- @jiaxin576
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
拆解字节UI-TARS核心架构,梳理出8大类核心数据格式与3阶段训练细节,普通工程师也能照做的全栈GUI Agent大模型训练指南。

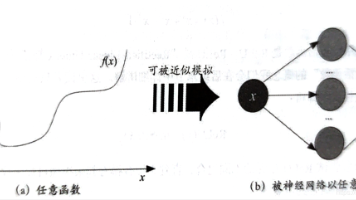
在深度学习的宏大叙事中,我们常常听到“神经网络可以拟合任意函数”的说法。但这背后的数学直觉究竟是什么?
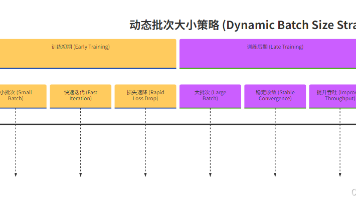
还在为“炼丹”参数发愁吗?这篇文章将带你彻底搞懂批次大小、学习率、优化器这些核心参数背后的深层逻辑。
带你亲手算一笔账,从参数量、运算量、训练时间到显存开销,彻底搞懂训练一个大模型究竟需要多少“硬通货”。
本文展示了一个完整的、生产级的AI量化分析Agent的实现过程。通过Python强大的数据处理生态(pandas, AKShare)与LLM的推理能力结合,成功将原本分散的、异构的金融数据转化为可解释的投资决策。全维度视角的自动化:机器不会疲劳,能够每周例行检查数十个维度的指标。逻辑的可解释性:相比黑盒的神经网络,LLM输出的文本逻辑让投资者敢于参考。防过拟合的设计:通过周频聚合和宏观数据对齐,最
1.LLM如Transformer架构是一种由人工“神经元”组成的层级网络:输入的文本被切分为标记(token)序列,每个token先映射为向量表示(词嵌入)输入模型。不同脑区在功能上各有分工,例如视觉处理主要在枕叶视觉皮层,听觉在颞叶听觉皮层,语言和决策涉及额叶等,各脑区之间通过神经网络协同工作,构建层次化、关联性的概念表示,从而实现整体认知。突触可塑性是大脑学习和记忆的关键机制:当某些神经

Prompt 工程很强,但替代不了「模型训练」本身。下面我们从底层视角拆开看看:Transformer 在干嘛?Prompt 在干嘛?训练在干嘛?它们的边界到底在哪里?

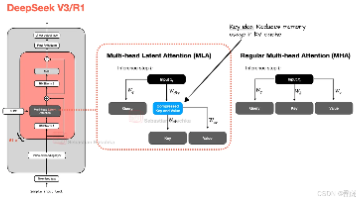
12025 年的大模型仍然是Decoder-only Transformer 主体 + 一堆结构插件主干结构没变:自回归、因果 mask、残差、归一化、注意力 + FFN。创新集中在:注意力变体(GQA、MLA、滑动窗口、线性注意力)、MoE、归一化布局、位置编码、KV cache 压缩。2MoE 已经从研究玩具变成旗舰模型标配DeepSeek-V3、Llama 4、Qwen3-MoE、GLM-4
带你亲手算一笔账,从参数量、运算量、训练时间到显存开销,彻底搞懂训练一个大模型究竟需要多少“硬通货”。
当 AI 能力狂飙到“能推理、能行动、能自我进化”时,安全不再只是“拒答”,而是一场贯穿评测、对齐、权限与监控的系统工程。