- @dicky_zhang3
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
按设备能力分协议。电池供电、低带宽设备用CoAP;常规联网设备用MQTT;需要实时双向通信的用WebSocket。不要为了统一而统一——协议的取舍直接体现在设备的电池寿命和运维成本上。Broker集群的瓶颈永远在操作系统层面。连接数到百万级别后,瓶颈不是EMQX的处理能力,而是内核的TCP栈。sysctl参数调优和文件描述符上限是最容易被忽视的坑。设备影子不是可选的锦上添花,而是必需的抽象层。
大家好,我是迪哥。2023 年我们把 Spring Cloud Netflix 全套换成了 Spring Cloud Alibaba,稳定性提升了 50%,运维成本降了 60%。今天就聊聊,Nacos、Sentinel、Seata 这三剑客,如何撑起我们的百万级电商系统。
/ 自定义配置定义CRD:使用kubebuilder定义自定义资源实现Controller:编写Reconcile逻辑处理状态:更新资源状态测试验证:单元测试和集成测试部署分发:构建镜像和ChartOperator模式是管理复杂应用的最佳实践,通过声明式API提供一致的管理体验。
Knative是一个基于Kubernetes的Serverless平台,提供自动扩缩容、事件驱动等能力。
系统层面数据(CPU、内存、QPS)事件层面数据(请求、报错)请求层面数据(调用链路、耗时分布)不要追求完美!先把指标和日志搞起来,链路可以慢慢加数据保留策略!不要无限期存,成本扛不住告警要收敛!太多告警会导致告警疲劳定期检查!有没有漏采集,有没有异常指标没人看与业务结合!不仅看系统指标,更要看业务指标(下单量、支付成功率)说到可观测性,我家那只叫 Docker 的哈士奇最近在监视我的零食柜,什么
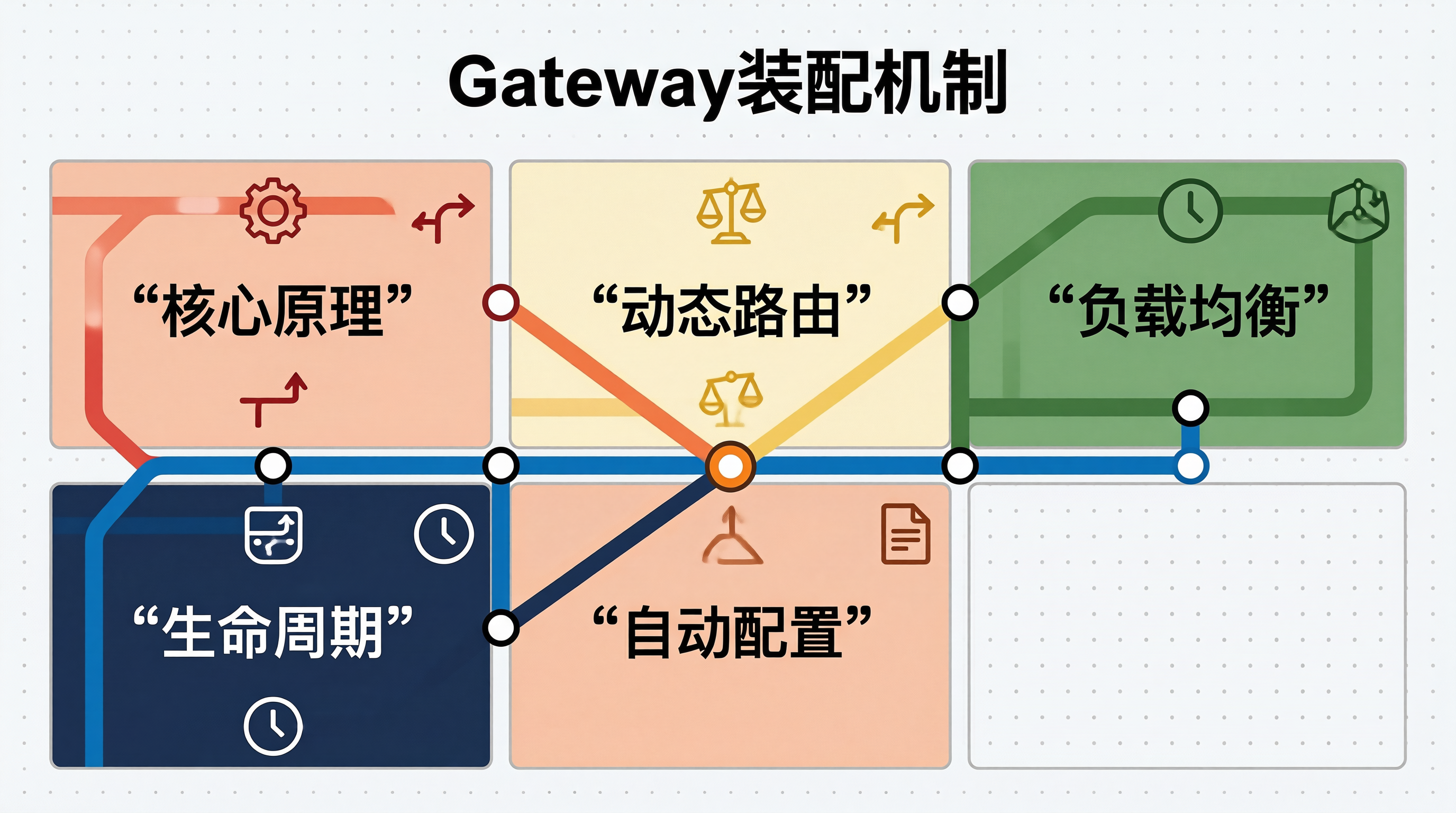
sum();@Component@Override// 使用Redis进行用户级别的限流if (!// 基于Redis的滑动窗口限流实现Spring Cloud Gateway的动态路由与负载均衡组件的生命周期装配机制,本质上是Spring Boot自动配置体系在网关领域的一次精妙实践。从到,从到,每个组件都在恰当的时机被创建、注入和激活。
Spring Cloud Gateway的高频请求流量清洗与过载防护,需要构建多层防御体系。本文从令牌桶限流、熔断降级、IP流量清洗、请求体SQL注入过滤、动态规则配置等维度,给出了完整的实践方案。结合Seata分布式事务的场景,在Gateway层增加事务过载防护,可以有效防止大量并发全局事务压垮TC协调器。通过Nacos配置中心动态管理限流规则,实现了防护能力的灵活调整。这套方案已在多个日活千万
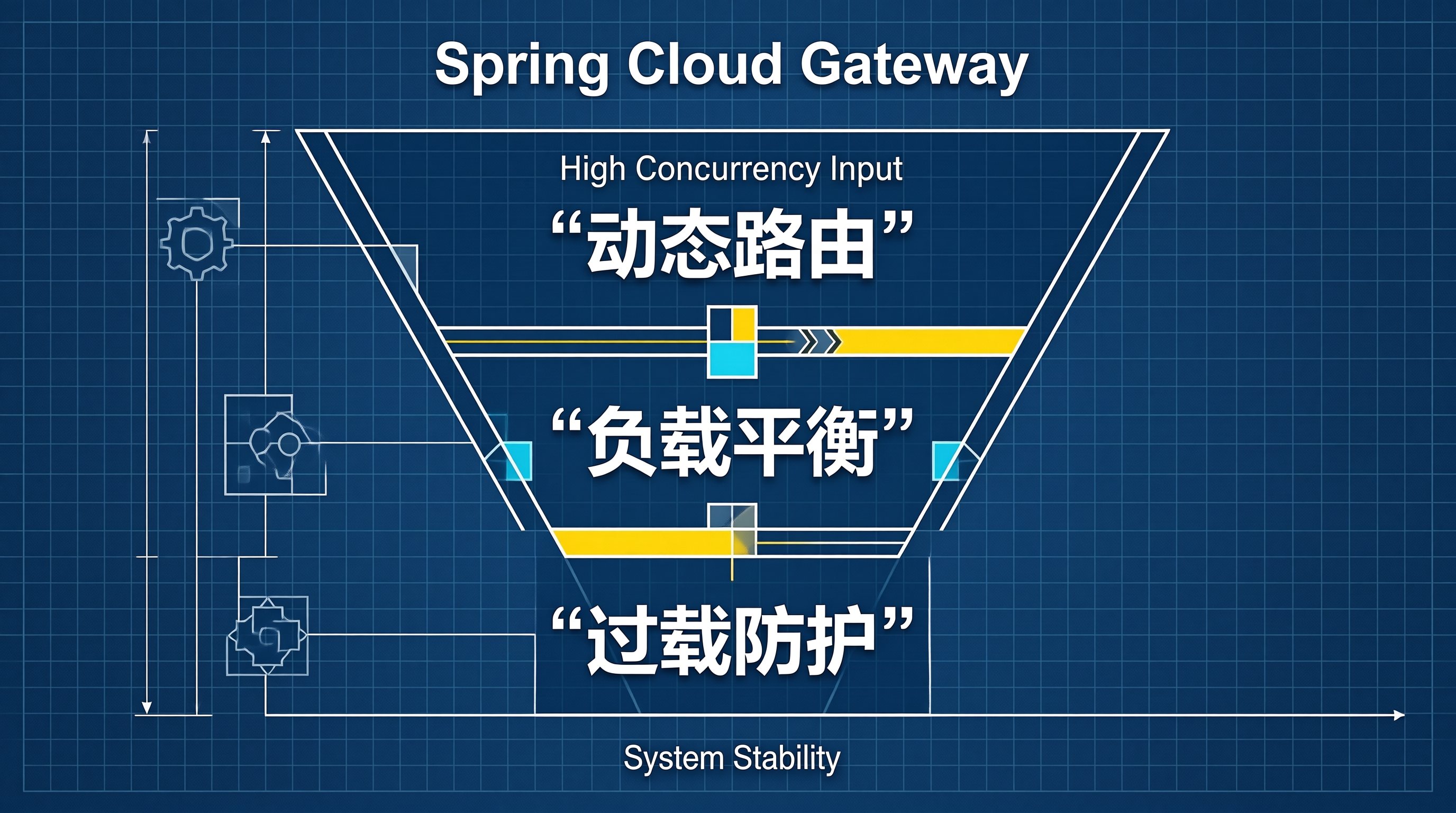
高并发场景下,Spring Cloud Gateway的动态路由、负载均衡与过载防护三者必须联动配合才能发挥最大效能。动态路由需要节流保护防止配置风暴,负载均衡需要自适应评分实现智能调度,过载防护需要全局协调实现优雅降级。本文通过自适应负载均衡器、路由刷新节流器、过载保护管理器、优雅降级Filter等组件,构建了一套完整的流量治理体系。这套方案的关键在于"感知-决策-执行"的闭环——实时感知实例状
Gateway + Nacos的服务注册与发现在高并发场景下,流量清洗的核心在于三个层面:实例层面的元数据过滤剔除异常节点、推送层面的节流保护防止缓存雪崩、负载均衡层面的动态权重实现自适应调度。通过Nacos的元数据机制和Gateway的自定义负载均衡策略,可以实现灰度发布、同城优先、权重自适应等高级流量治理能力。在高并发生产环境中,配合推送节流和本地缓存兜底机制,能够确保Nacos的任何抖动都不
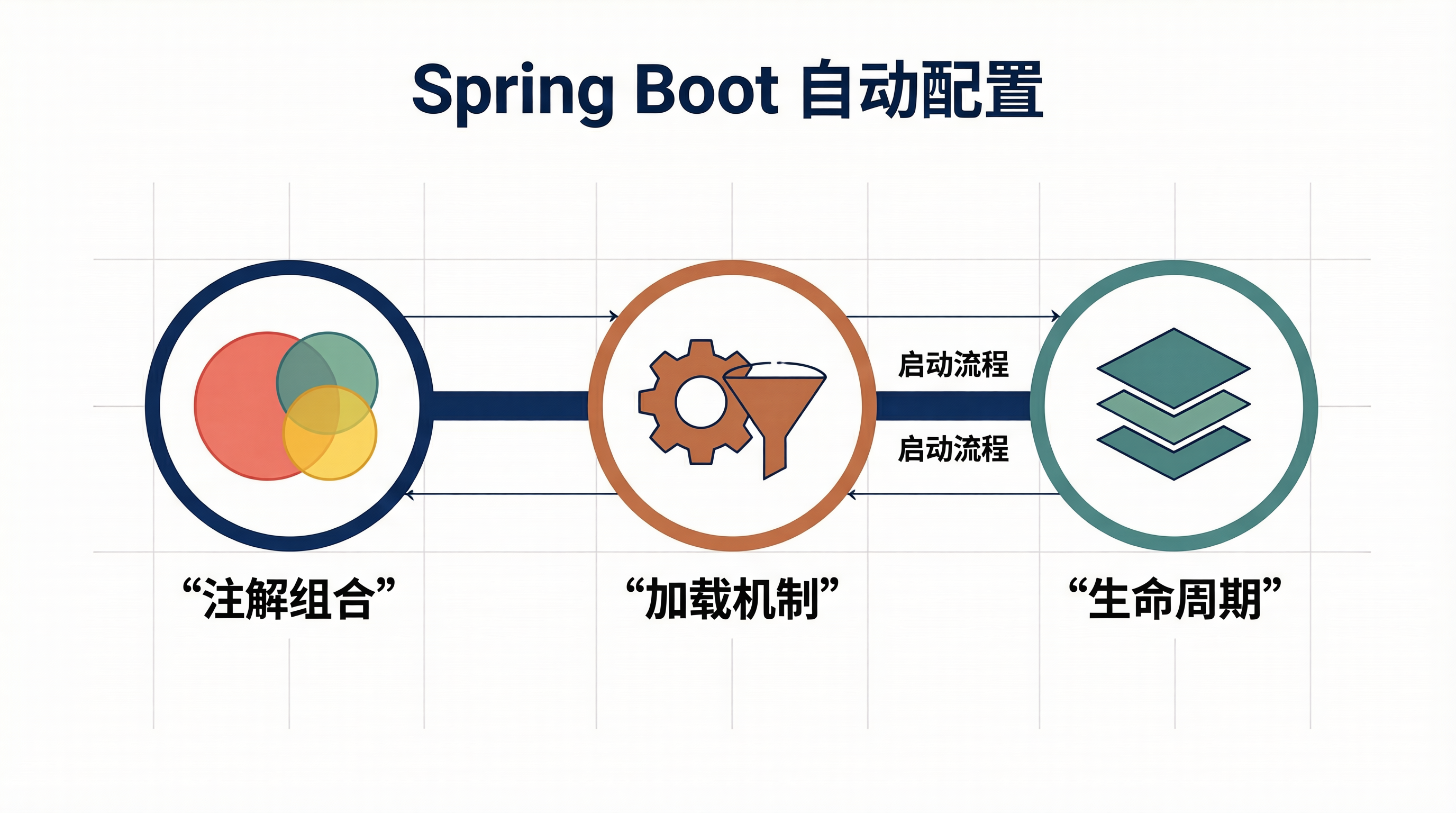
OverrideSystem.out.printf("请求 %s 耗时 %dms%n",Spring Boot自动配置的核心机制是"条件评估 + 延迟导入 + 排序装配"的三位一体设计。通过开启、加载、系类注解精细控制,实现了高度可扩展的配置体系。条件决定了配置是否生效,排序决定了配置的加载顺序,绑定决定了外部化配置如何注入。