




- @gogoMark
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
的横空出世,结合AppMall的云端预部署能力,为企业提供的终极解决方案。
提起文本转语音(TTS),很多人第一反应是 “机械音”—— 要么语调僵硬像机器人,要么情绪单一撑不起内容,尤其是专业配音工具动辄几百元的会员费,让普通用户望而却步。但B 站悄悄放出的,直接颠覆了这种认知:零样本克隆声音、文本控制情绪、精准调节语速停顿,生成的语音堪比专业配音演员,关键是还能免费体验。
Step-Audio 2 mini 能成为 “开源语音天花板”,不是靠堆参数,而是靠 “架构创新 + 能力扩展”,精准解决传统模型的痛点,每一项能力都直击用户真实需求。Step-Audio 2 mini 的出现,不止是一次技术迭代,更标志着语音 AI 从 “工具级” 走向 “伙伴级”—— 它不再是 “只会转文字的机器”,而是能听懂情绪、联网查知识、用方言对话的 “智能伙伴”。对开发者来说,开源且轻
近日,阶跃星辰推出的系列模型凭借其创新的端到端架构与多项SOTA性能,为多模态语音领域注入新动能。作为开源语音大模型的重要突破,该技术不仅实现了音频理解与生成的深度融合,更在情感交互、工具调用等维度展现出惊人潜力。
阶跃星辰正式推出开源端到端语音大模型,并在国际权威评测中以多项SOTA成绩引发关注。这款模型不仅实现了语音理解、生成与推理的深度融合,更凭借对复杂声学信号的精准解析能力,为语音交互领域树立了新的标杆。
在人工智能快速发展的浪潮中,DeepSeek团队推出的DeepSeek-OCR模型正以其创新的"视觉即压缩"理念,重新定义着文档理解与多模态处理的边界。这一突破性技术不仅在OCR领域引发变革,更为大语言模型的长上下文处理提供了全新解决方案。
在人工智能领域,一场静默的革命正在发生。DeepSeek最新开源的OCR模型不仅突破了传统文字识别的边界,更提出了一个颠覆性的理念:。这一创新正引发全球AI社区的广泛关注,被誉为解决长文本处理难题的突破性方案。
在人工智能快速发展的浪潮中,DeepSeek团队再次带来突破性创新。最新开源的DeepSeek-OCR模型不仅颠覆了传统OCR技术的边界,更提出了"视觉即压缩"的革命性理念,为多模态大模型的发展开辟了全新方向。
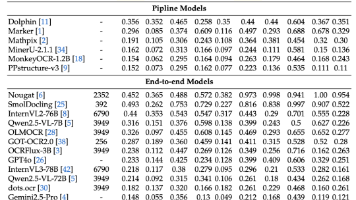
近日,DeepSeek团队推出的OCR模型在AI界引发轰动,这项技术远非简单的文字识别工具,而是一次对人工智能认知方式的根本性重塑。
在人工智能领域,一场静悄悄的革命正在发生。DeepSeek团队最新推出的OCR技术,并非传统意义上的文字识别工具,而是一种突破性的"视觉压缩"范式,正在重新定义AI处理信息的方式。