缺点是信息分散,每次都需要⼈为进⾏总结。⼤模型与搜索引擎的结合,就是给 AI 配备了⼀个活字典,让 AI 可以随时进⾏查阅但是搜索引擎只能获取

前文我们利用构建知识库利用文档加载器将我们的本地文件等加载进来,文档加载器会对文档进行初步的拆分(PDF加载:按照PDF文档的分页进行拆分,MD加载:按照类型或者默认的方式进行拆分),但在初次拆分可能会出现同一个Q&A或者语义相近的资料被拆分为不同的子文档,这样不符合我们的期望。因此LangChain提出了文本切割器帮助我们进行文档的二次拆分。