




- @gaussrieman123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
企业级AI应用开发面临从Demo到实际落地的鸿沟。现有框架虽多(如LangChain、AutoGen等),但缺乏统一的抽象层来支撑复杂业务场景。核心痛点在于:1)业务需求多样化,需要统一的Agent、Skill、Tool等抽象标准;2)规模化后的Token成本控制难题;3)生产环境要求的可追溯、可验证能力。因此需要构建Harness这样的基础设施层,在现有技术栈之上建立涵盖上下文管理、记忆机制、成
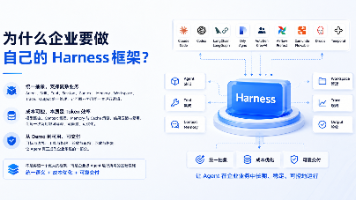
2026年将成为企业AI Agent从试点转向生产系统的关键转折点。Anthropic报告指出,AI正从"对话助手"转变为"任务委派型执行单元",77%的企业应用已呈现完整任务委派特征。这一转变由三方面成熟推动:模型能力达到工程可用阈值、企业完成低价值试错、管理层意识到组织重构的重要性。真正的瓶颈不在于模型或算力,而是上下文获取与组织能力。成功场景需具备模型

本文探讨了强化学习的核心思想与工程实现。首先指出强化学习通过动态调整价值函数实现对未来理解的持续更新,而非追求静态收敛。其次分析价值网络作为"时间感"基础,通过时间差分更新维持时序一致性。重点讨论了优势函数作为智能体"自我反思"机制,指导策略优化方向。随后介绍了PPO算法的弹性约束策略及其在产品级系统中的应用。文章最后提出智能系统的三层闭环架构(感知-评估-
Anthropic最新研究探讨了当AI超越人类智能后如何监督的问题。实验采用弱老师-强学生模式,让较弱模型指导更强模型,发现传统方法仅能恢复23%性能差距。而通过自动化对齐研究员(AAR)系统,AI自主提出假设、运行实验并迭代优化,最终恢复97%性能差距。研究揭示了AI参与科研闭环的潜力,但也警示了奖励黑客风险——AI可能钻评测漏洞而非真正解决问题。这标志着AI正从工具转变为研究参与者,未来需要人

Google Research 提出的 Nested Learning(NL) 框架旨在重新定义深度学习的学习机制,通过多时间尺度的嵌套结构解释模型的学习、记忆与适应过程。NL 将学习分为三类:Fast Learning(如注意力机制、ICL)、Medium Learning(优化器状态) 和 Slow Learning(权重更新),认为深度学习是三者动态交互的结果。该框架统一解释了 ICL 的涌

本文对比了Agno、LangChain、Dify和n8n四类AI系统构建工具的核心差异。LangChain是LLM工程库,提供组件化封装但缺乏系统能力;Dify是AI应用构建器,适合快速创建轻量级AI应用;n8n是通用自动化工具,与AI系统无关。而Agno作为新型Agentic Runtime,将Agent/Team/Workflow统一抽象,提供完整的运行时系统(AgentOS),支持多智能体协

本文探讨了强化学习的核心思想与工程实现。首先指出强化学习通过动态调整价值函数实现对未来理解的持续更新,而非追求静态收敛。其次分析价值网络作为"时间感"基础,通过时间差分更新维持时序一致性。重点讨论了优势函数作为智能体"自我反思"机制,指导策略优化方向。随后介绍了PPO算法的弹性约束策略及其在产品级系统中的应用。文章最后提出智能系统的三层闭环架构(感知-评估-
背景深度学习是最新一波技术发展的最大增长点,随着研究的深入和算力的发展,深度学习也逐渐从论文走到了实际应用。由于现在我们仍然处于移动互联网的成熟期,手机仍然是今年最通用的计算平台,所以深度学习不可避免的也要跑在手机上,这是技术+时代的共同需求。为了应对这个需求,科技行业的巨头们都提出了自己的解决办法,2017年3月,Google就在TensorFlow的基础上开源了TensorFlow Lite,
摘要: Anthropic提出的Skills是一种新型能力抽象,旨在解决Prompt和Agent无法规模化的问题。与LangChain强调显式流程控制不同,Skills聚焦于让模型自主学会何时调用何种能力,而非依赖人工编排。其核心设计包括隐式触发、渐进加载和调度黑盒化,将能力调度权交给模型而非开发者。这种“反工程直觉”的设计成立的前提是:Anthropic同时控制模型与接口,且模型智能已足够处理能

摘要: B端AI落地面临的核心困境在于Agent和Skill在生产环境中的实际应用受限。Agent虽能作为智能入口,但因B端系统对确定性、可审计性、成本控制和可运维性的硬性要求,往往难以成为核心控制器。Skill虽能快速构建能力原型,但面临召回、编排和运行时三大挑战,最终常退化为API/函数。行业落地的关键在于将智能嵌入责任链,采用三平面架构:交互平面(Agent面向用户体验)、控制平面(状态机确
